【AIGC】13、GLIP | 首次将 object detection 重建为 phrase grounding 任务

文章目录
-
- 一、背景
- 二、方法
-
- 2.1 将 object detection 和 phrase grounding 进行统一
- 2.2 Language-aware deep fusion
- 2.3 使用语义丰富的数据来进行预训练
- 三、效果
-
- 3.1 迁移到现有 Benchmarks
- 3.2 在 COCO 上进行零样本和有监督的迁移
- 3.3 在 LVIS 上进行零样本迁移学习
- 3.4 在 Flickr30K Entities 上进行 phrase grounding 验证
- 3.5 分析
- 3.6 自然环境中的目标检测
- 3.7 如何将一个模型扩展到所有任务
论文:Grounded Language-Image Pre-training
代码:https://github.com/microsoft/GLIP
出处:微软 | 华盛顿大学
时间:2022.06
一、背景
视觉识别模型一般都使用提前设定的类别来进行训练,这会限制器在真实场景中的使用
CLIP 方法证明了 image-level 的视觉特征表达能够很好的学习大量的 image-text pairs
其 text 中包含很丰富的视觉概念,pre-trained CLIP 模型语义非常丰富,能够很好的泛化到下游的 zero-shot 图像分类、图文检索
为了更细粒度的对图像理解,目标检测、分割、姿态估计、场景理解等 object-level 的任务也非常重要。
本文的重点:
- 展示了 phrase grounding(可以理解为将短语和目标区域进行关联)任务,能够实现短语和目标/区域之间的关联
- 提出了 Grounded Language-Image Pre-training(GLIP),在目标检测任务中实现了对 phrase grounding 和 object detection 任务的统一

二、方法
GLIP 主要内容如下:
1、将 object detection 任务重建为 phrase grounding
如何重建任务:
- 将检测模型的输入从图像变为图像和 text Prompt(prompt 包括该检测任务中所有候选类别)
- 示例: COCO 目标检测任务的 text prompt 是一个 text str,包含 80 个 phrase,使用 ‘.’ 进行 phrase 的切分,如图 2 左侧所示。
- 任何一个 object detection model 都可以被转换为 grounding model,实现方式是将 object classification logits 替换为 object box classifier,比如可以使用 region(or box) visual features 和 token (or phrase)language feature 的点积,如图 2 右侧所示
- language feature:使用 language model 来计算得到,不同于 CLIP 只在最后一个 dot product layer 将 vision 和 language 进行融合,GLIP 结构中 vision 和 language 的融合更加深入(如图 2 中间部分),这有助于学习更高质量的 language-aware visual representation,达到更好的迁移学习效果
detection 和 grounding 任务统一有什么好处:能够同时利用两个任务的数据并且互利互惠
- 在 detection 上,grounding data 能帮助其提升视觉概念的丰富性
- 在 grounding 上,detection data 能够引入更多 bounding box 标注信息

2、使用大量的 image-text data 扩充视觉概念
假设有一个很好的 grounding model(teacher),则可以为这些大量的 image-text-paired 数据自动生成 grounding box ,phrase 可以使用 NLP parser 来检测
teacher model 能对一些难定论的目标或抽象的目标进行定位,也能带来很丰富的语义信息
所以,可以在 27M grounding data 上 pre-train 我们的 student GLIP-large model(GLIP-L)
27M grounding data :
- 3M 人工标注的精细数据
- 24M 从网上收集的 image-text pairs,有 78.1M 高置信得分(>0.5)的 phrase-box 伪标注,58.1M 唯一的 phrase
- 示例如图 3 所示
3、使用 GLIP 进行迁移学习:从一个 model 到所有 model
当 GLIP-L 模型在 COCO 和 LVIS 数据集上直接进行验证(没有见过其他数据),就能在 COCO val 2017 上达到 49.8 AP,在 LVIS val 上达到 26.9 AP ,超越了很多基础方法
2.1 将 object detection 和 phrase grounding 进行统一
1、传统的目标检测任务:
是将图像输入 backbone(CNN 或 Transformer)来抽取基础特征,如图 2 底部,然后将每个候选区域输入分类头和检测头来预测类别和位置,loss 如下:

- 在 two-stage 检测器中,会使用 RPN 来进行前景和背景的初步区分,作者在这里将 RPN 的 loss 在含义上融入了 LOC loss 中
- 在 one-stage 检测器中,LOC loss 中也会包含类似 centerness loss
box classifier C C C 可以是简单的线性层,classification loss L c l s L_{cls} Lcls 可以被写为:
![]()
- O O O 是 object/region/box features
- W W W 是 box classifier C C C 的 weight matrix
- S c l s S_{cls} Scls 是输出分类 logits
- T ∈ { 0 , 1 } T\in\{0, 1\} T∈{0,1} 是 region 和 classes 的匹配
- l o s s ( S ; T ) loss(S; T) loss(S;T) 在单阶段检测器中是 cross-entropy loss,在双阶段检测器中是 focal loss
2、将目标检测重构为 phrase grounding:
-
不需要对每个 region/box 划分类别,grounding 任务是通过将每个 region 对齐(grounding/aligning) 到 text prompt 中的 c c c 个 phrase 上,如图 2 所示。
-
如何为 detection 任务设计 text prompt:将所有要检测的类别组成如下形式,每个类别名称都是需要被 grounded 的
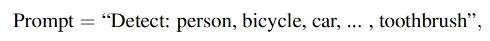
-
在 grounding model 中,作者会计算 image region 和 words in prompt 之间的 alignment scores S g r o u n d S_{ground} Sground,

- P ∈ R M × d P \in R^{M \times d} P∈RM×d 是从 language encoder 中得到的上下文 word feature
- E n c I Enc_I EncI:image encoder
- E n c L Enc_L EncL:language encoder
-
训练:将公式 2 中的 classification logits S c l s S_{cls} Scls 替换为 S g r o u n d S_{ground} Sground,然后最小化公式 1 和 2
注意,在公式 2 中, S g r o u n d ∈ R N × M S_{ground} \in R^{N \times M} Sground∈RN×M , T ∈ { 0 , 1 } N × c T\in\{0, 1\}^{N \times c} T∈{0,1}N×c,但由于 word token 的数量 M M M 一般都大于 phrases c c c 的数量,原因有四个:
- 一些 phrases 包含多个 words(如 traffic light)
- 一些 single-word phrase 被分为多个 sub-word token(如 toothbrush 被分为 tooth 和 bruth)
- 一些 token 是被添加进去的(图 Detect: 和 ‘,’)
- tokenized sequence 的尾部有 [NoObj] token
所以,当 loss 是 binary sigmoid loss 时,将 T ∈ { 0 , 1 } N × c T\in\{0, 1\}^{N \times c} T∈{0,1}N×c 扩展为 T ′ ∈ { 0 , 1 } N × M T' \in\{0, 1\}^{N \times M} T′∈{0,1}N×M,这样就可以实现:
- 当 phrase 是 positive match 时,让每个 sub-word 也都实现 positive match
- 一些被加进去当做标识字符的 word 对所有特征都是 negative match
2.2 Language-aware deep fusion
在公式 3 中,image 和 text 分别使用不同的 encoder 来提取特征,然后在最后进行融合来计算 alignment scores,这样的模型是 late-fusion models
在 vision-language 的相关方法中,deep fusion 很重要,能够优化 phrase grounding 模型
所以本文也使用了 deep fusion 的方式来对 image 和 language encoder 的结果进行融合,也就是在后面几个 encoder layer 就对 image 和 text 特征进行融合,如图 2 中间所示
作者使用 DyHead[10] 作为 image encoder,使用 BERT 作为 text encoder,则 deep-fused encoder 为:

- L L L:DyHead 的 DyHeadModules 的数量
- BERTLayer:是在经过预训练的 BERT 的顶部新加的一个 BERT layer
- O 0 O^0 O0:vision backbone 输出的 visual feature
- P 0 P^0 P0:language backbone 输出的 token feature
- X-MHA:cross-modality multi-head attention model,用于进行多模态交互, O t 2 i i O_{t2i}^i Ot2ii 是 token2image 交互结果, P i 2 t i P_{i2t}^i Pi2ti 是 image2token 交互结果, 如果没有 X-MHA 的话,则退化为 late-fusion model
X-MHA 的每个 head 都计算从一个模态到另一个模态的 context vectors:

2.3 使用语义丰富的数据来进行预训练
人工标注很费时费力,很多方法研究使用 self-training 方式来扩充,一般使用 teacher 模型来生成伪边界框来训练 student model,但生成的 label 也会受限于 concept pool,student model 也只能学习预设好的 concept pool。
本文的模型可以在 detection 和 grounding data 上同时训练,grounding data 可以提供丰富的语义信息来促进定位:
- 首先,好的 grounding data 覆盖了很大的词汇池,比现有的检测数据集词汇池大得多,目前经过扩展的最大的检测数据集词汇不超过 2000 类,而 grounding data 可以扩展到很大,如 Flickr30K[44] 包括 44518 个独一无二的 phrases,VG Caption[28] 包括 110689 个独一无二的 phrases,远远大于检测数据集的类别数量
- 其次,不扩充 detection data 的情况下,也可以使用扩充 grounding data 的方式来提高语义丰富性。作者受启发于 self-training,首先使用人工标注的好的检测标注和 grounding data 预训练一个 teacher GLIP,然后使用这个 teacher model 来预测从网络获取的 image-text data 中的目标框,最后使用标注好的 data 和生成的伪标签来训练 student model,如图 3 所示,teacher 模型能够对语义丰富的描述生成准确的框
为什么 student model 的效果可能会超过 teacher model 的效果:
- 如图 3 所示,如图标注数据中没有某些类别的话,teacher model 可能没法直接识别特定的概念,如 vaccine 、turquoise,但是,丰富的语言概念可以给 teacher model 提供很强的指导作用,让其能够进行猜想,所以,如果模型能够定位 small vail,则也可能能够定位 vaccine,如果模型能够定位 caribbean sea,则也可能能够定位 turquoise
- 所以在训练 student model 时,这种猜想能力就会变成有监督的信号,让 student 模型能够学习 vaccine 和 turquoise

三、效果
3.1 迁移到现有 Benchmarks
经过预训练的 GLIP 能够很方便的用于 grounding 和 detection 任务,作者在三个数据集上进行了验证:
- MS-COCO object detection,包括 80 个检测类别
- LVIS object detection:包括超过 1000 个检测类别
- Flickr30K phrase grounding
训练了 5 个 GLIP 变体,如表 1 所示:
- GLIP-T(A):基于 SOTA detection model——Dynamic Head,使用 word-region alignment loss 代替 classification loss,使用 Swin-Tiny backbone,在 Object365 上预训练(0.66M 数据,356 个类别)
- GLIP-T(B):使用 language-aware deep fusion,只在 Object365 上进行了预训练
- GLIP-T©:在 Object365 和 GoldG 上预训练,GoldG 包括 0.8M 人工标注的 grounding data( including Flickr30K, VG Caption [28], and GQA [19])
- GLIP-T:使用 Swin-Tiny 作为 backbone,在 Object365、GoldG、Cap4M(4M image-text pairs 从网上收集的数据,使用 GLIP-T© 进行预标框。
- GLIP-L:使用 Swin-Large 并且在这些数据上训练 FourODs (2.66M data)、Objects365、 OpenImages [27]、Visual Genome (excluding
COCO images) [28]、ImageNetBoxes [29]、GoldG、CC12M+SBU(24M image-text data collected from the web with generated boxes)
3.2 在 COCO 上进行零样本和有监督的迁移
DyHead:用于对比,先在 Object365 上训练 DyHead(因为 COCO 80 类基本包含在 Object 365),在推理的时候只推理 COCO 的 80 个类别
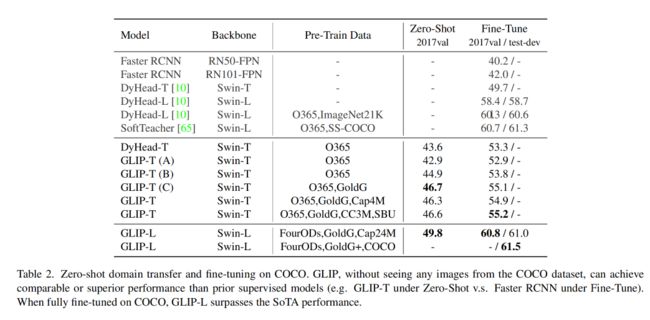
如表 2 所示:
- GLIP model 同时在 zero-shot 和 supervised 上获得了好的效果
- GLIP-T 获得了 46.7AP,超过了 Faster RCNN
- GLIP-L 获得了 49.8 AP,超过了 DyHead-T,在有监督情况下, GLIP-T 超过 DyHead 5.5 AP (55.2 vs. 49.7)
在 zero-shot 性能验证时,发现了 3 点:
- Objects365 和 COCO 的域很接近,所以在 Object365 上预训练的模型在 COCO 上的表现很好,zero-shot 达到了 43.6 AP。
- 直接将检测模型重建为 grounding model 会导致性能下降 (GLIP-T(A)),但使用 deep fusion 带来了 2AP 的提升(GLIP-T(B))
- 最大的贡献在于 gold grounding data,GLIP-T© 获得了 zero-shot 的 最高 46.7 AP,image-text data 对 COCO 没有什么提升 (CLIP-T vs. GLIP-T©)
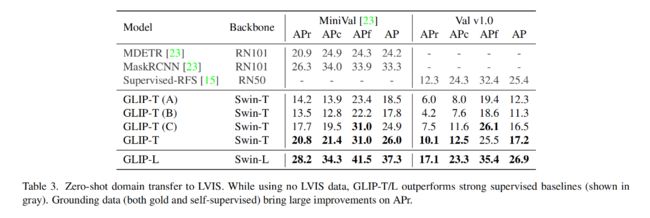
3.3 在 LVIS 上进行零样本迁移学习
GLIP 在所有类别上都表现出了很好的效果
3.4 在 Flickr30K Entities 上进行 phrase grounding 验证

3.5 分析
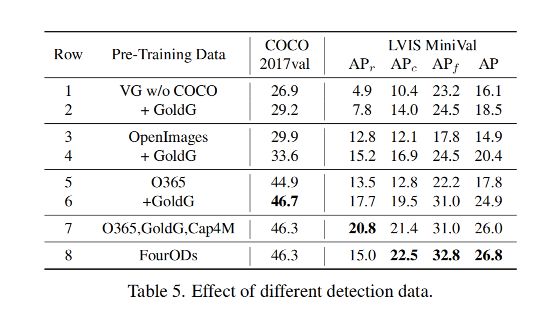
下表展示了在不同数据上预训练 GLIP-T 的消融实验:
- 证明 1:使用 detection dataset 能够提升模型性能
- 证明 2:grounding data 能够为模型引入更丰富的语义信息
3.6 自然环境中的目标检测
为了验证 GLIP 在 real-world 任务中的迁移能力,作者收集了一个 Object Detection in the wild(ODinW)集合,使用 13 个 Roboflow 上的 开源数据集


3.7 如何将一个模型扩展到所有任务
由于现在基础模型越来越大,如何降低部署的消耗就很重要
现在很多 language model、image classification、object detection 任务都是使用一个预训练好的模型,只修改少量需要定制的超参数就可以扩展到不同的任务上
如 linear probing[26]、prompt tuning[27]、efficient task adapter[13]
1、Manual prompt tuning
GLIP 支持在 prompt 中添加特定的 input 来指定不同的任务
如图 6,左侧表示模型无法识别 stingray,但如果添加上了一些属性 prompt(如 flat and round),模型就可以定位出 stingrays,AP50 从 4.6 提到了 9.7

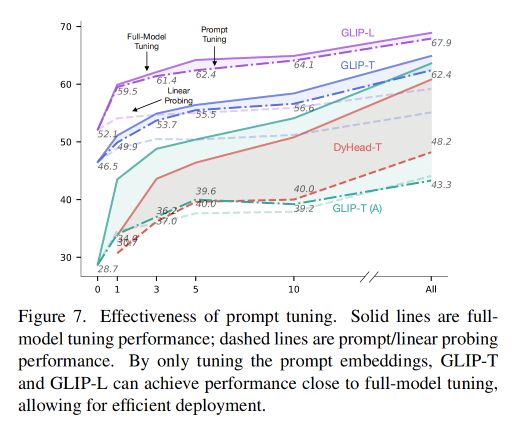
2、prompt tuning
在 GLIP 中,每个检测任务只有一个 prompt,效果如图 7 所示