Spark系列之Spark安装部署
title: Spark系列
第二章 Spark安装部署
2.1 版本选择
下载地址:
https://archive.apache.org/dist/spark
四大主要版本
Spark-0.X
Spark-1.X(主要Spark-1.3和Spark-1.6)
Spark-2.X(最新Spark-2.4.8)
Spark-3.x(最新3.2.0)
在我们自己使用的版本中使用的是,可以和我们前面使用到的hadoop3.2.2版本匹配。
spark-3.1.2-bin-hadoop3.2.tgz

2.2 Scala安装
三台节点上面都要配置
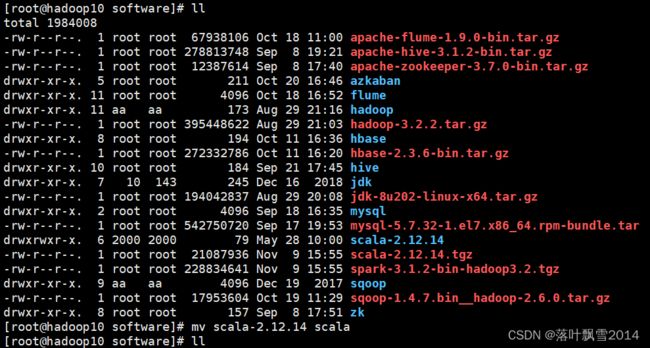
2.2.1 上传解压重命名
[root@hadoop10 software]# tar -zxvf scala-2.12.14.tgz
[root@hadoop10 software]# mv scala-2.12.14 scala
[root@hadoop10 software]# ll
total 1984008
-rw-r--r--. 1 root root 67938106 Oct 18 11:00 apache-flume-1.9.0-bin.tar.gz
-rw-r--r--. 1 root root 278813748 Sep 8 19:21 apache-hive-3.1.2-bin.tar.gz
-rw-r--r--. 1 root root 12387614 Sep 8 17:40 apache-zookeeper-3.7.0-bin.tar.gz
drwxr-xr-x. 5 root root 211 Oct 20 16:46 azkaban
drwxr-xr-x. 11 root root 4096 Oct 18 16:52 flume
drwxr-xr-x. 11 aa aa 173 Aug 29 21:16 hadoop
-rw-r--r--. 1 root root 395448622 Aug 29 21:03 hadoop-3.2.2.tar.gz
drwxr-xr-x. 8 root root 194 Oct 11 16:36 hbase
-rw-r--r--. 1 root root 272332786 Oct 11 16:20 hbase-2.3.6-bin.tar.gz
drwxr-xr-x. 10 root root 184 Sep 21 17:45 hive
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk
-rw-r--r--. 1 root root 194042837 Aug 29 20:08 jdk-8u202-linux-x64.tar.gz
drwxr-xr-x. 2 root root 4096 Sep 18 16:35 mysql
-rw-r--r--. 1 root root 542750720 Sep 17 19:53 mysql-5.7.32-1.el7.x86_64.rpm-bundle.tar
drwxrwxr-x. 6 2000 2000 79 May 28 10:00 scala
-rw-r--r--. 1 root root 21087936 Nov 9 15:55 scala-2.12.14.tgz
-rw-r--r--. 1 root root 228834641 Nov 9 15:55 spark-3.1.2-bin-hadoop3.2.tgz
drwxr-xr-x. 9 aa aa 4096 Dec 19 2017 sqoop
-rw-r--r--. 1 root root 17953604 Oct 19 11:29 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
drwxr-xr-x. 8 root root 157 Sep 8 17:51 zk
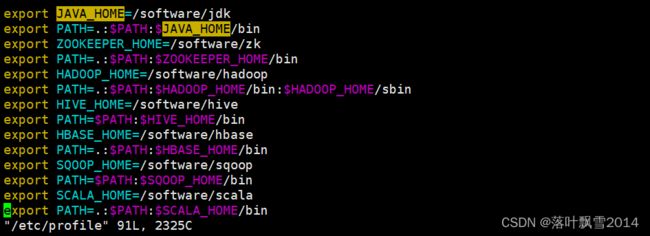
2.2.2 配置环境变量
export SCALA_HOME=/software/scala
export PATH=.:$PATH:$SCALA_HOME/bin

2.2.3 验证
[root@hadoop10 software]# source /etc/profile
[root@hadoop10 software]# scala -version
Scala code runner version 2.12.14 -- Copyright 2002-2021, LAMP/EPFL and Lightbend, Inc.
[root@hadoop10 software]# scala
Welcome to Scala 2.12.14 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202).
Type in expressions for evaluation. Or try :help.
scala> 6+6
res0: Int = 12
scala>

2.2.4 三个节点都是要安装
分发到其他的节点上面
scp -r /software/scala hadoop11:/software/
scp -r /software/scala hadoop12:/software/
然后再去对应的节点上面配置环境变量即可。
export SCALA_HOME=/software/scala
export PATH=.:$PATH:$SCALA_HOME/bin
记得source一下
[root@hadoop12 software]# source /etc/profile
2.3 Spark安装
集群规划
hadoop10: master
hadoop11: worker/slave
hadoop12: worker/slave
2.3.1 下载
下载地址
https://archive.apache.org/dist/spark/spark-3.1.2/
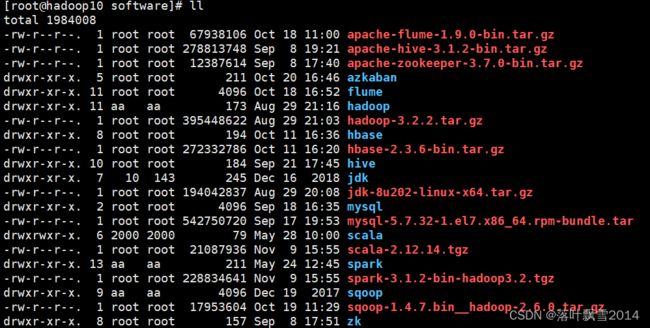
2.3.2 上传解压重命名
[root@hadoop10 software]# tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
[root@hadoop10 software]# mv spark-3.1.2-bin-hadoop3.2 spark
2.3.3 修改配置文件
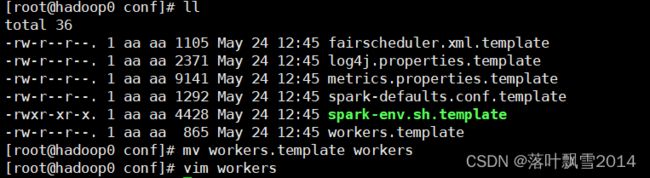
1、配置slaves/workers
进入配置目录
cd /software/spark/conf
修改配置文件名称
[root@hadoop0 conf]# mv workers.template workers
vim workers
内容如下:
hadoop11
hadoop12

2、配置master
进入配置目录
cd /software/spark/conf
修改配置文件名称
mv spark-env.sh.template spark-env.sh
修改配置文件
vim spark-env.sh
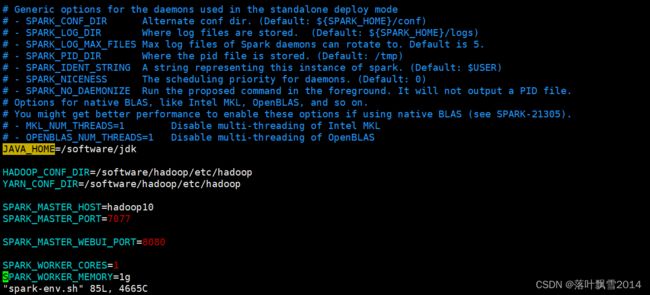
增加如下内容:
## 设置JAVA安装目录
JAVA_HOME=/software/jdk
## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上
HADOOP_CONF_DIR=/software/hadoop/etc/hadoop
YARN_CONF_DIR=/software/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
SPARK_MASTER_HOST=hadoop10
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
如下图:
2.3.4 分发到其他节点上面
scp -r /software/spark hadoop11:/software/
scp -r /software/spark hadoop12:/software/
2.3.5 启动与停止
在主节点上启动spark集群
cd /software/spark/sbin
start-all.sh

/software/spark/sbin/start-all.sh
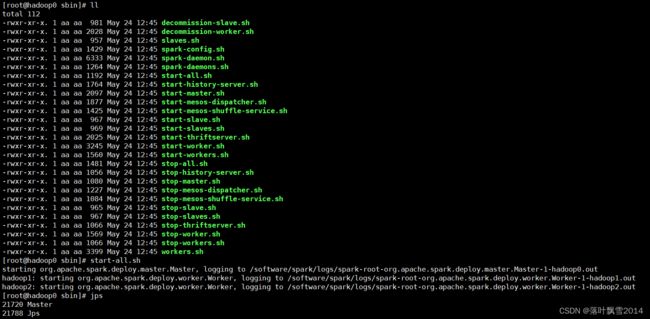
各个节点上面的进程:
[root@hadoop0 sbin]# jps
21720 Master
21788 Jps
[root@hadoop1 software]# jps
66960 Worker
67031 Jps
[root@hadoop2 software]# jps
17061 Jps
16989 Worker
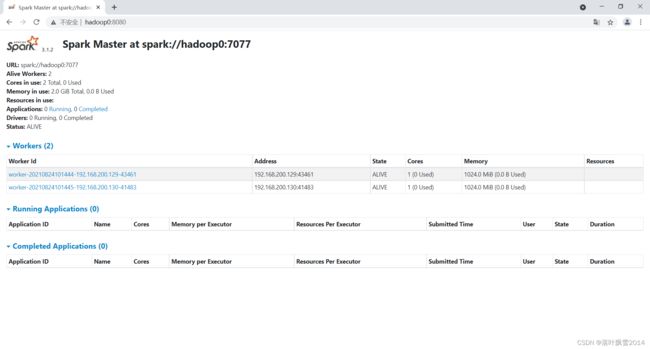
查看页面:
在主节点上停止spark集群
/software/spark/sbin/stop-all.sh

在主节点上单独启动和停止Master:
start-master.sh
stop-master.sh
在从节点上单独启动和停止Workers(Worker指的是slaves配置文件中的主机名)
start-workers.sh
stop-workers.sh
2.3.6 运行个求PI的例子
[root@hadoop10 bin]# cd /software/spark/bin/
[root@hadoop10 bin]# pwd
/software/spark/bin
[root@hadoop10 bin]# run-example SparkPi 10
前面有好多日志
......
2021-11-09 16:21:27,969 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9) (hadoop10, executor driver, partition 9, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
2021-11-09 16:21:27,972 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 140 ms on hadoop10 (executor driver) (8/10)
2021-11-09 16:21:27,982 INFO executor.Executor: Running task 9.0 in stage 0.0 (TID 9)
2021-11-09 16:21:28,009 INFO executor.Executor: Finished task 8.0 in stage 0.0 (TID 8). 957 bytes result sent to driver
2021-11-09 16:21:28,016 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 74 ms on hadoop10 (executor driver) (9/10)
2021-11-09 16:21:28,035 INFO executor.Executor: Finished task 9.0 in stage 0.0 (TID 9). 957 bytes result sent to driver
2021-11-09 16:21:28,037 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 68 ms on hadoop10 (executor driver) (10/10)
2021-11-09 16:21:28,039 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
2021-11-09 16:21:28,047 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 1.121 s
2021-11-09 16:21:28,054 INFO scheduler.DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
2021-11-09 16:21:28,055 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
2021-11-09 16:21:28,058 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.262871 s
Pi is roughly 3.1433951433951433
2021-11-09 16:21:28,130 INFO server.AbstractConnector: Stopped Spark@777c9dc9{HTTP/1.1, (http/1.1)}{0.0.0.0:4040}
2021-11-09 16:21:28,131 INFO ui.SparkUI: Stopped Spark web UI at http://hadoop10:4040
2021-11-09 16:21:28,165 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2021-11-09 16:21:28,333 INFO memory.MemoryStore: MemoryStore cleared
2021-11-09 16:21:28,333 INFO storage.BlockManager: BlockManager stopped
2021-11-09 16:21:28,341 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2021-11-09 16:21:28,343 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2021-11-09 16:21:28,355 INFO spark.SparkContext: Successfully stopped SparkContext
2021-11-09 16:21:28,397 INFO util.ShutdownHookManager: Shutdown hook called
2021-11-09 16:21:28,397 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-d4aeb352-14b7-4e72-ada7-e66b45192bc5
2021-11-09 16:21:28,402 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-000896f1-04df-45a1-81be-969838a25457


2.3.7 运行个WordCount的例子
2.3.7.1 spark-shell 本地模式
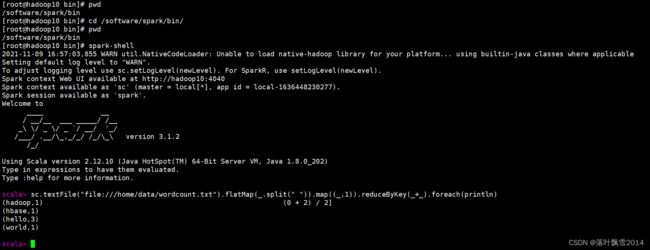
[root@hadoop10 bin]# cd /software/spark/bin/
[root@hadoop10 bin]# pwd
/software/spark/bin
[root@hadoop10 bin]# spark-shell
2021-11-09 16:57:03,855 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = local[*], app id = local-1636448230277).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("file:///home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
(hadoop,1) (0 + 2) / 2]
(hbase,1)
(hello,3)
(world,1)
scala>
2.3.7.2 Spark集群模式
这种集群模式需要先启动Spark集群。

在/software/spark/bin 目录下面运行下面的命令
./spark-shell \
--master spark://hadoop10:7077 \
--executor-memory 512m \
--total-executor-cores 1
完整过程如下:
[root@hadoop10 bin]# pwd
/software/spark/bin
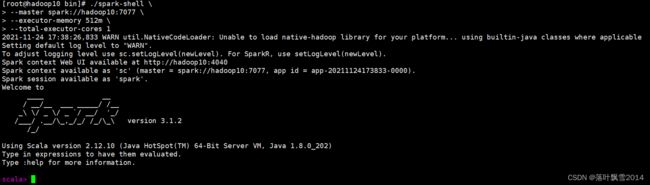
[root@hadoop10 bin]# ./spark-shell \
> --master spark://hadoop10:7077 \
> --executor-memory 512m \
> --total-executor-cores 1
2021-11-09 17:00:13,074 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = spark://hadoop10:7077, app id = app-20211109170018-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
2.3.7.3 Spark集群模式下FileNotFoundException问题及解决方案
遇到错误了,错误如下:
scala> sc.textFile("file:///home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
2021-11-09 17:01:07,431 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0) (192.168.22.137 executor 0): java.io.FileNotFoundException: File file:/home/data/wordcount.txt does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:666)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:987)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:656)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:454)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.(ChecksumFileSystem.java:146)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:347)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:899)
at org.apache.hadoop.mapred.LineRecordReader.(LineRecordReader.java:109)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:286)
at org.apache.spark.rdd.HadoopRDD$$anon$1.(HadoopRDD.scala:285)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:243)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:96)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2021-11-09 17:01:07,586 ERROR scheduler.TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting job
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 6) (192.168.22.137 executor 0): java.io.FileNotFoundException: File file:/home/data/wordcount.txt does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:666)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:987)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:656)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:454)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.(ChecksumFileSystem.java:146)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:347)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:899)
at org.apache.hadoop.mapred.LineRecordReader.(LineRecordReader.java:109)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:286)
at org.apache.spark.rdd.HadoopRDD$$anon$1.(HadoopRDD.scala:285)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:243)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:96)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2258)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2207)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2206)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2206)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1079)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1079)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1079)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2445)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2387)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2376)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:868)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2196)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2217)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2236)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2261)
at org.apache.spark.rdd.RDD.$anonfun$foreach$1(RDD.scala:1012)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.foreach(RDD.scala:1010)
... 47 elided
Caused by: java.io.FileNotFoundException: File file:/home/data/wordcount.txt does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:666)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:987)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:656)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:454)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.(ChecksumFileSystem.java:146)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:347)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:899)
at org.apache.hadoop.mapred.LineRecordReader.(LineRecordReader.java:109)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:286)
at org.apache.spark.rdd.HadoopRDD$$anon$1.(HadoopRDD.scala:285)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:243)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:96)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
scala>

解决方案:
1、看看执行语句
./spark-shell \
--master spark://hadoop10:7077 \
--executor-memory 512m \
--total-executor-cores 1
这个里面有需要一个executor的cores
2、去三个节点上面去看进程
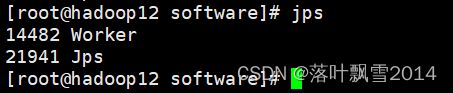
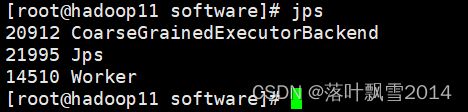
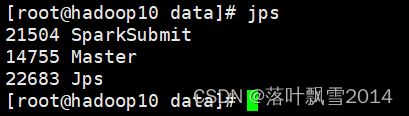
发现在hadoop11上面多了一个进程CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend是什么呢?
我们知道Executor负责计算任务,即执行task,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的。
3、总结
在spark-shell里执行textFile方法时,如果total-executor-cores设置为N,哪N台机有CoarseGrainedExecutorBackend进程的,读取的文件需要在这N台机都存在。
4、那我们去hadoop11上给这个路径的文件创建一下
[root@hadoop10 data]# scp /home/data/wordcount.txt hadoop11:/home/data/
wordcount.txt 100% 37 7.9KB/s 00:00
[root@hadoop10 data]#
5、再次执行
scala> sc.textFile("file:///home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
scala> sc.textFile("file:///home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
res2: Array[(String, Int)] = Array((hello,3), (world,1), (hadoop,1), (hbase,1))
scala>

参考: https://www.cnblogs.com/dummyly/p/10000421.html
2.3.8 再运行一个hdfs上面的WordCount例子试试
2.3.8.1 spark-shell 本地模式
[root@hadoop10 bin]# pwd
/software/spark/bin
[root@hadoop10 bin]# spark-shell
2021-11-09 17:29:58,238 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = local[*], app id = local-1636450204011).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("hdfs://hadoop10:8020/home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
(hadoop,1) (0 + 2) / 2]
(hbase,1)
(hello,3)
(world,1)
scala> sc.textFile("hdfs://hadoop10/home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
(hadoop,1)
(hbase,1)
(hello,3)
(world,1)
scala>
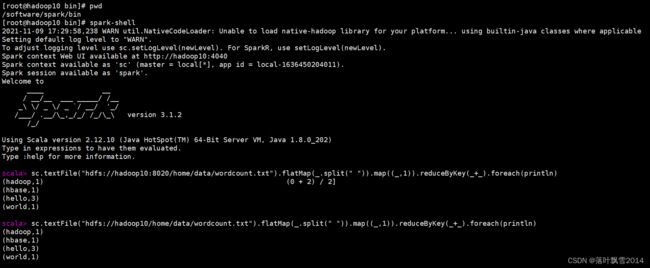
2.3.8.2 Spark集群模式
[root@hadoop10 bin]# ./spark-shell \
> --master spark://hadoop10:7077 \
> --executor-memory 512m \
> --total-executor-cores 1
2021-11-09 17:31:27,690 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = spark://hadoop10:7077, app id = app-20211109173133-0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> sc.textFile("hdfs://hadoop10:8020/home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
res0: Array[(String, Int)] = Array((hello,3), (world,1), (hadoop,1), (hbase,1))
scala> sc.textFile("hdfs://hadoop10/home/data/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
res1: Array[(String, Int)] = Array((hello,3), (world,1), (hadoop,1), (hbase,1))
scala>

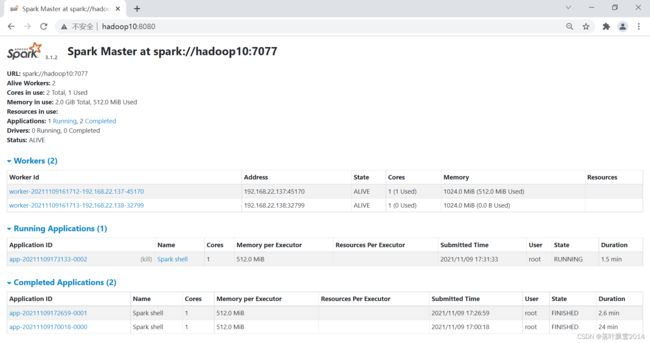
2.9 再去页面中看看运行的历史任务
会发现有一些历史的运行状态。
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接