D基础_VOC2007 解析
VOC 数据集解析 VOC2007 解析
VOC 数据是 PASCAL VOC Challenge 用到的数据集,官网
这里以常用的 VOC2007 数据集 作为代表来讲解一下 VOC 数据集
1. 下载数据

官网:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html
训练集/验证集:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
DevKit:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
带有标记的测试集:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
这里说明一下,VOC 官方给出的数据集中,只有 VOC2007 是给出了带有标记的测试集的
其他年份的数据集是没有 Anotated test data 的
那么下载完成后得到如下压缩包:
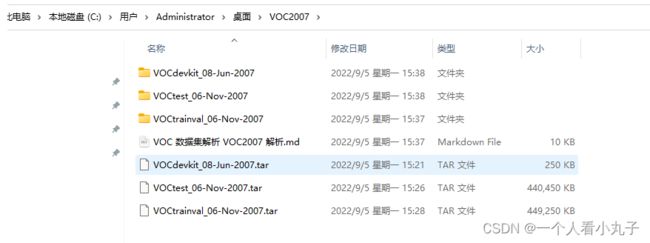
分开来讲这三个包:
2. VOCdevikit:
其实就是 development kit code and documentation ,开发工具包代码和文档,换句话说就是怎么做出这个数据集的一些代码,和关于此数据集的说明书.解压后如下:
VOCdevkit_08-Jun-2007
得到一个 VOCdevkit,再打开里面:
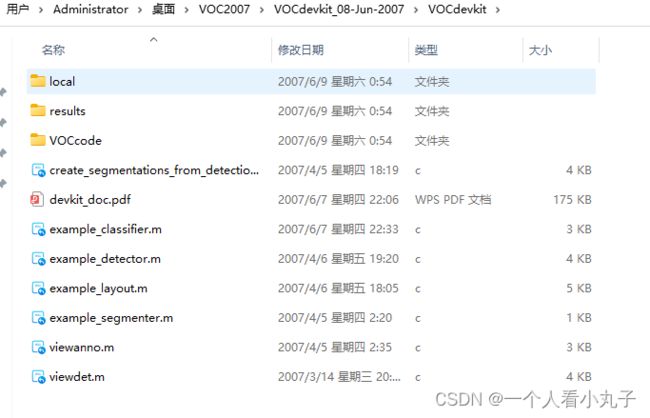
如图所示,就是一些 MATLAB 代码,就是用这些代码处理的这个数据集,基本上没什么用,唯一可以看看的就是那个 devkit_doc.pdf, 就是 一个比较详细的说明书,有兴趣可以自己看看,比较细.
总结起来,这个压缩包对于我们使用数据 并没有什么用…,因为真正的图片并没有装在这里面,所以其实可下可不下;
3、VOCtrainval_06-Nov-2007,
这就是我们的训练集和验证集,解压后如下:
VOCtrainval_06-Nov-2007
同样也是一个 VOCdevkit,然后打开
里面便是 VOC2007,再点开,就得到 5 个文件夹:
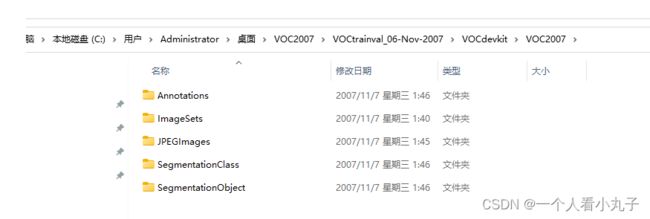
这就是我们需要搞清楚的 5 个文件夹了,
A. Annotations
字面意思,就是标注信息,打开之后全是 xml 文件,文件名就是图像名称,
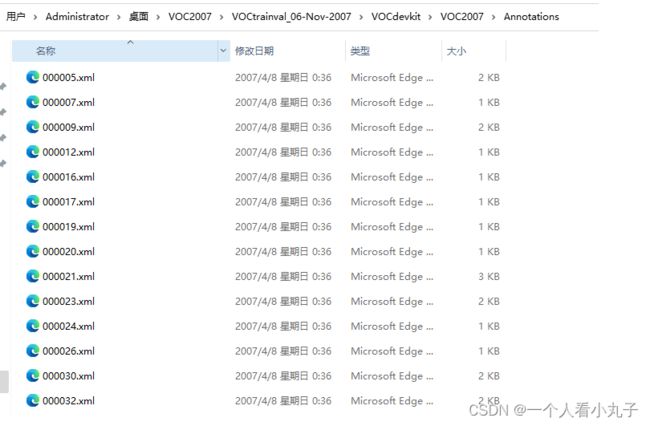
每个文件里面有该图片的一些标注信息,训练时要用的 label 信息其实就来源于此文件夹
<annotation>
<folder>VOC2007folder>
<filename>000005.jpgfilename>
<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
<flickrid>325991873flickrid>
source>
<owner>
<flickrid>archintent louisvilleflickrid>
<name>?name>
owner>
<size>
<width>500width>
<height>375height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>chairname>
<pose>Rearpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>263xmin>
<ymin>211ymin>
<xmax>324xmax>
<ymax>339ymax>
bndbox>
object>
<object>
<name>chairname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>165xmin>
<ymin>264ymin>
<xmax>253xmax>
<ymax>372ymax>
bndbox>
object>
<object>
<name>chairname>
<pose>Unspecifiedpose>
<truncated>1truncated>
<difficult>1difficult>
<bndbox>
<xmin>5xmin>
<ymin>244ymin>
<xmax>67xmax>
<ymax>374ymax>
bndbox>
object>
<object>
<name>chairname>
<pose>Unspecifiedpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>241xmin>
<ymin>194ymin>
<xmax>295xmax>
<ymax>299ymax>
bndbox>
object>
<object>
<name>chairname>
<pose>Unspecifiedpose>
<truncated>1truncated>
<difficult>1difficult>
<bndbox>
<xmin>277xmin>
<ymin>186ymin>
<xmax>312xmax>
<ymax>220ymax>
bndbox>
object>
annotation>
B.ImageSets
这个文件夹值得好好看一下,从名称可以猜到,这个是文件夹是 图像集合 ,
点开之后有 3 个文件夹:Layout 、 Main、 Segmentation
为什么会有 3 个文件夹呢,这其实对应的是 VOC challenge 3 类不同的任务!!!
VOC challenge 的 Main task,其实是 classification 和 detection,
所以在 Main 文件夹中,包含的就是这两个任务要用到的图像集合!
此外还有两个 taster tasks :Layout 和 Segmentation,
这两个任务 也有各自需要用到的图像,就分别存于两个文件夹中
所以这 3 个文件夹中包含的是 3 类不同的任务需要用到的不同的图片集合
我们可以点开看一看,比如点开 Layout,会有 train.txt 、trainval.txt 、val.txt:
点开 Segmentation,也有 train.txt 、trainval.txt、 val.txt:

这三个文本文档中,写的是图像的 ID 号码 ,
train 表示的是训练集,val 表示的是验证集, trainval 是把前两者写到了一起,
Main 文件夹单独讲一下:
如图,打开之后有很多文本文档,一共有 63 个,这 63 个怎么来的呢?
首先你可以从中找到 train.txt、 trainval.txt、 val.txt 这 3 个,就如同前面两个文件夹一样,这三个文本文档肯定是有的,意思也是一样的.
还有 20 个是怎么来的?那就是 20 个类:
• person
• bird, cat, cow, dog, horse, sheep
• aeroplane, bicycle, boat, bus, car, motorbike, train
• bottle, chair, dining table, pottedplant, sofa, tv/monitor
一共 20 个类别,每个类别有该类的 类别名_train.txt 类别名__trainval.txt 类别名___val.txt 这 3 个文本,则 20 x 3 = 60,
加上上面的 3 个,就是 63 个文本文档.
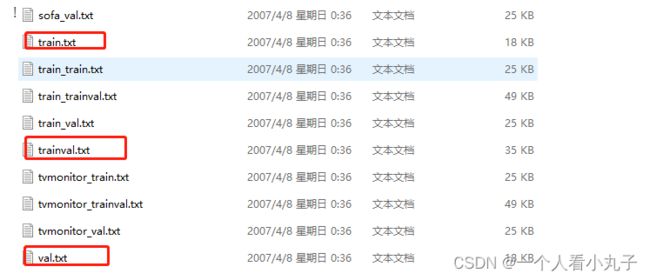
注意一点,这里面有三个文本文档名字是:train_train.txt 、train_trainval.txt 、train_val.txt,
下划线前面的 train 是 ‘火车’, 下划线后面的 train 才是‘训练’,千万不要混到一起了
然后打开这些子类的文本文档的时候,会稍显不同,
比如打开 **aeroplane_train.txt (飞机)**和 bicycle_train.txt ( 自行车)和 train.txt,
你会发现它们都有 2501 行,是说此任务训练集图片共有 2501 个

只不过 aeroplane_train.txt 和 bicycle_train.txt 每一行的图像 ID 后面 还跟了一个数字,
要么是 -1, 要么是 1,有时候也可能会 出现 0.
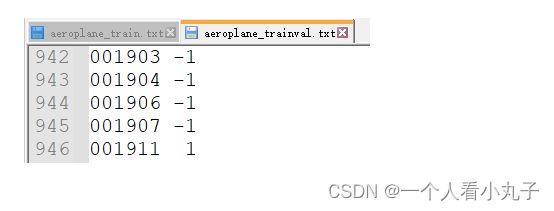
意义如下:
-1 表示当前图像中,没有该类物体;
1 表示当前图像中有该类物体;
0 的话,我看了几张标 0 的图像,似乎是说当前图像中,该类物体只露出了一部分.
所以我们在做训练时,读取图像的时候,其实就是先从这个 ImageSets 文件夹中,找到对应任务的子文件夹,
然后读取其中 txt 文本文档的图像 ID 号码 , 按照这个 ID 号码去找图像,从哪儿找呢?就在下一个文件夹中:
C、JPEGImages
字面意思,就是装的图片,点开之后全是 jpg 图片,
ImageSets 中文本文档记录的图像编号的所有图片,都装在这一个文件夹中了,
所以我们要先通过读取不同文本中的图像 ID(因为不同任务的需求),然后才来根据 ID 在这 JPEGImages 读取实体图像.
共有 5011 张个图像.
D、SegmentationClass
这个图像中装的是专门为 Segmentation 任务做的一个文件夹,里面存放的是 Segmentation 任务的 label 信息,
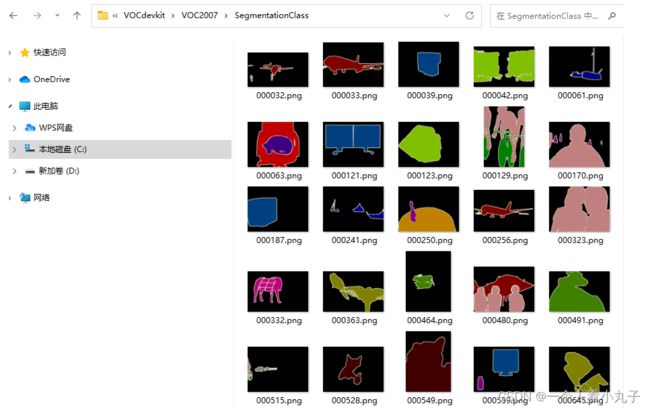
就是那些花花绿绿的图片.因为 Segmentation 的 label 是需要每个像素点有一个 label,
这个东西就不方便记录在 Annotations 文件夹中的 xml 文件中,更方便用同样大小的图像来记录 label,每个点有一个类别信息,
你会发现该文件夹中的图片共有 422 张,而 Imagesets 文件夹中,Segmentation 文件夹中的 trainval.txt 文档,也有 422 行.
这就对上号了.
实际上该文件夹中的图像的像素点上应该是 0、1、2、…、20 这些像素值才对,是一副灰度图.
但很明显这些像素值太低了,肉眼其实看不见什么,所以它就把这些数字转换成了较大的像素值,且是 3 通道的像素值,这样肉眼就方便观看,每一类(或者说每一个灰度图上的数字)对应的是同一种颜色.
这个东西叫做 colormap,那么是怎么样的对应关系呢?
很明显,这个就需要去 VOCdevkit_08-Jun-2007 里面找咯,那里面有创建这个数据集的所有代码
VOCdevkit_08-Jun-2007\VOCdevkit\VOCcode 中的 VOClabelcolormap.m 文件,其实就是干的这个事儿,
其实这个 VOCcode 文件夹里面的 m 文件还挺有意思的,还有各个任务的评价准则,比如那几个 VOCeval 文件,我以前还不知道 VOC 文件夹里面就写的有
E、SegmentationObject
这个其实现在管这个任务叫做 Instance Segmentation,样例分割,
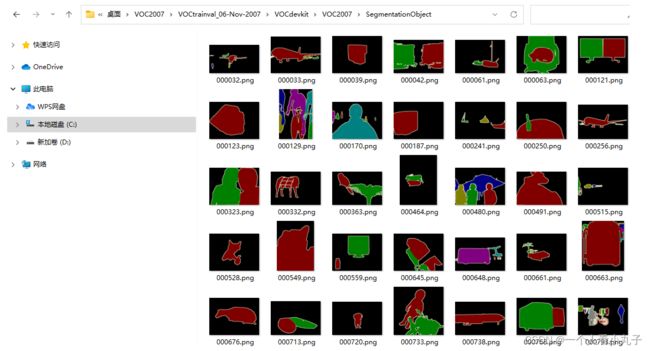
就同一图像中的同一类别的不同个体要分别标出来,也是单独给的 label 信息,因为每个像素点要有一个 label 信息
至此,VOCtrainval_06-Nov-2007 文件夹就解析完毕了
4、VOCtest_06-Nov-2007
其实这个文件夹可以比照着 trainval 那个文件夹来理解,两个的结构是完全一样的,最里面也是 5 个文件夹:

所以其实解压的时候,往往是把他俩直接解压到同一个地方,然后相同名字的文件夹会合并在一起,
这个 VOCtest_06-Nov-2007 和 VOCtrainval_06-Nov-2007
唯一不同的就是 这里装得是 test data,即测试用的图像,及其相关的 annotations,所以不再赘述
这里再次重申,再官网上,只有 2007 年时给了 Annotated test data 的,其余年份即使能下载到 test data 也应该是没有 Annotation 标注信息的,
然后真的不想再解释什么叫 train 、val 、test 了
转载于:
https://cloud.tencent.com/developer/article/1557486