YOLOv8训练参数详解
全部参数表
首先罗列一下官网提供的全部参数。

1. model ✰✰✰✰✰
model: 模型文件的路径。这个参数指定了所使用的模型文件的位置,例如 yolov8n.pt 或 yolov8n.yaml。
选择.pt和.yaml的区别
- 若我们选择 yolov8n.pt这种.pt类型的文件,其实里面是包含了模型的结构和训练好的参数的,也就是说拿来就可以用,就已经具备了检测目标的能力了,yolov8n.pt能检测coco中的80个类别。但如果你需要检测的类别不在其中,例如口罩检测,那么就需要重新训练。
- 训练自己的数据集,我们一般采用yolov8n.yaml这种.yaml文件的形式,在文件中指定类别,以及一些别的参数。
2. data ✰✰✰✰✰
data: 数据文件的路径。该参数指定了数据集文件的位置,例如 coco128.yaml。数据集文件包含了训练和验证所需的图像、标签。
3. epochs ✰✰✰
epochs: 训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个训练数据集。训练的轮数越多,模型对数据的学习就越充分,但也增加了训练时间。
选取策略
默认是100轮数。但一般对于新数据集,我们还不知道这个数据集学习的难易程度,可以加大轮数,例如300,来找到更佳性能。
4. patience
patience: 早停的等待轮数。在训练过程中,如果在一定的轮数内没有观察到模型性能的明显提升,就会停止训练。这个参数确定了等待的轮数,如果超过该轮数仍没有改进,则停止训练。
早停
早停能减少过拟合。过拟合(overfitting)指的是只能拟合训练数据, 但不能很好地拟合不包含在训练数据中的其他数据的状态。
5. batch ✰✰✰✰✰
batch: 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为**-1**,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
选取策略
一般认为batch越大越好。因为我们的batch越大我们选择的这个batch中的图片更有可能代表整个数据集的分布,从而帮助模型学习。但batch越大占用的显卡显存空间越多,所以还是有上限的。
6. imgsz ✰✰✰✰✰
imgsz: 输入图像的尺寸。这个参数确定了输入图像的大小。可以指定一个整数值表示图像的边长,也可以指定宽度和高度的组合。例如640表示图像的宽度和高度均为640像素。
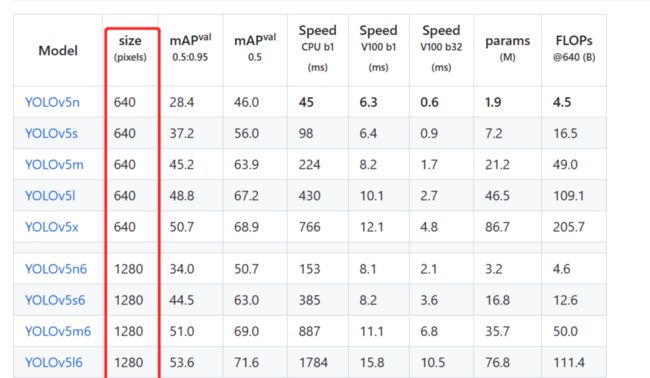
选取策略
如果数据集中存在大量小对象,增大输入图像的尺寸imgsz可以使得这些小对象从高分辨率中受益,更好的被检测出。从官网放出的性能表也可以看出。
7. save、save_period ✰✰✰
- save: 是否保存训练的检查点和预测结果。当训练过程中保存检查点时,模型的权重和训练状态会被保存下来,以便在需要时进行恢复或继续训练。预测结果也可以被保存下来以供后续分析和评估。
- save_period: 保存检查点的间隔。这个参数确定了保存检查点的频率,例如设置为10表示每隔10个训练轮数保存一次检查点。如果设置为负数(如-1),则禁用保存检查点功能。
和resume配合
和resume配合可以在训练不稳定中断后再进行接着训练。例如大家白嫖Colab这个平台训练网络时,一般是有时间限制,会出现时间到了我们还没训练完的情况。通过save然后再resume重新启动可以进行接着训练。
8. cache
cache: 数据加载时是否使用缓存。这个参数控制是否将数据加载到缓存中,以加快训练过程中的数据读取速度。可以选择在 RAM 内存中缓存数据(True/ram)、在磁盘上缓存数据(disk)或不使用缓存(False)。
9. device ✰✰✰✰✰
device: 训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为 cuda device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。
注意别选择错了。
10. workers
workers: 数据加载时的工作线程数。在数据加载过程中,可以使用多个线程并行地加载数据,以提高数据读取速度。这个参数确定了加载数据时使用的线程数,具体的最佳值取决于硬件和数据集的大小。
11. project
project: 项目名称。这个参数用于标识当前训练任务所属的项目,方便管理和组织多个训练任务。
12. name
name: 实验名称。该参数为当前训练任务指定一个名称,以便于标识和区分不同的实验。
13. exist_ok
exist_ok: 是否覆盖现有的实验。如果设置为 True,当实验名称已经存在时,将会覆盖现有实验。如果设置为 False,当实验名称已经存在时,将会报错。
14. pretrained
pretrained: 是否使用预训练模型。如果设置为 True,将加载预训练的模型权重进行训练,这有助于加快训练过程和提高模型性能。
15. optimizer
optimizer: 选择要使用的优化器。优化器是深度学习中用于调整模型参数以最小化损失函数的算法。可以选择不同的优化器,如 ‘SGD’、‘Adam’、‘AdamW’、‘RMSProp’,根据任务需求选择适合的优化器。
16. verbose
verbose: 是否打印详细输出。如果设置为 True,训练过程中会输出更详细的信息和日志。如果设置为 False,只会输出关键信息和结果。
17. seed
seed: 随机种子,用于实现可重复性。通过设置相同的随机种子,可以使得每次运行时的随机过程保持一致,以便于结果的复现。
18. deterministic
deterministic: 是否启用确定性模式。启用确定性模式后,保证在相同的输入下,每次运行的结果是确定的,不会受到随机性的影响。
19. single_cls
single_cls: 将多类数据训练为单类。如果设置为 True,将会将多类数据视为单一类别进行训练。
20. rect
rect: 使用矩形训练,每个批次进行最小填充。设置为 True 后,训练过程中使用矩形形状的图像批次,并进行最小化填充。
21. cos_lr
cos_lr: 使用余弦学习率调度器。如果设置为 True,将使用余弦函数调整学习率的变化情况。
22. close_mosaic
close_mosaic: 禁用mosaic增强的最后第几个轮次。可以指定一个整数值,表示在训练的最后第几个轮次中禁用mosaic增强。
mosaic是什么
Mosaic数据增强方法是YOLOV4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。这样做的好处是丰富了图片的背景,并且四张图片拼接在一起变相地提高了batch_size,在进行batch normalization的时候也会计算四张图片,所以对本身batch_size不是很依赖,单块GPU就可以训练YOLOV4。
YOLOV4论文YOLOv4: Optimal Speed and Accuracy of Object Detection
23. resume
resume: 从最后一个检查点恢复训练。如果设置为 True,将从最后一个检查点的状态继续训练。
24. amp
amp: 是否使用自动混合精度(Automatic Mixed Precision,AMP)训练。AMP 是一种深度学习训练技术,利用半精度浮点数加速训练过程,可以减少显存占用。
25. lr0
lr0: 初始学习率。学习率是控制模型参数更新步幅的超参数,初始学习率确定了训练开始时的参数更新速度。
26. lrf
lrf: 最终学习率。最终学习率是通过初始学习率乘以一个比例系数得到的,用于控制训练过程中学习率的衰减。
注意lrf其实是系数,最终学习率相较于初始学习率的系数。
27. momentum
momentum: SGD 优化器的动量/Adam 优化器的 beta1。动量是一种加速梯度下降过程的技术,用于增加参数更新的稳定性。
28. weight_decay
weight_decay: 优化器的权重衰减(weight decay)。权重衰减是一种正则化技术,用于减小模型复杂度,防止过拟合。
29. warmup_epochs
warmup_epochs: 热身阶段的轮数。热身阶段是训练过程中初始阶段的一部分,在此阶段内,学习率和动量等参数逐渐增加,以帮助模型更好地适应训练数据。
30. warmup_momentum
warmup_momentum: 热身阶段的初始动量。在热身阶段开始时,动量的初始值。
31. warmup_bias_lr
warmup_bias_lr: 热身阶段的初始偏置学习率。在热身阶段开始时,偏置学习率的初始值。
32. box、cls
- box: 边界框损失权重。用于调整边界框损失的权重,以控制其在总损失中的贡献程度。
- cls: 类别损失权重。用于调整类别损失的权重,以控制其在总损失中的贡献程度(按像素进行缩放)。
调整策略
如果你想更强调一些分类也就是更精准的类别判断你可以增加cls的值;如果你想更强调一些边界框的定位你可以增加box的值。
这个两个权重我认为也可以根据你目前训练输出的边界框损失数值和分类损失数值来判断。
33. dfl
dfl: DFL(Dynamic Freezing Loss)损失权重。用于调整 DFL 损失的权重,以控制其在总损失中的贡献程度。
dfl定义
参考这里的定义双焦点损失 (DFL)双焦点损失(DFL)缓解了分类和语义分割中的类不平衡问题。此损失函数的灵感来自焦点损失 (FL)函数的特性,该函数加剧了数据点的损失,在预测输出和实际输出之间产生较大差异。因此,如果由于类不平衡或其他一些原因,数据点难以分类,FL 使神经网络更多地关注该数据点以及类似的数据点。DFL采用了这一思路,并通过增强梯度条件提高了FL的性能。
通俗解释
DFL损失函数在训练神经网络时考虑了类别不平衡的问题。当某些类别出现频率过高,而另一些类别出现频率较低时,就会出现类别不平衡的情况。例如,在街景图像中,假设有100张照片,其中有200辆汽车和只有10辆自行车。我们希望同时检测汽车和自行车。这就是类别不平衡的情况,在训练神经网络时,由于汽车数量较多,网络会学习准确地定位汽车,而自行车数量较少,网络可能无法正确地定位自行车。通过使用DFL损失函数,每当神经网络试图对自行车进行分类时,损失会增加。因此,现在神经网络会更加重视出现频率较低的类别。更多信息,可以参考有关Focal Loss和DFL的论文。
焦点损失文章Focal Loss for Dense Object Detection[https://arxiv.org/abs/1708.02002]
调整策略
类别不平衡时使用,也就是当某些类别出现频率过高,而另一些类别出现频率较低时。
34. pose
pose: 姿态损失权重(仅姿态)。用于调整姿态损失的权重,以控制其在总损失中的贡献程度(仅应用于姿态相关任务)。
35. kobj
kobj: 关键点目标损失权重(仅姿态)。用于调整关键点目标损失的权重,以控制其在总损失中的贡献程度(仅应用于姿态相关任务)。
36. label_smoothing
label_smoothing: 标签平滑(label smoothing)。标签平滑是一种正则化技术,用于减少模型对训练数据的过拟合程度。
标签平滑
label smoothing就是把原来的one-hot表示的标签,在每一维上都添加了一个随机噪音。
37. nbs
nbs: 标准批次大小(nominal batch size)。指定训练过程中每个批次的大小。
38. overlap_mask
overlap_mask: 训练时是否要求蒙版重叠(仅用于分割训练)。如果设置为 True,要求训练过程中的蒙版(mask)重叠。
39. mask_ratio
mask_ratio: 蒙版下采样比例(仅用于分割训练)。用于控制蒙版下采样的比例。
40. dropout
dropout: 是否使用丢弃正则化(dropout regularization)(仅用于分类训练)。如果设置为非零值,则在训练过程中使用丢弃正则化来减少模型的过拟合。
41. val
val: 是否在训练过程中进行验证/测试。如果设置为 True,将在训练过程中进行验证或测试,以评估模型的性能。