PyG的Planetoid无法直接下载Cora等数据集的3个解决方式
诸神缄默不语-个人CSDN博文目录
本文仅考虑DNS污染情况下无法用torch_geometric.Planetoid类下载Cora等数据集的情况。其他使用GitHub仓库下载数据的解决方式类似,在此文中不再赘述。
三个解决问题的方式方式简介:
- 修改raw.githubcontent.com在hosts中对应的IP地址,使本地电脑可以直接登上该网站
- 直接将原始数据下载到本地:手动从GitHub或gitee下载数据,放到对应文件目录位置;或者用Python拉数据下来
- 修改torch_geometric源代码
以下是对这些解决方式的详细介绍(仅以Cora为例,其他数据集类似,不再赘述)
文章目录
- 解决方式一:修改hosts文件
- 解决方式二:从GitHub或gitee拉数据
-
- 方法1:直接下载整个项目
- 方法2:直接下载所需的单个文件
-
- 1. 直接从网页下载
- 2. 用Python下载
- 3. 用wget下载
- 解决方式三:直接修改PyG源码
- 参考资料
如果顺利的话,应该只需要执行类似这样的代码即可在对应根目录位置下载数据集:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./tmp/cora', name='Cora')
Planetoid文档:https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html#torch_geometric.datasets.Planetoid
在planetoid源代码中可以看到,这个类的大致逻辑就是从GitHub下载数据→处理数据。出现无法下载的情况时可能是由于Planetoid从raw.githubcontent.com这个域名下载数据,而这个域名在电脑上被DNS污染。
本文仅考虑这种情况造成的无法下载情况。如果您发现您的机子没有这种问题,那么您可能无法通过本文的手段解决对应的问题。
测试是否是DNS污染的简单方式:ping一下raw.github.com
(仅适用于Windows系统,Linux等其他系统类似)使用 Win + R,出现如下弹窗:
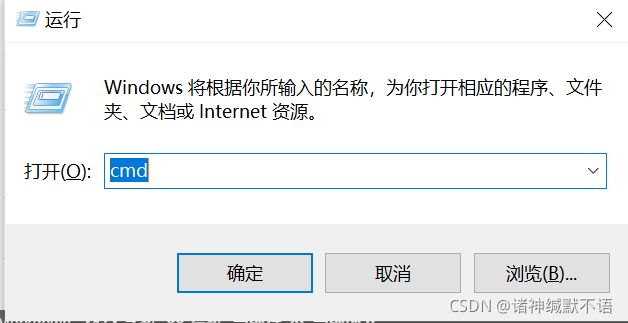
在输入框中输入 cmd,点击确定,出现shell窗口,输入 ping raw.githubcontent.com,回车运行。
如果ping包能接收到,说明不是DNS污染的问题,一般可以通过多试几次的方式来解决问题,如果还解决不了那我也不知道了;如果ping包接收不到,说明就是DNS污染的问题,见下文。
解决方式一:修改hosts文件
可以通过多个地点Ping服务器,网站测速 - 站长工具这个网站获取raw.githubcontent.com对应的IP地址,选一个响应时间较短而且在大陆的响应IP就行。然后修改hosts,就可以直接下载。
(此处找IP地址还可以用The Best IP Address, Email and Networking Tools - IPAddress.com这个网站,但是这个网站有的时候会突然上不了,所以作为备选提供)
2022.12.13能用的IP地址:
173.208.96.46
直接挂代理一般也可以解决问题。
我之所以没这么干是因为我用远程服务器跑的,我没法改DNS也没法挂代理……
修改hosts的方法:
- 找到hosts文件的位置,Windows一般为
C:\Windows\System32\drivers\etc - 打开hosts文件(用记事本之类的文本编辑器都行),在最后加一行,写你刚刚挑好的IP地址,然后按 tab 键,然后写
raw.githubusercontent.com。 - 保存文件。如果不能保存就把内容复制到另一个同名文本文件中,复制过来,直接覆盖。
- 在前文提及的cmd窗口中运行
ipconfig /flushdns。
解决方式二:从GitHub或gitee拉数据
GitHub项目是https://github.com/kimiyoung/planetoid,gitee项目是https://gitee.com/jiajiewu/planetoid。gitee的话在国内会更快点,所以推荐用gitee的。
具体需要的数据是这些:
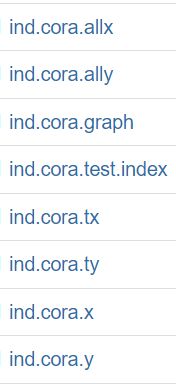
通过以下任一方法下载到需要的数据后,将其放到根目录下Cora/raw文件夹下,然后再运行dataset = Planetoid(root, name='Cora')。如无报错并显示如下输出则成功。
Processing…
Done!
Cora()
方法1:直接下载整个项目
可以直接把整个项目git clone下来,然后直接从里面把对应的文件复制过去。
git clone的方法可参考我之前写的博文:VSCode上的Git使用手记(持续更新ing…)
也可以直接从项目的网页下载项目的zip压缩包,跟git clone地址在差不多的位置。
方法2:直接下载所需的单个文件
1. 直接从网页下载
gitee可以直接在网页上下载单个文件。直接修改网址也可以下载单个文件,具体网址见下面用Python下载数据部分。
要额外注意:PubMed里面的allx文件可能因为文件太大,所以如果直接用Gitee远程拉的话会要求登录,如果没有登录就会重定向到网页,导致无法用这种方式下载数据。
解决方法,我暂时也没有解决方法……就这一个文件就从本地登录了下载下来然后上传到服务器就算了。
GitHub通过插件或者修改网址也可以下载单个文件,但是如果你能通过这种方式下载文件,你的DNS应该没有被污染。
2. 用Python下载
直接把这个网址输到浏览器里面也能下载就是了……
我使用的是这个方式。主要原因是我在服务器上跑的项目,直接把所有事都在Python代码里解决就会比较方便。
base_url参数:
推荐使用gitee的:https://gitee.com/jiajiewu/planetoid/raw/master/data/ind.cora.
github的话可以二选一:https://github.com/kimiyoung/planetoid/raw/master/data/ind.cora.或 https://raw.githubusercontent.com/kimiyoung/planetoid/master/data/ind.cora.(但问题在于如果你能从这两个网址拉数据……那你……就不应该有不能下载的问题)
注意,这里要通过raw下载数据,如果直接用网页下载数据(如https://gitee.com/jiajiewu/planetoid/blob/master/data/ind.cora.allx)的话就会下载成网页……我一开始就下载成了网页……这肯定是会报错的。要下数据文件。
可以尝试使用PyG的download_url()方法下载数据(这是源代码中使用的方式)。其文档地址。
我使用的是requests。别的方式应该也行,就各种直接下载网页文件的方式应该都行。我这里给一个代码:
import requests
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
for name in names:
file_url=base_url+name
r=requests.get(file_url)
with open('./tmp/cora/Cora/raw/ind.cora.'+name, 'wb') as f:
f.write(r.content)
3. 用wget下载
其实我推荐用wget下载,因为有输出。太简单我就不写了,这还不会百度怎么上的学。网址还是上面那个网址。
如果稍稍对电脑有一点多的了解,还可以用Python写个批处理的bat或sh文件。
解决方式三:直接修改PyG源码
把planetoid.py里面第48行的 url = 'https://github.com/kimiyoung/planetoid/raw/master/data' 改成 url='https://gitee.com/jiajiewu/planetoid/raw/master/data'
逻辑上就跟第二种解决方式里面从gitee拉数据一样。
参考资料
- 【PyG学习入门】二:入门时遇到的问题
- Cora数据集不能下载
- 用torch_geometric无法下载Cora数据怎么办?
- torch_geometric下载数据集Cora时报错
- 修改 Hosts 解决 Github 访问失败马克 - 知乎