数据科学系列:数据处理(7)--字符串函数基于R(三)
这一部分,将R语言stringr包中的使用正则表达式的字符串函数简单介绍一下,会用到正则表达式的相关内容,有关正则表达式的知识可以回顾R&Python Data Science系列:数据处理(6)--字符串函数基于R(二)
4.3 使用正则表达式的字符串函数

4.3.1 str_count()函数
str_count()函数用于检验字符串中出现特征的次数,返回一个数字向量。
str_count(string, pattern = "")参数
pattern:匹配的字符
text <- c('Flash', 'Flaash', 'Flaaash', 'Flaaaasha') 检验字符串向量中"a"出现的次数:
str_count(text, "a")字符串"Flash"中有一个"a",所以返回数字向量1,"Flaaaasha"中有5个"a",所以返回数字向量5。
检验字符串向量text中以F开始,h结尾的字符个数:
str_count(text, "^F\\w*h$")
4.3.2 str_split()和str_split_fixed()函数
str_split()函数在匹配的位置拆分字符串,返回列表或者矩阵形式的字符串,默认情况下返回列表形式数据,当参数simplify = TRUE等价于str_split_fixed()函数;
str_split_fixed()函数在匹配的位置将字符串拆分固定的块数,返回矩阵形式的字符串;
str_split(string, pattern, n = Inf, simplify = FALSE)str_split_fixed(string, pattern, n)参数
pattern:匹配的字符
n : 拆分的个数
simplify:逻辑值,如果是FALSE,返回列表形式字符串向量,如果是TRUE,返回矩阵形式字符串。
text2 <- c("flashandFlashandFLASH","workingnotesAndWorkingnotesandWORKINGNOTESAndWorkingNotes")使用分隔符and或者And拆分字符串,参数simplify = FALSE(默认为FALSE),并用class()函数查看返回数据类型:
str_split(text2, "(a|A)nd")class(str_split(text2, "(a|A)nd"))
使用分隔符and或者And拆分字符串,参数simplify = TRUE,并用class()函数查看返回数据类型,使用dim()函数查看返回矩阵的结构:
str_split(text2, "(a|A)nd", simplify = TRUE)class(str_split(text2, "(a|A)nd", simplify = TRUE))dim(str_split(text2, "(a|A)nd", simplify = TRUE))
参数simplify = TRUE时候,返回矩阵形式数据,且长度不够的位置为空字符串。
使用参数n强制在匹配的位置拆分指定的几块:
str_split(text2, "(a|A)nd", simplify = TRUE, n = 3)
当指定参数n的个数的时候,从左到右拆分,即使第n个字符串中仍可以拆分,不做拆分。
str_split_fixed(text2, "(a|A)nd", n = 3)
4.3.3 str_substr()与str_which()函数
str_substr()函数返回符合匹配的字符串,返回结果是字符串;
str_which()函数返回符合匹配的字符串的位置,返回结果是数字向量,一般用在字符串向量中。
str_subset(string, pattern)str_which(string, pattern)参数
pattren:匹配的字符
匹配以a开始:
text3 <- c("flash", "aflash", "flasha"str_subset(text3, "^a")str_which(text3, "^a")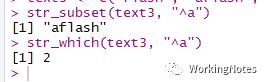
匹配以a结束:
str_subset(text3, "a$")str_which(text3, "a$")
4.3.4 str_detect()函数
str_detect()函数,用于检验字符串中是否包含匹配的特征,返回结果为逻辑值TRUE和FALSE。
str_detect(string, pattern)参数
pattern : 匹配的字符
检测字符串向量text3中字符串是否以a开头:
str_detect(text3, "^a")
4.3.5 str_match()与str_match_all()函数
str_match()函数从字符串中返回匹配的字符,没有匹配的字符返回NA,返回结果为矩阵形式。
str_match_all()函数从字符串中返回匹配的字符,没有匹配的字符返回NA,返回结果为列表形式。
str_match(string, pattern)str_match_all(string, pattern)参数
pattern:匹配的字符
text4 <- c("flash", "FLASH", "flash007")str_match(text4, "a")class(str_match(text4, "a"))
str_match_all(text4, "a")class(str_match_all(text4, "a"))
4.3.6 str_replace()与str_replace_all()函数
str_replace()函数替换字符串中第一个匹配到的特征,返回字符向量;
str_replace_all()函数替换字符串中所有匹配到的特征,返回字符向量;
str_replace(string, pattern, replacement)str_replace_all(string, pattern, replacement)参数
pattern:匹配的字符
replacement:用于替换的字符
text5 <- c("flasha", "FLASHa", "flash007")将字符串中的a或者A替换成F:
str_replace(text5, "[aA]", "F")str_replace_all(text5, "[aA]", "F")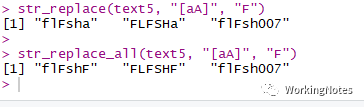
4.3.7 str_locate()与str_locate_all()函数
str_locate()函数用于返回第一个匹配到的特征的位置,返回结果为起始和结束为列名的矩阵
str_locate_all()函数返回所有匹配的特征位置,返回结果为列表
str_locate(string, pattern)
str_locate_all(string, pattern)参数
pattern:匹配的字符
text5 <- c("flasha", "FLASHa", "flash007")str_locate(text5, "a")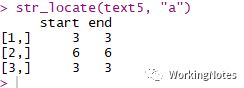
str_locate_all(text5, "a")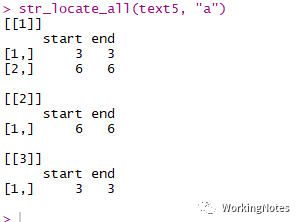
4.3.8 str_extract()与str_extract_all()函数
str_extract()函数用于提取匹配特征的第一个字符串,返回结果为字符向量;
str_extract_all()函数用于提取匹配特征的所有字符串,默认返回结果为字符向量的列表
str_extract(string, pattern)str_extract_all(string, pattern, simplify = FALSE)参数
pattren:匹配的字符
simplify:逻辑值,如果是FALSE,返回列表形式字符向量的列表,如果是TRUE,返回字符向量的矩阵。
text5 <- c("flasha", "FLASHa", "flash007")str_extract(text5, "[a-zA-Z]+")str_extract_all(text5, "[a-zA-Z]+")str_extract_all(text5, "[a-zA-Z]+", simplify = TRUE)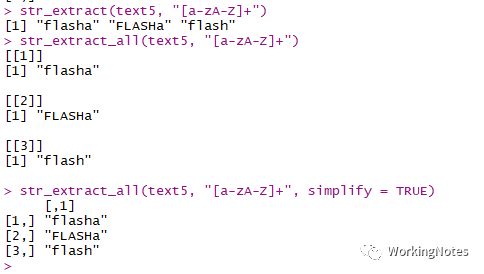
4.3.9 小结
从非正则表达式字符串函数、R语言中的正则表达式以及使用正则表达式的字符串函数介绍了R语言中stringr包中的字符串函数。下面将介绍数据处理--字符串函数基于Python的部分。