shell数组
文章目录
- 一.数组的总括
-
- 1.数组的作用
- 2.数组的应用场景
- 3.创建定义数组的方法
- 二.数组的场景类型及数据类型
-
- 1.数组包括的数据类型
- 2.获取数组长度
- 3.读取下标索引的值
- 4.数组的遍历
- 5.数组的切片
- 6.数组替换
- 三.删除数组
-
- 1.整个数组删除
- 2.删除数组的指定值
- 四.追加数组中的元素
- 五.通过数组给函数传参
- 六.从函数返回数组
- 七.数组排序算法
-
- 1.冒泡排序
- 2.冒泡排序的基本思想
- 3.算法思路
- 八.拓展
一.数组的总括
1.数组的作用
一次性定义多个变量,给大量的变量赋值
2.数组的应用场景
(1)获取数组长度
(2)获取元素长度
(3)遍历元素
(4)元素切片
(5)元素替换
(6)元素删除
总:对数组的增删改查
3.创建定义数组的方法
方法一:
数组名=(value0 value1 value2…)
举例:
zjf=(1 2 3 4 5)
echo ${zjf[*]}
1 2 3 4 5
方法二:
数组名=( [0]=value [1]=value [2]=value …)
举例:
zjf1=([0]=1 [1]=2 [2]=3)
echo ${zjf1[*]}
1 2 3
二.数组的场景类型及数据类型
1.数组包括的数据类型
(1)数值类型
(2)字符类型:值可以换成字符串
数值与字符可以相互混写
zjf2=(11 22 33 qq ww ee)
echo ${zjf2[*]}
11 22 33 qq ww ee
2.获取数组长度
相当于数组中有多少个元素
zjf3=(1 2 3 4 5)
echo ${#zjf3[*]}
5
3.读取下标索引的值
从0开始排序,0获取的是第一个元素
zjf4=(1 2 3 4 5)
echo ${zjf4[3]}
4——————————第三个元素是4
echo ${zjf4[1]}
2——————————第一个元素是2
4.数组的遍历
将数组中的元素列出来就叫数组遍历
vim szbl.sh
user=(zzz xxx ccc)
for i in ${user[*]}
do
useradd $i
echo 12345 | passwd --stdin $i
done
chmod 777 szbl.sh

5.数组的切片
取数组中的某一段的元素的值
zjf=(1 2 3 4 5 6 )
echo ${zjf[*]:0:2}————————第0索引开始往后2位包括自己
1 2
echo ${zjf[*]:2:2}——————第一个:后的数字表示索引下标的第几位第二个:后表示从索引号开始第几个
3 4
6.数组替换
临时替换或者永久替换
格式:
$(数组名[@或*]/查找字符/替换字符}
(1)临时替换
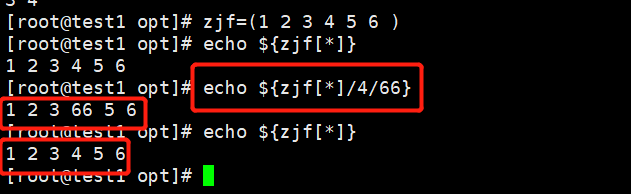
(2)永久替换


三.删除数组
1.整个数组删除
使用unset删除数组
格式:unset+数组名称
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TtRzRpOh-1685608871346)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601151938281.png)]](http://img.e-com-net.com/image/info8/82d78bdced0c4bc08440671645ca594e.png)
2.删除数组的指定值
根据索引下标删除

四.追加数组中的元素
当想要在数组中原有的元素后面再追加一些元素的话,可以使用如下方法实现追加
方法一:
数组名[下标]=添加的值
索引下标方式追加条件,索引下标是第几位,添加的就是第几位上的值

方法二:
数组名[${#数组名[*]}]=添加值
直接在数组添加后面等于所想添加的值
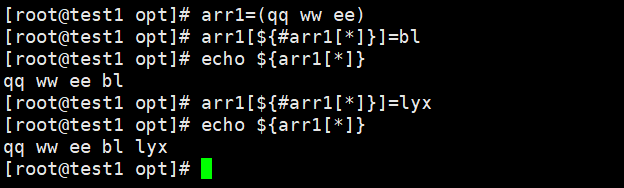
方法三:
数组名+=(添加的值 添加的值)

五.通过数组给函数传参
如果将数组变量作为函数参数,函数只会取数组变量的第一个值。
#!/bin/bash
hanshu () {
abc1=($(echo $@))——————————将变量拆开单独一个一个传
echo "数组的值为:${abc1[*]}"
}
abc=(`seq 1 10`)————————abc的范围1-10
hanshu ${abc[*]}————————abc的数值给hanshu赋值给abc1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mrlgC5ql-1685608871348)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601161308575.png)]](http://img.e-com-net.com/image/info8/e903e7fdfa63421d9be5ade0b568800b.png)
六.从函数返回数组
调用新数组的元素进行函数运算
例:
(1)加法传参运算
test () {
abc1=(`echo $@`)
sum=0
for i in ${abc1[*]}
do
sum=$(($sum+$i))
done
echo "$sum"
}
abc=(1 2 3 4 5)
test ${abc[*]}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7P5aC4fb-1685608871348)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601105457376.png)]](http://img.e-com-net.com/image/info8/8db5605b3b6a490abb9b3c8f64c5f982.png)
通过索引下标的方式来获取替换的值
(2)求数组每一个值都乘以2,打印出数组
#!/bin/bash
hanshu () {
abc1=($(echo $@))
for ((i=0;i<=$(($#-1));i++))-----是原始数组的元素个数,这里是取出新数组的索引值,不减的话就是一个字符串
do
abc1[$i]=$((${abc1[$i]}*2))------这里是将每个原始索引对应的元素值乘以2传到新的数组中对应的索引的元素中去
done
done
echo "${abc1[*]}"---------输出新的数组
}
abc=(1 2 3 4 5 6)
hanshu ${abc[*]}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xGv7NgwX-1685608871348)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601162019408.png)]](http://img.e-com-net.com/image/info8/e2cbd14842b641dda085bc63393c5a27.png)
七.数组排序算法
1.冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
2.冒泡排序的基本思想
冒泡排序的基本思想是对比相邻的两个元素值,
如果满足条件就交换元素值,把较小的元素移动到数组前面,
把大的元素移动到数组后面(也就是交换两个元素的位置) ,
这样较小的元素就像气泡一样从底部上升到顶部
3.算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,
同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
在实际应用中,冒泡排序适用于对小规模数据进行排序。
#冒泡排序
abc=(20 10 60 40 50 70) #定义一个数组
len=${#abc[*]} #定义原数组的长度为length变量
for ((i=1;i<$len;i++)) #定义排序轮次
do
for ((k=0;k<$len-1;k++)) #确定第一个元素的索引位置
do
first=${abc[k]} #定义第一个元素的值
j=$(($k+1)) #定义第二个元素的索引号
second=${abc[$j]} #定义第二个元素的值
if [ $first -gt $second ] #第一个元素和第二个元素比较,如果第一个元素比第二个元素大则互换
then
temp=$first #把第一个元素的值保存在临时变量temp中20 10
abc[$k]=$second #把第二个元素的值赋给第一个元素
abc[$j]=$temp #把原第一个元素的值,赋给第二个元素
fi
done
done
echo ${abc[*]} #输出排序后的数组
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tgJxkqhK-1685608871348)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601120536431.png)]](http://img.e-com-net.com/image/info8/d9dfb7faa9044f89bb9bd95759443a75.png)
八.拓展
使用df -h命令,对磁盘空间从大到小做正向排序

df -h | awk ‘NR>1 {print $5}’——————切出磁盘使用率
df -h | awk ‘NR>1 {print $5}’ | tr -d “%”——————切除%号
abc=($(df -h | awk ‘NR>1 {print $5}’ | tr -d “%”)) #定义一个数组
[root@test1 opt]# vim tz.sh
abc=(`df -h | awk 'NR>1 {print $5}' | tr -d "%"`) #定义一个数组
len=${#abc[*]} #定义原数组的长度为length变量
for ((i=1;i<$len;i++)) #定义排序轮次
do
for ((k=0;k<$len-1;k++)) #确定第一个元素的索引位置
do
first=${abc[k]} #定义第一个元素的值
j=$(($k+1)) #定义第二个元素的索引号
second=${abc[$j]} #定义第二个元素的值
if [ $second -gt $first ] #第一个元素和第二个元素比较,如果第一个元素比第二个元素大>则互换
then
temp=$first #把第一个元素的值保存在临时变量temp中20 10
abc[$k]=$second #把第二个元素的值赋给第一个元素
abc[$j]=$temp #把原第一个元素的值,赋给第二个元素
fi
done
done
echo ${abc[*]} #输出排序后的数组
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NzL534SS-1685608871349)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230601163916061.png)]
nd=${abc[$j]} #定义第二个元素的值
if [ $second -gt $first ] #第一个元素和第二个元素比较,如果第一个元素比第二个元素大>则互换
then
temp=$first #把第一个元素的值保存在临时变量temp中20 10
abc[$k]=$second #把第二个元素的值赋给第一个元素
abc[$j]=$temp #把原第一个元素的值,赋给第二个元素
fi
done
done
echo ${abc[*]} #输出排序后的数组
![[外链图片转存中...(img-NzL534SS-1685608871349)]](http://img.e-com-net.com/image/info8/e0ca4e404cdb4ca0b8056e4fcf039da9.png)