机器学习实验四:不同含量果汁饮料的聚类
机器学习实验四:不同含量果汁饮料的聚类
实验要求
实验过程
1.对该题目的理解
本项目是某企业通过采集企业自身流水线生产的一种果汁饮料含量的数据集,其中数据集共有样本59个,变量2个,包括juice(该饮料的果汁含量偏差)、sweet(该饮料的糖分含量偏差),单位均为 mg/ml。来实现 K-Means 算法。我们通过聚类以判断该果汁饮料在一定标准含量偏差下的生产质量状况,然后对该饮料进行类别判定。
2.实现过程
(1)导入包。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn import metrics(2)加载数据集,读取数据,探索数据。(数据集路径:data/data76878/4_beverage.csv)。
代码如下:
data = pd.read_csv("data/data76878/4_beverage.csv")
print(data)
print(data.shape)(3)样本数据转化为数组形式并进行可视化(绘制散点图),然后观察数据的分布情况,从而可以得出 k 的几种可能取值。
代码如下:
npdata = np.array(data) # 转化成numpy数组
x = data.iloc[:, 0 : 1]
y = data.iloc[:, 1 : 2]
plt.xlabel(u"juice")
plt.ylabel(u"sweet")
plt.title(u"The relation juice and sweet")
plt.scatter(x, y) # 绘制散点图
plt.show()(4)针对每一种 k 的取值,进行K-Means 算法模型的配置、训练,然后输出相关聚类结果,并评估聚类效果。
代码如下:
for n_clusters in range(3,10):
# 进行K-Means算法模型的配置、训练
kmeans = KMeans(n_clusters) # 构建聚类器
kmeans.fit(npdata)
# 输出相关聚类结果,并评估聚类效果
y_predict=kmeans.predict(npdata)
score=metrics.calinski_harabasz_score(npdata,y_predict)
print('{1} 准确率:{0:f}'.format(score,n_clusters)) #显示准确率
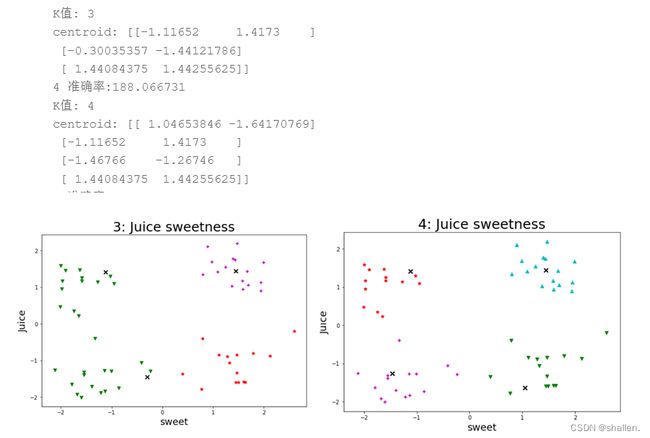
(5)针对每一种 k 输出各类簇标签值、各类簇中心,从而判断每类的果汁含量与糖分含量情况,然后将聚类结果及其各类簇中心点的可视化(散点图),从而观察各类簇分布情况。
代码如下:
# 输出各类簇标签值、各类簇中心,从而判断每类的果汁含量与糖分含量情况
centroid = kmeans.cluster_centers_ # 重要属性cluster_centers_,查看质心
print("K值:",n_clusters)
print("centroid:",centroid)
markers = ['*', 'v', '+', '^', 's', 'x', 'o','1','2','3','4'] # 标记样式列表
colors = ['r', 'g', 'm', 'c', 'y', 'b', 'orange','skyblue','black'] # 标记颜色列表
labels = kmeans.labels_ # 获取聚类标签
# 聚类结果及其各类簇中心点的可视化(散点图),从而观察各类簇分布情况
plt.figure(figsize=(9, 6))
plt.title('{0}: Juice sweetness'.format(n_clusters),fontsize=25)
plt.xlabel('sweet',fontsize=18)
plt.ylabel('Juice',fontsize=18)
for i in range(n_clusters):
members = labels == i # members是一个布尔型数组
plt.scatter(
npdata[members, 1],
npdata[members, 0],
marker = markers[i], # 标记样式
c = colors[i] # 标记颜色
) # 绘制散点图
plt.scatter(
centroid[:, 0],
centroid[:, 1],
marker="x",
c="black",
s=48
)3.遇到的问题及解决办法
(1)问题:如何进行数据可视化,将簇中心点也进行可视化?
解决方法:利用属性cluster_centers_,查看质心,然后用X来代表簇中心,画在散点图上,从而达到可视化。
实验结果
1.加载数据集,读取数据,探索数据。(数据集路径:data/data76878/4_beverage.csv)。

2.样本数据转化为数组形式并进行可视化(绘制散点图),然后观察数据的分布情况,从而可以得出 k 的几种可能取值。

3.针对每一种 k 的取值,进行K-Means 算法模型的配置、训练,然后输出相关聚类结果,并评估聚类效果。

4.针对每一种 k 输出各类簇标签值、各类簇中心,从而判断每类的果汁含量与糖分含量情况,然后将聚类结果及其各类簇中心点的可视化(散点图),从而观察各类簇分布情况。


实验总结
1.通过此实验了解了k均值聚类算法,它是是一种迭代求解的聚类分析算法,也学会了如何配置,训练,预测K-Means模型并且学会了如何评估聚类效果。
2.通过此实验,我了解了如何将结果可视化,通过绘制散点图来可视化。