电子科技大学计算机系统结构复习笔记(三):流水线技术
目录
前言
重点一览
流水线定义
基本概念
流水线分类
流水线特点
流水线时空图
流水线性能分析
流水线特点
经典5段流水线RISC处理器
流水线的三种冒险
冒险分类
停顿流水线
结构冒险
数据冒险
控制冒险
流水线处理机的指令系统
流水线指令系统与格式
流水线各级间的寄存器作用(看图理解)
流水线各级的操作(看图理解)
无相关流水线模型机多条指令执行过程(一例,看图理解)
流水线控制信号
数据前推与load前推
相关(冒险)小结
流水线异常与浮点流水线
流水线异常
异常原因
异常可能的阶段
停止和重新开始执行(MIPS)
精确中断(精确异常)
非精确中断(非精确异常)
精确异常和非精确异常
经典5段流水线扩展浮点流水线
浮点流水线的写冲突
浮点流水线数据相关
异常处理
本章小结
前言
本复习笔记基于叶老师的课堂PPT,供自己期末复习与学弟学妹参考用。
重点一览

流水线定义
基本概念
流水线是利用执行指令操作之间的并行性,实现多条指令重叠执行的技术。
流水线分类
- 按各过程段是否相等分类
- 均匀流水线
- 非均匀流水线
- 按处理的数据类型
- 标量流水处理机
- 向量流水处理机
- 按流水线的规模
- 操作流水线(将算术逻辑部件分段)
- 指令流水线(流水处理指令)
- 宏流水线(两个以上处理机流水执行)
- 按功能分类
- 单功能流水线
- 多功能流水线
- 按工作方式
- 静态流水线
- 动态流水线

- 按连接方式
- 线性流水线(没有反馈回路)
- 根据控制方式再分为
- 同步流水线
- 异步流水线
- 根据控制方式再分为
- 非线性流水线(有反馈回路)
- 线性流水线(没有反馈回路)
- 按控制方式
- 顺序流水线
- 乱序流水线
流水线特点
(1)流水线处理的最好是连续任务,只有连续不断的任务才能充分发挥流水线的效率。
(2)流水线依靠多个功能部件并行工作来缩短程序的执行时间,实际上是把一个大的功能部件分解为多个子过程,如前述将浮点数加法器分解为4个子过程。
(3)流水线中的每一功能部件后面都要有一个缓冲寄存器,即所谓的锁存器,以便平滑各个功能段延时时间的不一致。
(4)流水线中各段时间应尽量相等,避免段延时过长引起的相互等待。
(5)流水线需要有“装入时间”和“排空时间”。
流水线时空图
时空图从时间和空间两个方面描述了流水线的工作过程。时空图中,横坐标代表时间,纵坐标代表流水线的各个段
下图是4段指令流水线的时空图(6个任务)

流水线性能分析
吞吐率:在单位时间内流水线所完成的任务数量或输出结果的数量
 n:任务数;Tk:处理完成n个任务所用的时间
n:任务数;Tk:处理完成n个任务所用的时间
各时段均相等的流水线的实际吞吐率: ,n>>k 时,才有TP≈TPmax=
,n>>k 时,才有TP≈TPmax=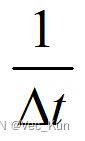
各段不相等的流水线中,占时间最长的一段叫作瓶颈段,他的实际吞吐率: ,最大吞吐率:
,最大吞吐率:
解决流水段瓶颈方法:①细分瓶颈段使得和其他流水段长度一致;②重复设置瓶颈段

加速比: 流水线的加速比(Speedup)是完成某个任务顺序执行所用时间与流水线执行所用时间之比。
不使用流水线(即顺序执行)所用的时间为Ts,使用流水线后所用的时间为Tk,则该流水线的加速比为 ,若各流水段所用时间相等,则最大加速比为k(k段流水线的k);各流水段时间不完全相等时用定义计算;在时空图中用n*k/t计算,也就是用任务数*流水段数/横轴时间。
,若各流水段所用时间相等,则最大加速比为k(k段流水线的k);各流水段时间不完全相等时用定义计算;在时空图中用n*k/t计算,也就是用任务数*流水段数/横轴时间。
效率:指流水线的设备利用率。在时空图上,流水线的效率定义为n个任务占用的时空区与k个功能段总的时空区之比,因此流水线的效率包含时间和空间两个方面的因素 ,其实就是平行四边形面积和矩形面积之比
,其实就是平行四边形面积和矩形面积之比
如果每个流水段时间相等,任务连续,则效率 ,最大效率为n→∞时,E=1 。
,最大效率为n→∞时,E=1 。
流水线特点
- 一个流水线类似自动装配线
- 一个流水线有多个段(级),段间有流水线寄存器
- 每个流水段执行指令或操作的不同部分
- 流水段之间采用同步时钟控制
- 一条指令或操作从流水线一端进入,经过各段,从另一端流出
- 流水线是开发串行指令流中并行性的一种实现技术
经典5段流水线RISC处理器
RISC系统:所有参加运算的数据来自寄存器,结果也写入寄存器;寄存器为32/64位;访存只有load和store指令;指令的数量较少,所有指令长度相同;MIPS系统是默认的RISC系统结构
五个周期:IF ID EX MEM WB
- IF(取指)按照 PC 内容访问指令存储器,取出指令 PC+4→NPC,以获取下一条指令地址
- ID(译码)指令译码 读寄存器 如果需要,符号扩展指令中的位移量
- EX(执行)Load/Store: 计算数据存储器有效地址 R-R/ R-I ALU: 执行运算操作 Branch: 做相等测试,如果相等计算目标地址送PC
- MEM(存储)Load: 送有效地址到数据存储器,取数据 Store: 写ID读出数据到有效地址单元中
- WB(写回)Load or ALU: 写结果到寄存器堆

流水线优势
- 5个段构成了一个指令流水线,一条指令经过每个段。
- CPI 减少到1,因为每个时钟周期发射或完成一条指令。
- 在任意时钟周期,在每个流水段正执行一条指令的部分。

紫色部分:流水线处理机每个时钟周期都要取出一条指令。这意味着,当流水线处理机已从存储器取出一条指令并把它送到ID级去译码时,下一条指令也正在从存储器中取出。如果先取出的指令没被保存,则它后面正在被取出的指令会对它造成影响。也就是说,我们必须要使用寄存器(不能使用锁存器,只能使用触发器寄存器)来保存从存储器取出的指令。
流水线的三种冒险
冒险分类
- 结构冒险
- 指令重叠执行时,发生硬件资源冲突
- 数据冒险
- 几条指令重叠执行时,一条指令依赖前面指令的结果却没有准备好(还没有计算或存储)
- 控制冒险 :(流水线上执行转移指令时)
- 进入下一个时钟周期取指令时,转移条件和转移PC是不可用的。
停顿流水线
- 解决冒险最简单的方式就是停顿流水线
- 停顿意味着为某些指令暂停流水线一个或多个时钟周期。
- 一条指令被停顿后,其后的所有指令被停顿;该指令之前的指令必须继续执行。
- 一个流水线停顿也称为流水线气泡或气泡。
- 停顿时,没有任何新的指令被取到流水线。
结构冒险
原因:硬件资源冲突
解决:可以增加硬件资源或者功能部件完全流水,否则,只有停顿流水线(Stall)
数据冒险
原因:几条指令重叠执行时,一条指令依赖前面指令的结果却没有准备好(还没有计算或存储)
解决方法:寄存器堆WB先写ID后读,Forwarding 通路(寄存器中的结果“转发”到流水线部件中,多加一条pipeline),软件调度;否则就必须停顿(硬件阻塞stall/软件插入nop指令)
控制冒险
原因:转移指令取指令后进入下一个时钟周期时,转移条件和转移目标地址不能按时提供给IF段取下一条指令;计算转移目标地址要花时间;对于条件转移,转移条件分析要花时间计算。控制冒险引起MIPS流水线的性能损失,比数据冒险大得多
解决方法:提早计算目标地址和条件,冻结或冲刷流水线,预测转移未选中,预测转移选中,转移延迟
转移未选中/选中的问题:流水线按照假定的转移方向执行,通常,选择方向是正确的,可以节省时钟周期;偶尔,选择是错误的。结论:开始执行选择错误的指令,要修复,则必须确认这些错误指令没有真正执行;尤其是,必须保证错误指令没有改变机器状态。
冻结或冲刷流水线(硬件固定):较早的一种流水线处理方法。优点:软件和硬件两方面都比较简单。在转移目标地址确定前,保持或者删除转移指令后进入流水线的指令。 性能损失是固定的,不能通过软件来减少。
转移延迟:好的方面,正好1个周期计算出正确的转移地址。因此,不需要2或3个周期的NOP或 NOP or stall;不如意的方面,总是有1 cycle,总是要等待(如果没有采用措施)。在MIPS,无论转移是否发生,这个周期的指令总是要执行
总结:控制冒险比数据冒险会引起更大的性能损失。 通常,流水线越深,在时钟周期上转移损失越大。 CPI更高的处理器,会付出更高的转移代价。 预测机制的有效性取决于转移预测的准确性
流水线处理机的指令系统
流水线指令系统与格式
| 31 26 |
25 21 |
20 16 |
15 5 |
4 0 |
指令 |
意义 |
| 00 0000 |
rd |
rs1 |
rs2 |
and rd ,rs1,rs2 |
寄存器与寄存器 |
|
| 00 0001 |
rd |
rs1 |
imme |
andi rd,rs1,imme |
寄存器与立即数 |
|
| 00 0010 |
rd |
rs1 |
rs2 |
or rd,rs1,rs2 |
寄存器或寄存器 |
|
| 00 0011 |
rd |
rs1 |
imme |
ori rd,rs1,imme |
寄存器或立即数 |
|
| 00 0100 |
rd |
rs1 |
rs2 |
add rd,rs1,rs2 |
寄存器加寄存器 |
|
| 00 0101 |
rd |
rs1 |
imme |
addi rd,rs1,imme |
寄存器加立即数 |
|
| 00 0110 |
rd |
rs1 |
rs2 |
sub rd,rs1,rs2 |
寄存器减寄存器 |
|
| 00 0111 00 1000 00 1001 |
rd |
rs1 |
imme imme imme |
subi rd,rs1,imme load rd,imme(rs1) store rd,imme(rs1) |
寄存器减立即数 从存储器读数据 向存储器写数据 |
|
| rd |
rs1 |
|||||
| rd |
rs1 |
|||||
| 00 1010 00 1011 00 1100 |
disp disp disp |
bne disp beq disp branch disp |
结果非0时转移 结果为0时转移 无条件转移 |
|||
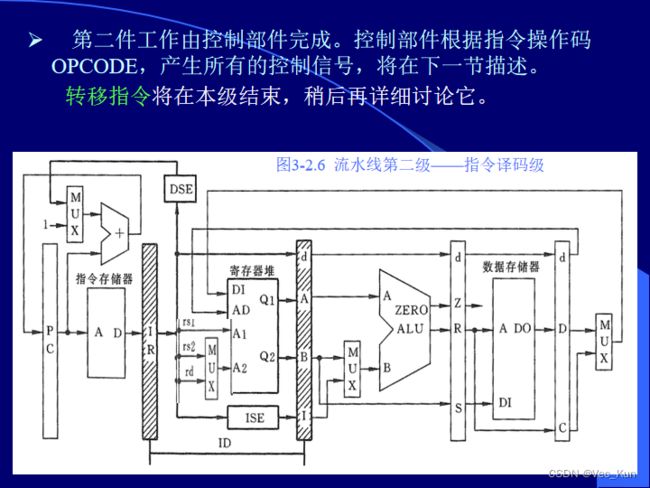
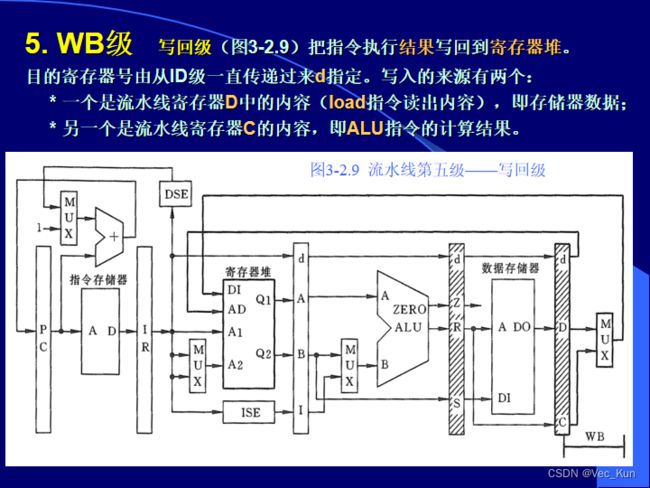
流水线各级间的寄存器作用(看图理解)




流水线各级的操作(看图理解)








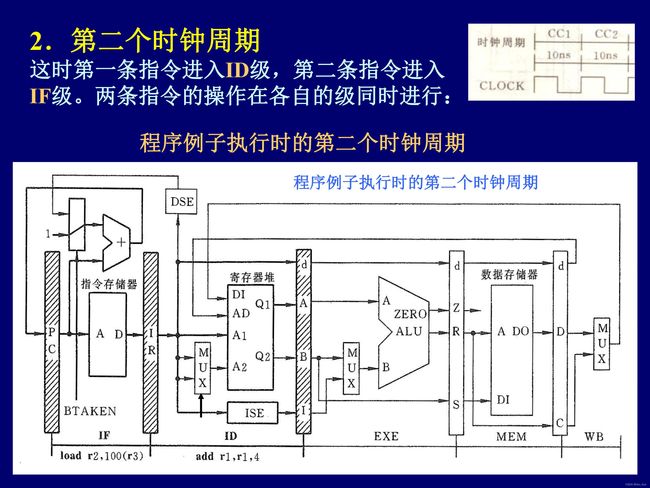
无相关流水线模型机多条指令执行过程(一例,看图理解)





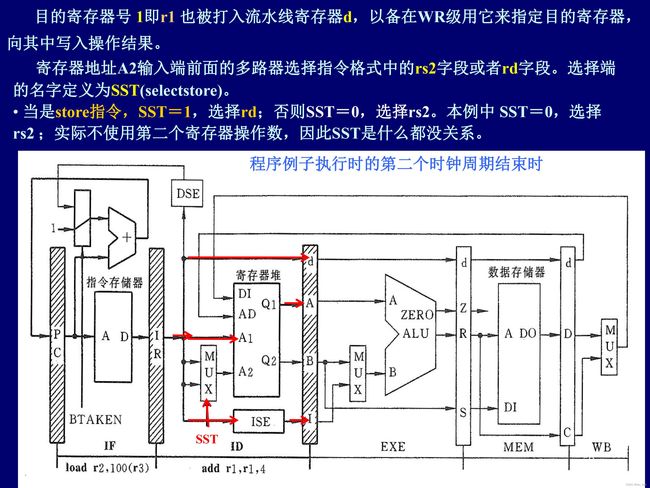













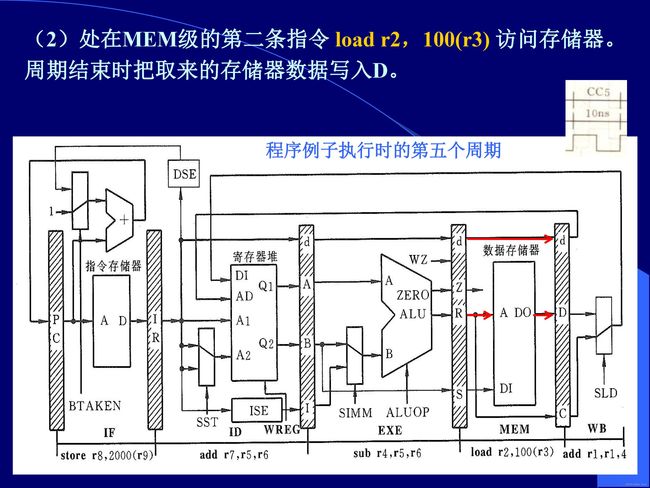
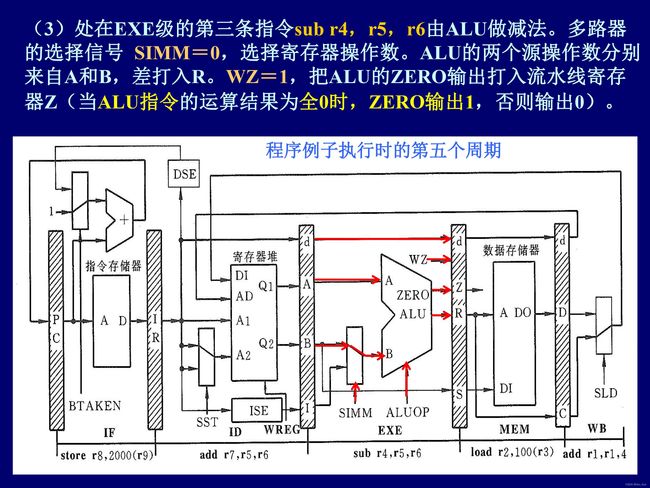






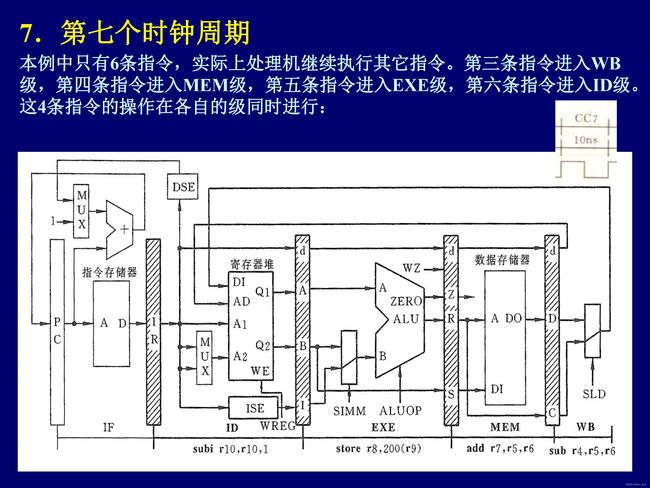









流水线控制信号

流水线各级控制信号的定义:
| 流水线级 |
控制信号 |
注释 |
| IF级 |
BTAKEN |
转移发生 |
| ID级 |
SST |
选择store(rd) |
| EXE级 |
SIMM |
选择立即数 |
| ALUOP |
ALU操作码 |
|
| WZ |
写Z标志 |
|
| MEM级 |
WMEM |
写存储器 |
| WB级 |
SLD |
选择load |
| WREG |
写寄存器堆 |


数据前推与load前推
解决相关最简单的方式就是停顿流水线: 软件方式:由编译器在相关指令之间插入nop 硬件方式1:由逻辑电路在ID级检测相关,有相关则禁止改变PC和IR、封锁写信号暂停流水线一个或多个时钟周期(互锁)。但是,暂停流水线两个或一个周期造成了处理机性能的损失。
为了避免,采用内部前推(Forwarding),能完全避免ALU指令相关而造成的流水线停顿。处理load指令——暂停与内部前推相结合,也就是数据前推与load前推。
数据前推
数据相关本质:一条指令执行时要用到上面指令的计算结果,但这个结果尚未被写入寄存器堆。而实质上,此时结果已经由ALU计算出来了,在流水线寄存器R和C中。
由此,我们可以想到将ALU的计算结果直接拿过来用!在ALU的两个数据输入端各加一个多路器,使R和C中的数据能被直接送到ALU的输入端,这就是所谓的内部前推(internal forwarding)技术。也称为采用专用数据相关通路。

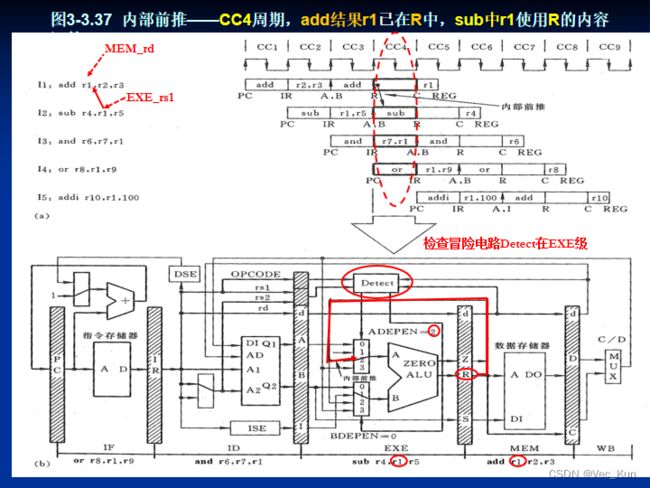

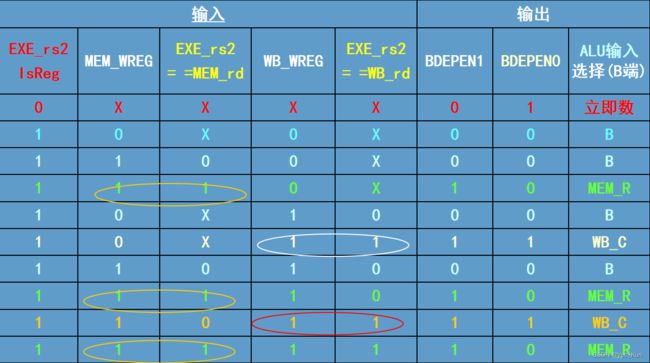
ADEPEN---EXE级指令的rs1与前面指令rd相关
BDEPEN---EXE级指令的rs2与前面指令rd相关
ALU A端(ADEPEN)多路器选择信号的输出真值表

ALU B端(BDEPEN)多路器选择信号的输出真值表
load前推
ALU指令在EXE级结束后,结果就出现在流水线寄存器R中,后续指令可以通过内部前推电路来直接使用它。load指令在EXE级结束后,还在忙着访问存储器。在MEM级结束后,结果才出现在流水线寄存器D中。这时,即使使用内部前推技术也无法消除load指令与它的下一条相关指令之间的第一个“气泡”。
两种方法
软件方法:由编译器处理。当一条指令与它上面的load指令数据相关时,在它们中间插入两条nop指令,然后优化,用两条不相关的指令替换两条nop指令。替换一条是一条,替换不掉就保留nop指令。
硬件方法:由硬件负责检测与load指令的相关性。采用暂停流水线一个周期的方法消除第一个“气泡”。第二个“气泡”用内部前推技术加以消除。
Tips: 两条紧挨着的指令产生load冒险才需要load前推,否则可以直接用内部前推处理。
多一个选择信号LOADDEPEN 。。。(不管了应该不考)
相关(冒险)小结

流水线异常与浮点流水线
流水线异常
另外一种控制冒险:异常
异常(Exception)事件是指在程序执行过程中,由于操作非法,例如除数为0,结果上溢等,或者用户程序试图执行去处理异特权指令等。这时处理机应该转向特定的程序常事件
处理的方法一般是先向用户报告哪条指令引起了异常事件以及引起了何种异常事件,然后继续用户程序的执行,或者结束用户程序的执行,返回到操作系统。
异常就是中断正常程序执行的异常事件
本节所指的异常是广义异常,包括了中断和狭义上的异常。
异常原因
- I/O 外设请求
- 用户 OS
- 服务请求
- 断点
- 整数算术运算溢出
- 浮点算术异常
- 缺页
- 未对齐的存储器访问
- 违反了存储器保护权限
- 硬件故障
- 未定义指令
异常可能的阶段

停止和重新开始执行(MIPS)
- 第一步:强制一个trap指令进入流水线
- 第二步:禁止异常指令及后面指令的所有写操作,直到trap指令流出流水线 目的:避免后续指令改变机器出错时的状态
- 第三步:当trap指令开始执行,唤醒OS ,OS保存异常指令的PC值
- 第四步:OS处理异常,然后重新执行出错指令 PC←出错指令的地址 重新执行出错指令
精确中断(精确异常)
如果流水线可以停下来使异常指令之前的指令能正常结束,异常指令之后的指令能重新启动,则称该流水线是精确异常。意味着:
- 异常指令之前的所有指令正常完成
- 异常指令及其后的指令没有改变机器的状态。
在这个模型下,重新执行就很简单了:
- 重新恢复执行异常指令
- 如果它不是一个可恢复执行的指令,则执行下一条指令
非精确中断(非精确异常)
当不同指令执行需要的时钟周期数有多种时,难以实现精确异常。
- 在某条指令产生异常之前,后面的指令可能已经执行完毕
- 例如
- Multiply r1, r2, r3 ; 需 10 cycles
- Add r10,r11,r12 ; 需 5 cycles
- Add指令在Multiply指令前执行完成。 如果Multiply溢出,
- 一个异常将出现在Add指令已经更新了R10值之后。
- 这是由于指令的乱序完成造成的,Add在multiply完成之前执行完毕。
- 异常发生后,要恢复multiply执行前状态很困难,这种情况为非精确异常
精确异常和非精确异常
- 特殊的软件指令保证精确异常
- 处理器若工作在精确异常模式下,运行速度更慢。
- 一般来说,整数操作异常是精确的,而浮点异常一般不是精确的。
经典5段流水线扩展浮点流水线
处理浮点操作的解决方案
- 在1或2个时钟周期完成浮点操作
- 这意味着使用一个慢的时钟
- 可能在FP部件中使用大量的逻辑电路
- 允许更长的操作时延
- EX 级时钟周期可能需要重复很多次直到完成浮点操作
- 可能有多个FP 部件
如果要在整数流水线中增加处理浮点数的功能,先考虑如下结构的流水线:

两个概念
延迟----在上一条指令生成结果之后,下一条指令能正常使用该结果而需等待的周期数
初始间隔----多条指令发射到同一个部件需要间隔的时钟周期数(避免结构冒险) 对于完全流水化的部件来说,初始间隔为1;对非流水线单元,初始间隔总是延迟+1
浮点流水线的写冲突
- 增加写端口数(不采用)
- 稳定状态一般是写一个寄存器
- 检测和插入空周期,使写操作串行化
- 在ID阶段跟踪写端口的使用
- 如果检测到写操作冲突,则在ID阶段之后就插入空周期
- 空周期的插入可能会加重数据冒险
- 所有的检测功能和空周期插入操作都在ID级进行
- 如果将检测的时机改为MEM阶段或WB阶段?
- 容易实现冲突检测
- 复杂化了流水线的控制,因为插入空周期可能发生在两处
浮点流水线数据相关
- RAW( Read after write) 真相关 true dependence
- 指令 A 写Rx,指令 B 读 Rx(先读后写)
- B 试图在A写一个寄存器之前读它,得到旧的值。这种冲突经常发生,forwarding(前推)可以帮助解决RAW
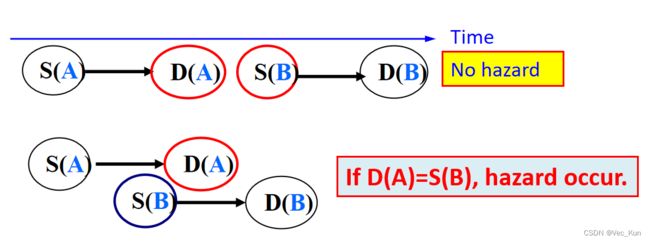
- S表示源操作数;D表示目的寄存器
- WAW(Write after write) 输出相关 output dependence
- 指令 A 写Rx,指令 B 写 Rx(写冲突)
- B 试图在A写一个操作数之前写它。在B执行后,寄存器应该是B的结果,但是A的结果取代了B的。这种情况只发生在多于一个流水段写值的流水线,或长度可变的流水线如FP流水线。

- S表示源操作数;D表示目的寄存器
- WAW的另一种处理方法是在ID级,判断该指令要写的寄存器是否与前面已经发射了的指令相同,若相同,则插入空周期。
- WAR( Write after read) 反相关 anti-denpendence
- 指令 A 读Rx,指令B 写 Rx(先写后读)
- B 试图在A读一个寄存器之前写它。这种情况,A使用新(错误)的值。很少发生,因为大多数流水线读值在前写值在后。然而,可能发生在有复杂寻址方式的CPU中,如自增寻址。

以上冒险的命名依据是数据操作必须在流水线上保持的顺序
异常处理
- 忽略这个问题 (imprecise exceptions):快且容易,但如果没有精确异常,难以调试程序。
- 缓存结果延迟提交:保证指令完成之前,CPU不改变任何状态(写寄存器或存储器)。大量中间结果必须缓存(如果需要,还需缓冲forwarding的流水线寄存器)对于不同指令执行时间差异大的情况,实现很困难。
- 历史文件:缓存最近已经改写的寄存器/存储器的原始值。如果异常发生,可以从这个缓存恢复寄存器/存储器的原始值。对于最长执行时间的指令,这个文件必须有足够的项存放每个时钟周期已修改的寄存器
- 未来文件:缓存寄存器或存储器的新值。发生异常之前的指令如果已经完成,就用未来文件的内容更新主寄存器堆或存储器。出现异常时,主寄存器堆或存储器有被中断的精确值
- 保持足够的信息,由陷阱处理程序为异常创建一个精确的序列: 流水线上的指令和对应的PCs必须被保存;在异常发生后,由软件完成执行,最后已执行完成指令之前未完成的所有指令;这种方案用在SPARC系统结构
- 在确认以前完成的指令没有引起异常后,才允许流水线上指令继续。在EXE级的前期,浮点部件必须检测是否发生异常。如果发生异常,暂停流水线以防止其后的指令完成 ,以维护精确中断
本章小结
- 流水线的相关概念
- 流水线定义、流水线冒险及处理
- 流水线分类、时空图与性能分析计算
- 流水线模型机指令系统、无相关流水线模型机的设计与实现
- 流水线模型机中的相关处理
- 精确异常、非精确异常
- 浮点流水线的结构、相关问题及处理