计算机图形学复习3
计算机图形学复习0
计算机图形学复习1
计算机图形学复习2
前面讲的画直线、圆以及椭圆等是一维图形的光栅化,就是如何在计算机屏幕上即在一个离散的像素集上表示一个连续的图形。
多边形的扫描转换和区域填充这个问题是怎么样在离散的像素集上表示一个连续的二维图形。
区域填充
区域:指已经表示成点阵形式的填充图形,是象素的集合。
区域填充:对给定的一个区域范围内像素赋予指定产颜色代码。
填充步骤:第一步确定需要填充哪些像素:第二步,用什么颜色来填充。

多边形分类:凸多边形、凹多边形、含内环的多边形;

需要的是满足所有图形的区域填充算法。
主要讲两种,一种是种子填充算法,另一种是扫描线算法
区域的表示
区域有两种重要的表示方法:顶点表示和点阵表示。
顶点表示:也称为几何表示,是用区域的顶点序列来表示区域。
特点:直观、几何意义强、占内存少,易于进行几何变换,但没有明确哪些像素在多边形内,只能用扫描线转换将顶点变为点阵表示.

点阵表示:也称为像素表示,是用位于多边形内的像素集合来刻画多边形。
特点:丢失了许多几何信息,便于帧缓冲表示,适合面着色.首先将区域内的一点赋予指定的颜色,然后将其扩展到整个区域.
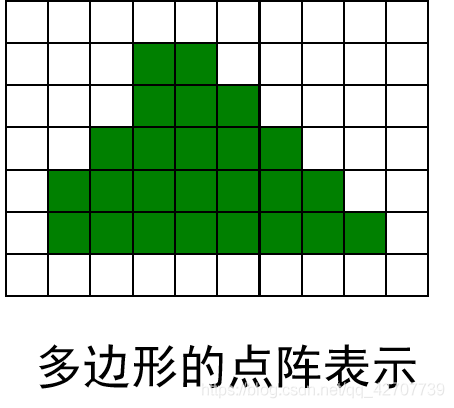
点阵通常有两种情况:内点表示、边界表示
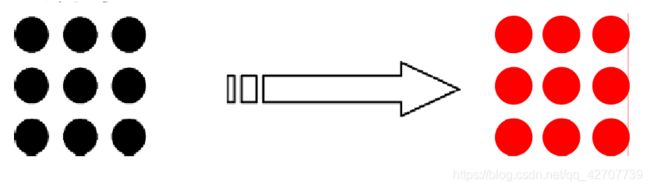
内点表示,称 泛填充
枚举处区域内部的所有像素
内部的所有像素着同一个颜色
区域外像素着另一种颜色
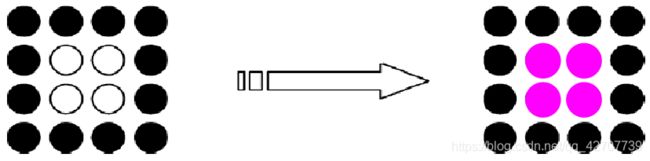
边界表示,称边界填充
枚举出边界上所有的像素
边界上的所有像素着同一颜色
内部像素着边界像素颜色或新颜色

区域的类型
区域填充算法要求区域是连通的;
区域可分为4向连通区域和8向连通区域;
也就是四个方向运动和八个方向运动。

四连通区域和八连通区域:

四向算法和八向算法:
四方向算法:允许从四个方向寻找下一个像素的方法,称为四向算法
八方向算法:允许从八个方向寻找下一个像素的方法,称为八向算法
八向算法可以填充八向连通区域,也可以填充四向连通区域;
四向算法可以填充四向连通区域,但不能填充八向连通区域
对如图所示的区域填充两种不同的颜色:
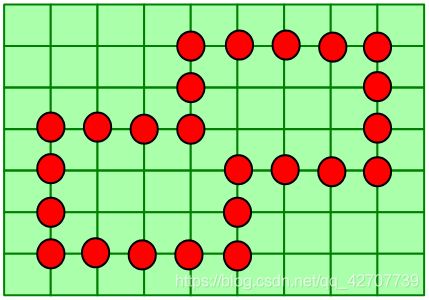

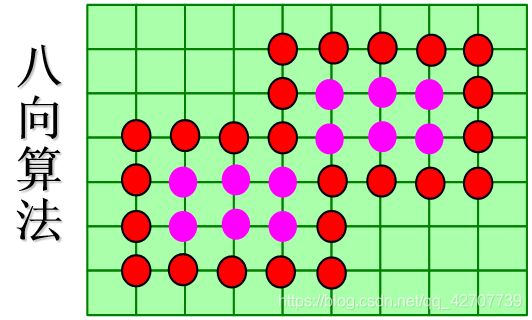
扫描线多边形填充算法
计算机上画图形,实际上就是写帧缓存(frame buffer). 如果知道多边形哪些像素在里面,就直接写到帧缓存里即可;
区域填充:指先将区域的一点赋予指定的颜色,然后将该颜色扩展到整个区域的过程。
多边形有两种重要的表示方法:顶点表示和点阵表示;
对于光栅图形的基本问题是把多边形的顶点表示转换为点阵表示。
也就是从多边形的给定边界出发,求出位于其内部的各个像素,并给帧缓存器内的各个对应单元设置相应的灰度和颜色,这种转换称为多边形的扫描转换。
多边形的扫描转换过程,实际上是给多边形包围的区域着色的过程,是一种面着色的方法。
逐点判断算法
逐点判断是最简单的一种多边形扫描转换方法;
基本思想:逐个窗口内的像素,确定它们是否在多边形之内,从面给出位于多边形内的点的集合;
方法:射线法、编码法、累计角度法等;
算法优点:简单;
算法缺点:计算量太大,速度慢;
射线法(也称累计交点法)
步骤
1.从待判别点v发出射线
2.求交点个数K
3.K的奇偶性决定了点与多边形的内外关系,若交点个数奇数,V点在多边形内部,反之在多边形外部
判断一点是否位于多边形内部?
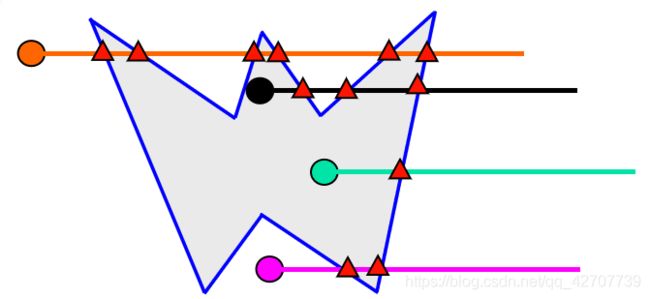
看其于多边形交点的个数。
但是逐点判断算法中会出现一些奇异情况:
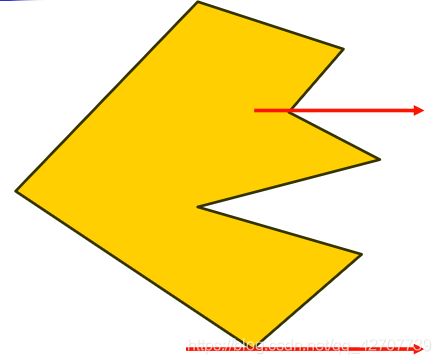
还得重新对点进行特殊的处理。
速度慢:几十万甚是几百万像素的多边形内外判断,大量的求交、乘除运算
没有考虑像素之间的联系
结论:逐点判断算法不可取!
扫描线算法
扫描线算法充分利用相邻像素之间的连贯性,避免了对像素的逐点判断和求交运算,提高了算法效率
基本思想: 按扫描线顺序,计算扫描线与多边形的相交区间再用要求的颜色显示这些区间的象素,即完成填充工作。
如何利用连贯性呢?
多边形连贯性的原理
区域连贯性
区域的连贯性是指多边形定义的区域内部相邻的像素具有相同的性质。例如具有相同的颜色 。
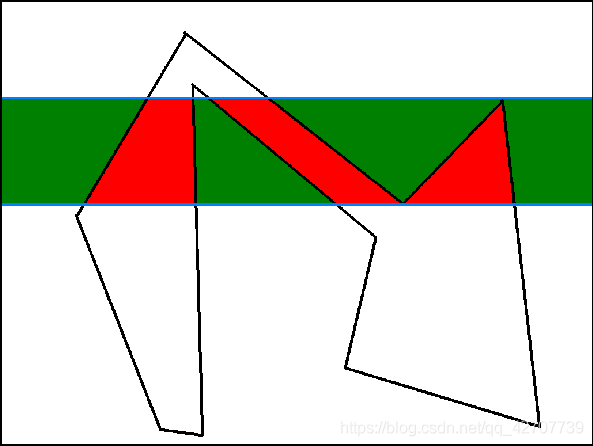
两条扫描线之间的长方形区域被所处理的多边形分割成若干梯形。
梯形分为两类:多边形内部和多边形外部。
两类梯形在多边形内部相间排列。
这样分割的话,也就是说:如果上述梯形属于多边形内(外),那么该梯形内所有点的均属于多边形内(外)。
效率提高的根源:逐点判断—》区域判断
扫描线的连贯性
区域连贯性在一条扫描线上的反映
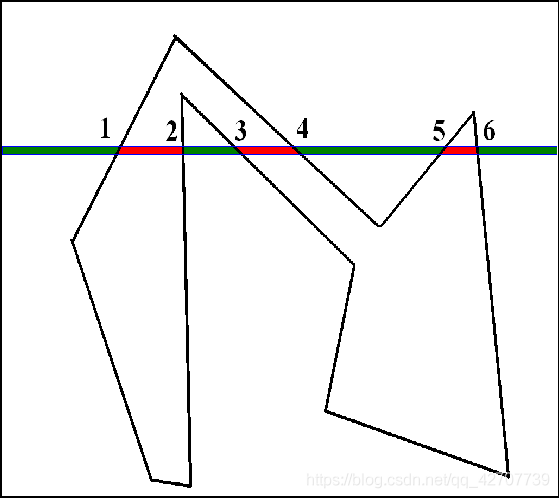
若多边形与一条扫描线相交, 由区域连通性可得该交点序列的性质:
交点数目为偶数;
相邻交点间的线段分为两类:一类是线段上所有点均在多边形内部;一类是线段上所有点均在多边形外部;
两类线段相间排列;
实质:是多边形区域的连贯性在一条扫描线上的反映;而光栅显示器正是按行扫描。
推论:如果上述交点区间属于多边形内(外),那么该区间内所有点均属于多边形内(外)。
效率提高的根源:逐点判断–》区间判断。
边的连贯性——扫描线与边的关系
边的连贯性:直线的线性性质在光栅上的表现
设扫描线与边的交点如图所示:
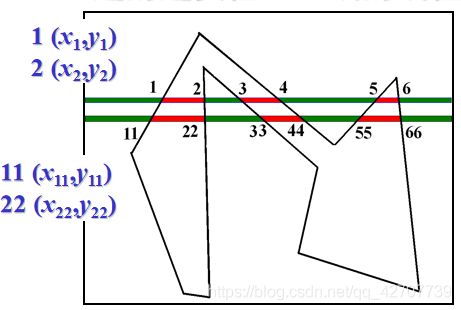
那么相邻扫描线(y1=y11+1)与多边形的同一条边的交点存在如下关系:
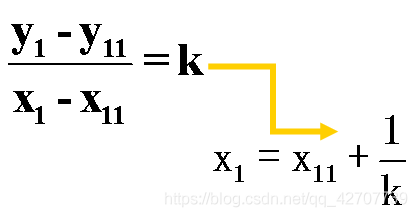
当知道扫描线与一条边的一个交点之后,通过上述公式可以通过增量算法迅速求出其他交点。
边连贯性的实质:是区域的连贯性在相邻两扫描线上的反映;
推论:边的连贯性是连接区域连贯性和扫描线连贯性的纽带。
扫描线连贯性 “+” 边连贯性“=” 区域连贯性
奇异点
奇异点:扫描线与多边形相交于多边形的顶点
奇异点计为几个交点?

扫描线1:一个交点
扫描线2:两个交点
奇异点的分类
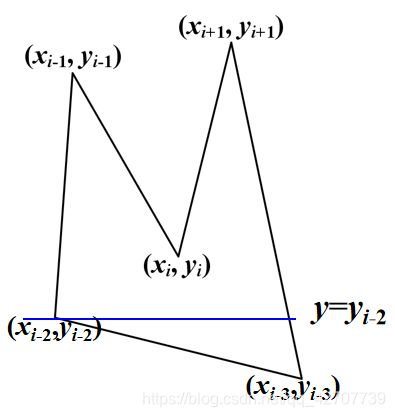
非极值点:相邻三个顶点的y坐标满足如下条件:
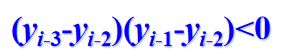
即相邻三个顶点位于扫描线的两侧。
交点按1个计算。
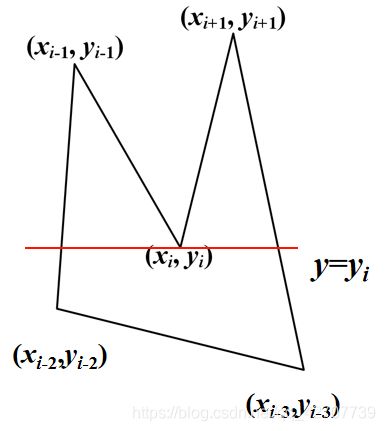
极值点:
相邻三个顶点的y坐标满足如下条件:
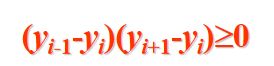
即相邻三个顶点位于扫描线的同一侧
当奇点在多边形两边的下方时,交点按2个计算
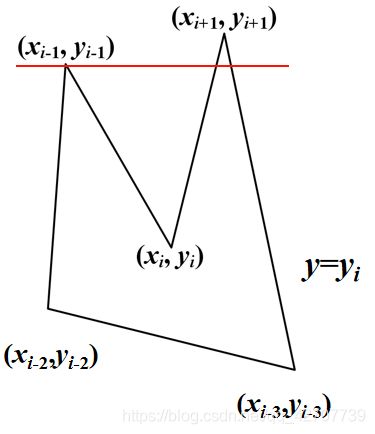
当奇点在多边形两边的上方时,交点按0个计算
对奇异点的处理:
在极值点处,按2个或0个交点计算
在非极值点处,按1个交点计算
实际计算前,奇异点(非极值点)的预处理
将扫描线上方线段截断一个单位,这样扫描线就只与多边形有一个交点。

扫描转换算法采用上开下闭的原则(解决扩大化问题)
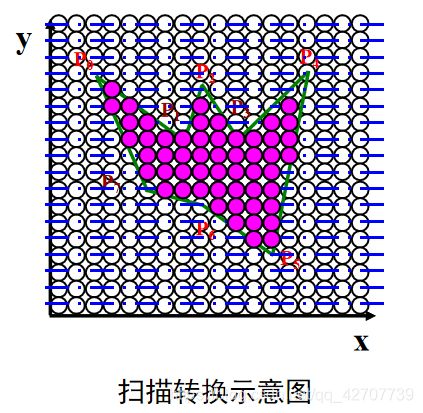
这里涉及到一个边界点像素的填充问题:如下:
例,对左下角为(1,1), 右上角为(3,3)的正方形填充。
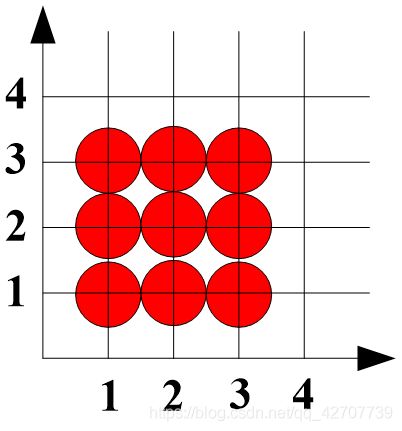
若对边界上所有的像素进行填充,则得到如图所示的结果;
填充后的面积为3×3,而实际面积只有2×2——填充扩大化问题;
解决方法: 规定落在右/上边界的像素不予填充; 而落在左/下边界的像素予以填充;
填充扩大化问题的解决:
扫描线与多边形的顶点相交区间取左闭右开-》解决了左右扩大化问题;
如何解决上下扩大化问题?—上开下闭原则
当扫描线与多边形的顶点相交,顶点是极值点时,交点计为2个。
为了解决填充扩大化问题,当极值点是多边形局部最高点时,交点计0个。
扫描转换算法的核心思想
核心思想(从下到上扫描)
计算扫描线 y = ymin与多边形的交点,通常这些交点由多边形的顶点组成
根据多边形边的连贯性,按从下到上的顺序求得各条扫描线的交点序列
根据区域和扫描线的连贯性判断位于多边形内部的区段
对位于多边形内的直线段进行着色
对于一条扫描线,多边形的填充过程可以分为以下四个步骤:
求交:计算扫描线与多边形各边的交点;
排序:把所有交点按x递增排序;
配对:第一个与第二个,第三个与第四个等,每对交点代表一个相交区间;
填色:把相交区间内的像素置多边形色,相交区间外的像素置背景色。
如何用计算机实现?
如何将信息存放在计算机中?
如何将多边形信息存储起来?(静态的)
如何存放扫描线与多边形的交点信息?(动态的)
如何获取交点?
如果将多边形的所有边放在一个表中, 那么只要顺序取出每条边与扫描线进行求交运算即可。
为了实现上述思想,算法中需要采取灵活的数据结构。
边的分类表ET (Sorted Edge Table):记录多边形信息
边的活化边链表AEL (Active Edge List) :记录当前扫描线信息,按与扫描线交点x坐标递增的顺序存放在一个链表中
它们共同基础是边的数据结构
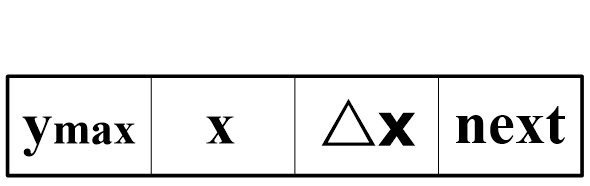
结点的第一个信息:交点的横坐标x

结点的第二个信息:增量△x
结点的第三个信息:边所交的最高扫描线号ymax
那么边的数据结果如下:
边的数据结构
x:边的下端点x坐标,在活化边链表中,表示扫描线与边的交点的x坐标
dx:x的增量△x,即边的斜率的倒数
ymax:边的上端点的y坐标
next:指向下一条边的指针
边的ET表(边表):
分类表ET是按**边下端的纵坐标y**对非水平边进行分类的指针数组;
**有多少条扫描线,就设多少类;**
同一类中,各边按**x值(x相等时,按Δx值)递增**的顺序排列成行。
非极值点, 可作预处理;
水平边不参与分类。
活化边链表(AEL)——有效边表:
活化链表由与**当前扫描线**相交的边组成
记录了多边形的边沿扫描线的交点序列
根据边的连贯性不断刷新交点序列
基本单元是边(与扫描线相交的边)
与分类边表不同
分类边表记录初始状态——静态
活化边表随扫描线的移动而更新——动态
具体的边表和活化链表我录制了一个bili视频:
多边形的边表和活化链表表示
扫描线算法也称有序边表算法,具有以下特点:
对多边形的每个像素只访问一次;
输入/输出量小;
表结构复杂,且时刻要维护表结构;
对链表要排序;
适合软件实现,不适合硬件实现.
十分复杂,对于此,有人提出了边缘填充算法。
边缘填充算法
思路:利用求余运算代替交点排序、配对、构造填充区间。
原理:象素点颜色值经过偶数次求余运算后保持不变,经过奇数次求余运算后变为其余数
分类:边填充算法,栅栏填充算法
边填充算法
基本思想:
对于每条扫描线和每条多边形边的交点(xi,yi), 将该扫描线上交点的右方所有象素求余运算(取补);多边形的顺序任意;
当所有的边处理之后,按扫描线顺序读出帧缓冲器的内容,送入显示设备;
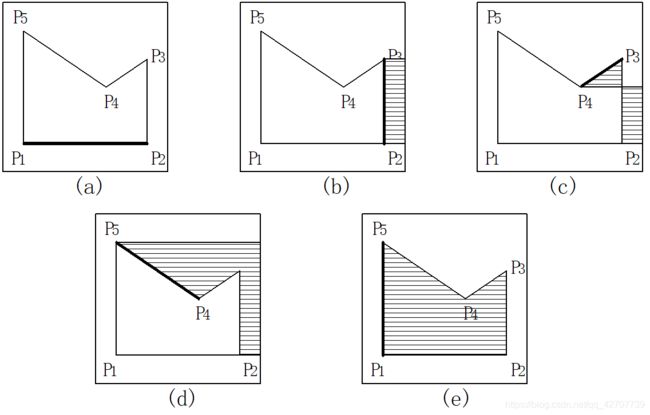
边填充算法的优缺点:
优点:
最适合于有帧缓存的显示器
可按任意顺序处理多边形的边
仅访问与**该边**有交点的扫描线上**右方**的像素,算法简单
缺点:
对复杂图形,每一像素可能被访问**多次,**输入/输出量大.因此,速度比扫描转换慢;
图形输出**不能与扫描同步**进行,只有全部画完才能打印.
栅栏填充算法
栅栏:是指一条与扫描线垂直的直线;
引入栅栏目的:减少边填充访问像素的次数;
栅栏设置位置:通常取过多边形顶点、且将多边形分为左右两半;
基本思想:
对于每个扫描线与多边形的交点, 将交点与栅栏之间的像素取补;
若交点位于栅栏左边,则将交点之右栅栏之左的所有像素取补;
若交点位于栅栏右边,将栅栏之右交点之左的像素取补.

栅栏填充算法减少了被重复访问的像素的数目,但仍有一些像素被重复访问,对栅栏填充算法进一步改进——边标志算法
边标志算法
边标志算法进一步改进了栅栏算法,使得算法对每个象素仅访问一次;
边标志算法步骤:
第一步:对多边形的每条边进行直线扫描转换,即对多边形边界所经过的像素打上边标志;
第二步:填充
填充方法:
对每条与多边形相交的扫描线,依次从左到右的顺序,逐个访问该扫描线上的像素,对多边形边界所经过的像素打上标志;
使用一个布尔变量inside,若点在多边形内,inside = true;否则, inside= false;
inside的初始值为false, 每当访问被打上标志的点, inside取反;对未打上标志的点,inside值不变;
inside为真,则把该像素置为多边形色。
例子:
扫描线4的像素在填充前后的变化

前:

后:

code:
void edgemark_fill(polydeftype polydef, int color)
{ 对多边形polydef 每条边进行直线扫描转换;
inside = FALSE;
for (每条与多边形polydef相交的扫描线y )
for (扫描线上每个象素x )
{
if(象素 x 被打上边标志)
inside = ! (inside);
if(inside!= FALSE)
drawpixel (x, y, color);
else drawpixel (x, y, background);
}
}
该算法思想简单,实现容易。既不需要求交点、交点排序、边的登记,也不需要使用链表、堆栈等数据结构。
种子填充算法
区域指已经表示成点阵形式的填充图形,它是象素的集合;
区域填充指先将区域的一点(种子)赋予指定的颜色,然后将该颜色扩展到整个区域的过程;
表示方法:内点表示、边界表示;
区域类型:可分为4向连通区域和8向连通区域;
填充算法:四向算法和八向算法。
边界表示的四连通区域:
种子P(x,y),原色oldColor,新颜色newColor,边界色为boundarycolor。
方法:
先判断P(x, y)的颜色,若其值不等于newColor也不等于boundarycolor,则置像素颜色为newColor。
再对其相邻的上下左右四个像素分别作为种子作上述递归处理,直到所有的区域内所有的元素都着newColor 。
四连通区域的算法实现:
种子像素入栈;
栈非空时,重复执行以下三步:
栈顶像素出栈;
将出栈像素置成多边形填充色;
按左、上、右、下顺序检查与出栈像素相邻的四个像素,若其中某个像素不在边界且未置成多边形色,则把该像素入栈。
实例:图中,选E为种子点,执行四向(左上右下)填充算法。填充的顺序是?
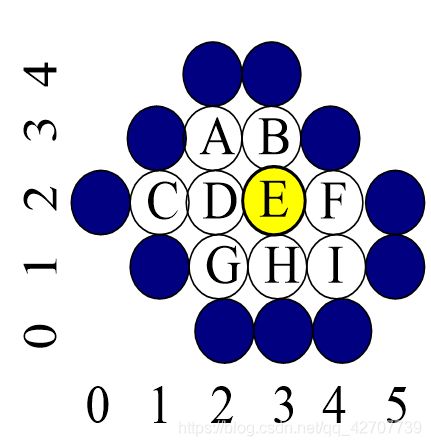

(3,2), (3,1),(4,1),(4,2),(2,1), (2,2),(2,3),(3,3), (1,2), (4,2), (3,3),(2,2)
具体分析方法我放到bili
四向种子填充算法
code:
void BoundaryFill4(int x,int y,int boundarycolor,int newcolor)
{ int color=getpixelcolor(x,y);
if(color!=newcolor && color!=boundarycolor)
{ drawpixel(x,y,newcolor);
BoundaryFill4 (x-1,y, boundarycolor,newcolor);
BoundaryFill4 (x,y+1, boundarycolor,newcolor);
BoundaryFill4 (x+1,y, boundarycolor,newcolor);
BoundaryFill4 (x,y-1, boundarycolor,newcolor);
}
}
可以看到有的种子点被多次填充。可以再起入栈时候着色,减少填充次数。

改进算法步骤如下:
(1) 种子像素坐标入栈并着色。
(2) 当栈非空时,取出栈顶像素坐标;栈空时结束。
(3) 检查出栈像素的左、上、右、下4个相邻像素,如不在边界上或未置区内颜色,则将其坐标入栈并着色,重复(2)、(3)、(4)。
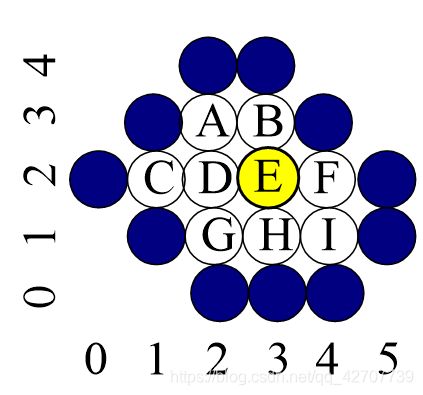
着色顺序为:E D B F H G I A C
改进种子填充算法的特点:
解决像素重复入栈问题
但是,还需一个一个像素进行测试,未考虑像素间的相关性。
降低了算法的效率;
考虑其关联性,提出了改进的种子填充算法----扫描线种子填充算法
扫描线种子填充算法
基本思想: 在任意一条扫描线与多边形相交区间中, 只取一个种子像素, 然后对其左右像素进行填充, 相交区间填充完毕之后, 考查与当前扫描线相邻的上下两条扫描线的情况.
算法步骤:
首先填充种子点所在扫描线上的位于给定区域的一个区段;
然后确定与这一区段相连通的上、下两条扫描线上位于给定区域内的区段, 并依次保存下来。
反复这个过程,直到填充结束。
(1)初始化: 堆栈置空. 将种子点(x,y)入栈;
(2)出栈: 若栈空则结束. 否则取栈顶元素(x,y),以y 作为当前扫描线;
(3)填充并确定种子点所在区段:从种子点(x,y)出发,沿当前扫描线向左、右两个方向填充newcolor色,直到边界. 分别标记区段的左、右端点坐标为xl和xr;
(4) 确定新的种子点:在区间[xl,xr]中检查与当前扫描线y上、下相邻的两条扫描线上的象素. 若存在非边界、未填充的象素, 则把每一区间的最右象素作为种子点压入堆栈,返回第(2)步.
例1:种子点为(7,4),请试着填充事例区域
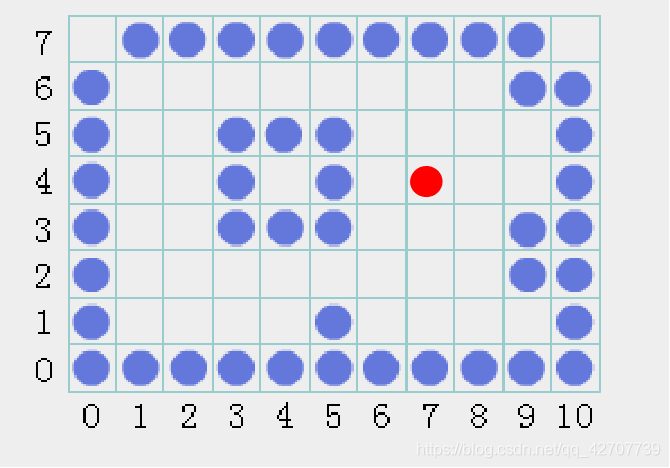
入栈顺序(7,4),(9,5),(8,3),(8,2),(2,3),(4,1),(8,1),(2,4),(2,5),(2,6),(8,5)
出栈顺序(7,4),(8,3),(8,2),(8,1),(4,1),(2,3),(2,4),(2,5),(2,6),(8,5),(9,5)
具体演示视频我上传到bili:
扫描线填充算法演示
算法code:
Typedef struct{
int x;
int y;
} Seed;
Void ScanLineFill4(int x,int y, COLORREF oldcolor, COLORREF newcolor )
{ int xl,xr,i;
bool spanNeedFill;
Seed pt;
setstackempty();
pt.x=x; pt.y=y;
stackpush(pt); //种子入栈
while(!isstackempty())
{ pt=stackpop(); //出栈
y=pt.y; x=pt.x;
While (getpixel(x,y))==oldcolor) //向右填充
{ drawpixel(x,y,newcolor);
x++;
}
xr=x-1;
x=pt.x-1; //向左填充
While (getpixel(x,y))==oldcolor)
{ drawpixel(x,y,newcolor);
x--;
}
xl=x+1;
Typedef struct{
int x;
int y;
}
Void ScanLineFill4(int x,int y, COLORREF oldcolor, COLORREF newcolor )
{ int xl,xr,i;
bool spanNeedFill;
Seed pt;
setstackempty();
pt.x=x; pt.y=y;
stackpush(pt); //种子入栈
while(!isstackempty())
{ pt=stackpop(); //出栈
y=pt.y; x=pt.x;
//处理上面一条线
x=xl; y=y+1;
While(x<xr)
{ spanNeedFill =FALSE;
while(getpixel(x,y)==oldcolor)
{spanNeedFill =TRUE;
x++; //求最右像素作为新的种子
}
if(spanNeedFill )
{ pt.x=x-1; pt.y=y;
stackpush(pt);
}
x++; //解决了隔断问题
}
//处理下面一条线
x=xl; y=y-2;
…….
}
扫描线种子填充算法特点
1、该算法考虑了扫描线上象素的相关性,种子象素不再代表一个孤立的象素,而是代表一个尚未填充的区段。
2、进栈时,只将每个区段选一个象素进栈(每个区段最右边或最左边的象素),这样解决了堆栈溢出的问题。
3、种子出栈时,则填充整个区段。
4、这样有机的结合:一边对尚未填充象素的登记(象素进栈),一边进行填充(象素出栈),既可以节省堆栈空间,又可以实施快速填充。
算法缺点:
对种子所在扫描线的填充与搜索新种子点的操作是分别进行的, 这就需对大量的像素进行重复判读.
为了对当前扫描线填充和搜索新种子像素,需要对当前扫描线以及其相邻的上下扫描线等3 条扫描线进行扫描, 这就使得多数扫描线被重复扫描,即使该扫描线上的像素已经全部填充也要被再次扫描. 甚至扫描3 次, 大大降低了程序的效率和运行速度.
在该算法中堆栈操作频繁,每搜索到一个新的填充区间就要入栈, 每次开始另一条扫描线搜索时都要先出栈, 这不仅占用了大量的存储空间, 还降低了算法的效率.
对算法进行改进的思路可以考虑将其分为凸凹进行分别的快速扫描。如果是凸多边形,可以直接选取最下面为种子点,并且只向上扫描等。
那么会涉及到如何对凸凹多边形进行一个判断。
凹凸多边形的判断
多边形凹凸性的判定

(1) 全部为0,则多边形各边共线。
(2) 一部分为正,一部分为负,则多边形为凹。
(3) 全部大于0或等于0,则多边形为凸,并且沿着边的正向,内法线指向其左侧。
(4) 全部小于0或等于0,则多边形为凸,并且沿着边的正向,内法线指向其右侧。



并且可以将凹多边形分割为多个凸多边形进行计算。
假定简单多边形顶点按逆时针方向给定,以单向链表表示该多边形则算法可描述如下:
1) 求出多边形顶点中的所有凹点。
2) 从多边形的任一个顶点出发,沿单向链表搜索到第1个凹点vi+1。
3) 从凹点vi+1沿有向边vivi+1作射线,求它与多边形其余各边的交点,取离vi+1最近的交点p1。
4) 沿vi+1p1将多边形一分为二,一个多边形由vi+1, vi+2,…, p1vi+1组成,另一个多边形由vip1及其余顶点组成。
5) 对分割的两个多边形递归地重复以上步骤,直到所有新产生的多边形均为凸,算法结束。
具体涉及到图形学算法,都可以写论文了,这里我就不多说了,主要是如何进行改进的一个思路。
反走样
用离散量表示连续量引起的失真现象称之为走样。
用于减少或消除这种效果的技术称为反走样。
解决反走样的方法:
提高分辨率方法、简单区域采样、加权区域采样
光栅图形的走样现象
阶梯(锯齿)状边界
图形细节失真
狭小图形遗失:动画序列中时隐时现,产生闪烁
阶梯状的图形边界
像素间距大

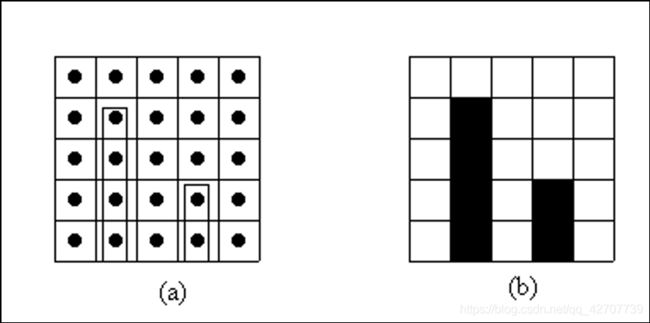
图形细节失真
由于显示图形的最小单位为像素
导致细长的矩形显示后成了加宽的矩形
导致更细的矩形将丢失
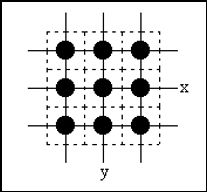
简单区域采样方法
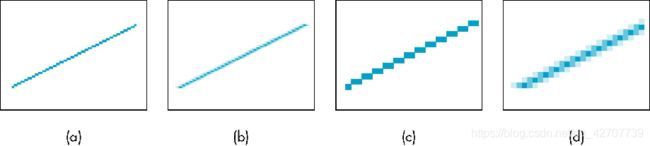
扫描转换线段的两点假设
像素是数学上抽象的点,它的面积为0,它的亮度由覆盖该点的图形的亮度所决定
直线段是数学上抽象直线段,它的宽度为0
现实
像素的面积不为0;
直线段的宽度至少为1个像素;
假设与现实的矛盾是导致走样出现的原因之一。
反走样的解决方法
解决方法:改变直线段模型,线上像素灰度不等
方法步骤
1、将直线段看作具有一定宽度的狭长矩形;
2、当直线段与某像素有交时,求出两者相交区域的面积;
3、根据相交区域的面积,确定该像素的亮度值

方法要点:
直线段对一个像素亮度的贡献与两者相交区域的面积成正比
当直线段和某个像素不相交时,它对该像素的亮度无影响
相同面积的相交区域对像素的亮度贡献相同,而与这个相交区域落在像素内的位置无关
关键在于如何计算相交区域的面积
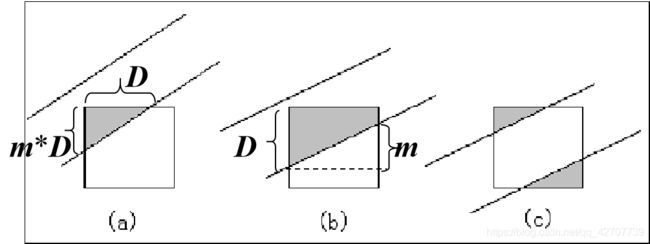
(a)面积=(mDD)/2
(b)面积=D – m/2
像素实际显示的灰度值 = 所得面积 * 该像素的最大灰度值
求相交区域的近似面积的离散计算方法
将屏幕像素分割成 n 个更小的子像素;
计算中心点落在直线段内的子像素的个数,记为 k,
k/n 为线段与像素相交区域面积的灰度近似值
可以简化运算
例如

n = 16, k = 3
则近似面积 = 3/16
字符的生成
字符
字符指类字形单位或符号,包括字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。字符是电子计算机或无线电通信中字母、数字、符号的统称,是数据结构中最小的数据存取单位,通常由8个二进制位来表示一个字符。字符是计算机中经常用到的二进制编码形式,也是计算机中最常用到的信息形式。
字符集
字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集等。
ASCII码,国际标准字符集,是基于罗马字母表的一套电脑编码系统。7位(bits)表示一个字符,共有128字符,字符值从0到127,其中32到126是可打印字符。
GB 2312码,国家标准字符集,共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
字符库
字符库中存储了每个字符的形状信息.分为两大类:点阵字体、矢量字体
点阵字体: 是利用掩膜来定义,并将其写入帧缓存,适合光栅显示器
存储:空间大,分压缩与非压缩两种存储方式
表示:点组成字符,显示整个位图
矢量字体:适合笔式绘图仪
存储:空间少
表示:笔画组成曲线,由编码表示
字符生成方法
1、点阵字符生成算法
2、矢量字符生成算法
点阵字符
点阵字符的存储
点阵字符将字符形状表示为一个矩形点阵;
点阵中值为1表示字符的笔画经过此位,对应于此位的像素应置为字符颜色;
点阵中值为0表示字符的笔画不经过此位,对应于此位的像素应置为背景颜色;
常用的点阵大小有5×7,8×8,16×16等
。

每一行是8个点就是两个16进制数字,上面的B16进制存储如下:
FC 66 66 7C 66 66 FC 00
占8个字节
点阵字符输出
从字库中将字符的位图检索出来;
将检索到的位图信息写到帧缓冲器;
通过画点将字符写出来;
也可以通过掩膜的修改来达到字符在屏幕上显示的改变
//CDC类是一个设备上下文类,CDC对象提供处理显示器上下
文的成员函数,GetDC() 函数:获取设备指针 //
CDC *pDC=GetDC();
byte r[8]={0xFC,0x66,0x66,0x7C,0x66,0x66,0xFC,0x00};
for(y=0;y<=7;y++)
{
for(x=0;x<=7;x++)
{ d=1<<(7-x);
if((r[y] & d)= =d) //获取字符点位信息
pDC->SetPixel(x+x0,y+y0,RGB(0,0,0));
//指定字符掩膜的原点(0,0)与帧缓存中的字符左下角位置(x0,y0)对应
}
}
如图3-37所示: (b)©(d)列出了字母P原型(a)的变化例子,相应的变换算法有:
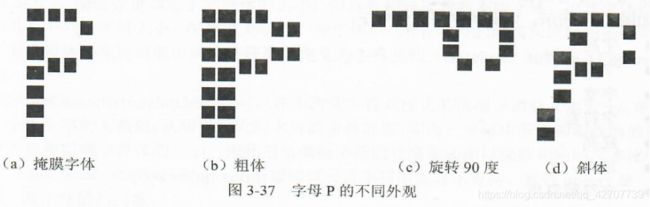
粗体字:当字符原型中每个像素被写入帧暂存寄存器的指定位置(xi,yi)时,同时被写入(xi+1,yi);
旋转90o:把字符原型中每个像素(x,y)坐标彼此交换,并使y值改变符号后,再写入帧暂存器的指定位置。
斜体字:从底到顶逐行复制字符,每隔n行,右移一单元。
矢量字符
矢量字符记录字符的笔画信息而不是整个位图;
它具有存储空间小、美观、变换方便等优点;
对于字符的旋转、缩放等变换非常方便。
点阵字符的变换需要对表示字符位图中的每一像素进行;
而矢量字符的变换只要对其笔画端点进行变换就可以了。
矢量字符的端点存储方式
定义字符:
首先在局部坐标系下写字模(如图所示);
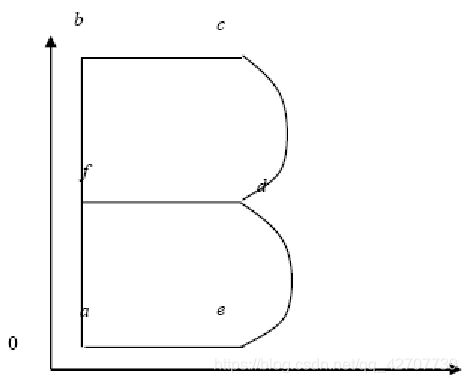
然后确定字符代码、字符各笔划坐标、划线标志(例如0为移动、1为画线、2为画曲线,且各笔划坐标不等于这三个值)和结束标志(-1)等
具体演示我上传到bil
点阵字符和矢量字符
从原点开始, 移到a(10,10), 画线到b(10,110), 画线到c(60,110), 画曲线到d(60,60)[中间控制点为(80,85)], 画曲线到e(60,10)[中间控制点为(80,35)], 画直线到a(10,10), 移到f(10,60), 画线到d(60,60), 结束。
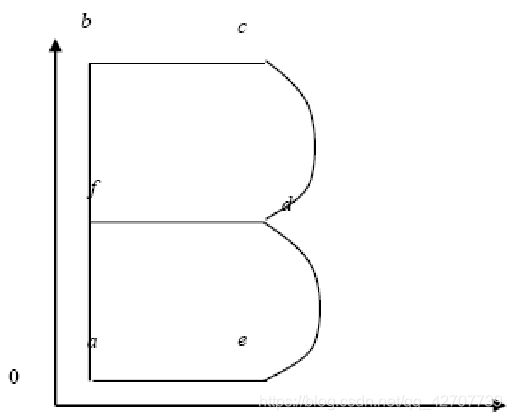
矢量字B的存储内容如下:0,10,10,1,10,110,1,60,110,2,80,85,60,60,2,80,35,60,10,1,10,10,0,10,60,1,60,60, -1
矢量字库的存储
在矢量字符库中,要存放许多矢量字的笔划,因此必须对每个字符进行编码,并且要记录每个字符的起始位置;
矢量字库的文件结构可设计如下:
0-m字节为文件头,主要存放每个字符的编码(2个字节)与笔划坐标起始位置(2个字节),m的取值取决于字库中应存的最大字符个数。
m+1以后的字节存放每个字符的笔划,一个坐标值或一个标志占一个字节。
例如:存放A与B两个矢量字符笔划时,字库内容如下:
65,1,66,17,… //(文件头)
0,10,100,1,50,10,1,100,100,0,30,55,1,75,55, -1, 0,10,10,1,10,110,1,60,110,2, 60,110,80,85,60,60,2, 60,60,80,35,60,10,1,10,10,0,10,60,1,60,60,-1
对于矢量字符不同的曲线的绘制不一样。
曲线笔划的绘制
移动与绘制直线比较简单;
对于过三点绘制曲线,可使用二次参数曲线(抛物线)。
设二次参数曲线方程为:
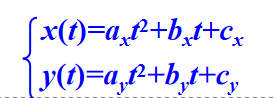
已知过抛物线三个点坐标(x1,y1),(x2,y2),(x3,y3),其中(x1,y1)是起点,(x3,y3)是终点,则可推出上式的六个系数:
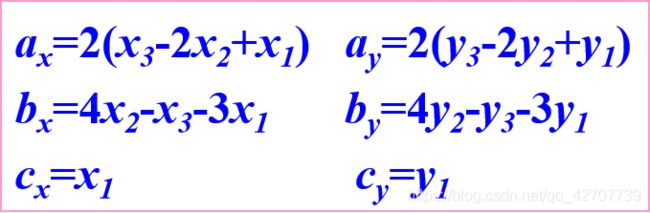
矢量字库的显示
设矢量字符B的笔划存在数组中,字符显示的主要VC程序:
CDC *pDC=GetDC();
int bh[]={0,10,10,1,10,110,1,60,110,2, 60,110,80,85,60,60,2, 60,60,80,35,60,10,1,10,10,0,10,60,1,60,60,-1},i=0;
while(bh[i]!=-1)
{
//循环体,绘制并显示字符
}
if(bh[i]==0) //移动
{ pDC->MoveTo(bh[i+1]+x0,bh[i+2]+y0);
i=i+3; //移动存储占3个单位长度,
}
else if(bh[i]==1) //画线
{pDC->LineTo(bh[i+1]+x0,bh[i+2]+y0);
i=i+3; //绘制直线的存储占3个单位长度
}
else
if(bh[i]==2) //画曲线
{ax=2.0*(bh[i+5]-2*bh[i+3]+bh[i+1]);
ay=2.0*(bh[i+6]-2*bh[i+4]+bh[i+2]);
bx=4.0*bh[i+3]-bh[i+5]-3*bh[i+1];
by=4.0*bh[i+4]-bh[i+6]-3*bh[i+2];
cx= bh[i+1]; cy= bh[i+2];
pDC->MoveTo(bh[i+1]+x0,bh[i+2]+y0);
for语句;//绘制过已知三点的抛物线
for(t=0.05;t<=1.0001;t=t+0.05)
//绘制过已知三点的抛物线
{x=ax*t*t+bx*t+cx;
y=ay*t*t+by*t+cy;
pDC->LineTo(x+x0,ye+y0);
}
i=i+7; //绘制曲线的存储占7个单位长度
} //画曲线终
矢量字符的方向编码存储方式

介绍AutoCAD系统使用的矢量字符存储方式,它的主要思路是存储字符每一笔划的方向及长度。
具体绘制北字演示我上传到了bili:
“北”字的绘制
方向编码如图所示:
注意:为了处理方便,所有矢量都定义为“相同”的长度(实际上,不同方向的矢量的长度是不一样的)
如0、1、2方向的单位长度的X值相同,2、3、4方向的单位长度的Y值相同,1方向单位长度的Y值与3方向单位长度的X值都是1/2。
“北”字的编码“0x长度方向”如下:


轮廓字形技术
直接使用点阵式字符方法将耗费巨大的存储空间。使用压缩技术解决这个问题。
压缩方法有多种,最简单的有黑白段压缩法。另一种方法是部件压缩法。三是轮廓字形法,这种方法压缩比大,且能保证字符质,是当今国际上最流行的一种方法。
轮廓字形法**采用直线、或者二次Bezier曲线、三次Bezier曲线的集合来描述一个字符的轮廓线。**轮廓线构成一个或若干个封闭的平面区域。轮廓线定义和一些指示横宽、竖宽、基点、基线等的控制信息,就构成了字符的压缩数据。
这一期就更到这里吧,内容比较多,下一期介绍图形裁剪算法。再分享一些例题
边填充算法中是将扫描线与多边形交点左方的所有像素取补。
正确答案:错 是右方
关于一个一般多边形的填充过程,对于一条扫描线通常不需要做下列几项中的哪一步?
A、求交
B、筛选
C、区间填充
D、交点配对
正确答案:B 求交,排序,配对,填色。
下面关于反走样的论述错误的是( )
A、 提高分辨率
B、简单区域采样
C、增强图像的显示亮度
D、加权区域采样
正确答案:C 提高分辨率,简单区域采集,加权区域采样都是反走样的方法。
种子填充算法中,正确的叙述是( )
A、它是按扫描线的顺序进行象素点的填充
B、四连接算法可以填充八连接区域
C、四连接区域内的每一象素可以通过上下左右四个方向组合到达
D、八连接算法不能填充四连通区域
正确答案:C
在用射线法进行点与多边形之间的包含性检测时,下述哪一个操作不正确? ( )
A、当射线与多边形交于某顶点时且该点的两个邻边在射线的一侧时,计数0次
B、当射线与多边形交于某顶点时且该点的两个邻边在射线的一侧时,计数2次
C、当射线与多边形交于某顶点时且该点的两个邻边在射线的两侧时,计数1次
D、当射线与多边形的某边重合时,计数1次
正确答案:D
什么是扫描转换?
答:如何确定用最佳逼近图形的像素集合,并用指定的属性写像素,这一过程称为图形的扫描转换。
什么是走样?常见的走样现象有哪些?常用的反走样技术有哪些?
答:走样现象:用离散量表示连续量引起的失真现象称之为走样。
常见的走样现象有:阶梯(锯齿)状边界、图形细节失真、狭小图形遗失等。
常用的反走样技术有:提高分辨率、区域采样、加权区域取样等
具体网上一些计算题答案都给错了,我后面录制视频了讲解上传上来再更新。