Spring-Data-JPA 使用入门
文章目录
- Spring-Data-JPA 使用入门
- JPA规范
-
- Entity
- EntityManager
- EntityManagerFactory
- EntityTransaction
- Spring-Data-JPA
-
- JPA基本查询
- 自定义简单查询
- 自定义SQL查询
- JPQL
- 复杂关联
- Spring-Data-JPA增强
Spring-Data-JPA 使用入门
Spring-Data-JPA是Spring-Data下的一个子模块,是Spring基于hibernate、JPA规范的基础上封装的一套JPA框架。在配置好Spring-Data-JPA后,编写domain、编写Dao接口继承JpaRepository定义即可在service中进行数据库操作,使得开发人员的开发效率大大提高,接下来我们就对使用Spring-Data-JPA的需要掌握的基本知识做一个简单介绍。
JPA规范
JPA是Java持久化API,是用于管理实体和数据库的一套编程接口规范,使用JPA,首先必须了解一下JPA规范中的主要概念:
Entity
一个Entity类通常与数据库的一张表进行对应,它的一个实例表现为数据库的一条数据,生命周期包含初始、托管、游离、删除几个状态。
EntityManager
EntityManager是对Entity进行操作的主要对象,它的一个实例代表一个数据库连接,可以通过EntityManagerFactory获取实例,也可以通过@PersistenceContext注入,每个线程应该拥有自己的EntityManager实例。
EntityManagerFactory
创建EntityManager的工厂,可以使用@PersistenceUnit注入。
EntityTransaction
表示数据库事务,可以通过EntityManager.getTransaction()方法获取。
Spring-Data-JPA
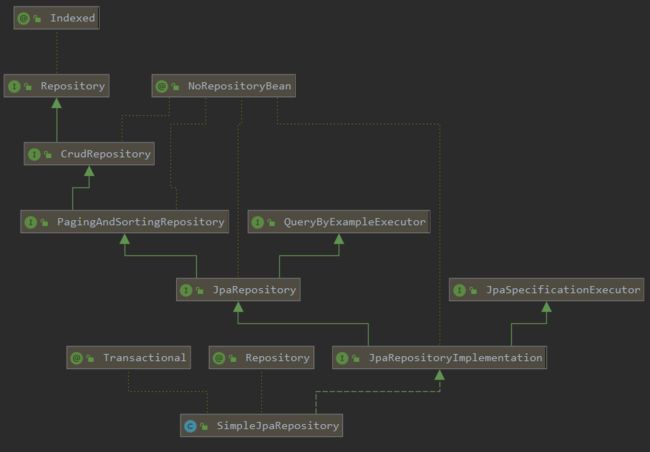
JPA作为一个规范协议,它拥有apache的OpenJPA,hibernate等框架实现,而Spring-Data-JPA则针对JPA规范进行了再次封装抽象,它的底层则使用了Hibernate的技术实现。SpringDataJPA针对JPA规范提供了JpaRepository接口和SimpleJpaRepository实现,它们的类图如下:
JPA基本查询
Repository是Spring Data提供的访问底层数据模型的超级接口,CrudRepository、JpaRepository等通过层层继承提供了一些默认的基本操作方法,例如:save、delete、findAll、findById、findOne等。
自定义简单查询
除了默认的基本方法,使用者还可以定义接口继承JpaRepository接口,并根据方法名规则添加方法名来自定义简单查询,让JPA根据方法名来自动生成SQL,主要语法为数据库操作动词+全局修饰+By+实体属性名称+限定词+连接词+(其他实体属性)+OrderBy+排序属性+排序方向(各部分可以自由组合):
BaseUser findByUserId(String userId);
BaseUser findByUserIdAndUserName(String userId, String userName);
修改、删除、统计等也是类似的语法,其中关键字和属性名可以嵌套组合,具体的关键字,使用方法和生成的SQL如下表所示:
| 关键字 | 例子 | SQL |
|---|---|---|
| And | findByUserIdAndUserName | where x.userId=?1 and x.userName=?2 |
| Or | findByUserIdOrUserName | where x.userId=?1 or x.userName=?2 |
| Is, Equals | findByUserIdIs, findByUserIdEquals | where x.userId=?1 |
| Between | findByAgeBetween | where x.age between ?1 and ?2 |
| LessThan | findByAgeLessThan | where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | where x.age<= ?1 |
| GreaterThan | findByAgeGreaterThan | where x.age> ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | where x.age>= ?1 |
| After | findByCreateTimeAfter | where x.createTime > ?1 |
| Before | findByCreateTimeBefore | where x.createTime < ?1 |
| IsNull | findByUserNameIsNull | where x.userName is null |
| IsNotNull, NotNull | findByUserName(Is)NotNull | where x.userName is not null |
| Like | findByUserIdLike | where x.userId like ?1 |
| NotLike | findByUserIdNotLike | where x.userId not like ?1 |
| StartingWith | findByUserNameStartingWith | where x.userName like ?1% |
| EndingWith | findByUserNameEndingWith | where x.userName like %?1 |
| Containing | findByUserIdContaining | where x.userId %?1% |
| OrderBy | findByUserIdOrderByUserNameDesc | where x.userId=?1 order by x.userName desc |
| Not | findByUserNameNot | where x.userName <> ?1 |
| In | findByUserIdIn | where x.userId in ?1 |
| NotIn | findByUserIdNotIn | where x.userId not in ?1 |
| TRUE | findByIsActiveTrue | where x.isActive =true |
| FALSE | findByIsActiveFalse | where x.isActive=false |
| IgnoreCase | findByUserIdIgnoreCase | where UPPER(x.userId) = UPPER(?1) |
自定义SQL查询
上述的自定义简单查询已经可以适应大部分的查询场景,对于某些业务场景想使用自定义的SQL来操作数据,SpringData也是支持的,可以在自定义的接口方法上使用@Query注解书写SQL,如果是增删改则还需要添加@Modifying注解。
@Modifying
@Query("delete from Base_User where userId = ?1")
int deleteByUserId(String userId);
@Query("select * from Base_User where userName = ?1")
List<BaseUser> findByUserName(String userName);
JPQL
JPQL是Java持久化查询语言,它是一种可移植的查询语言,旨在以面向对象表达式语言的表达式,将SQL语法和简单查询语义绑定在一起。
JPQL的语法或关键字和SQL语句类似,但是它查询的是类和类中的属性,可以通过@Query或者em.creatQuery使用JPQL查询语句。
@Query(value="from BaseUser where userName = ?1")
public List findJpql(String userName);
em.createQuery("select u from BaseUser u where userName=?1")
复杂关联
复杂查询有三种方式,一种是hibernate级联查询(@OneToOne、@OneToMany、@ManyToMany),一种是创建一个结果集接口来接收连表查询后的结果,以及直接使用entityManager.createNativeQuery来使用原生SQL进行查询。
hibernate级联查询:
// BaseDict.java
@Data
@ToString
@Entity
@Table(name = "base_dict",
indexes = {@Index(name = "idx_dict_pid", columnList = "pid")})
public class BaseDict {
@Id
@Column(name = "id",length = 32,unique = true, nullable = false)
@GeneratedValue(generator = "system-uuid")
@GenericGenerator(name = "system-uuid", strategy = "uuid")
private String id;
@Column(name = "pid" , length = 32)
private String pid;
@Column(name = "seq_no")
private Integer seqNo;
@Column(name = "code_type" , length = 32)
private String codeType;
@Column(name = "base_code" , length = 64)
private String baseCode;
@Column(name = "code_desc" , length = 128)
private String codeDesc;
@OneToMany(cascade = CascadeType.PERSIST, fetch = FetchType.EAGER)
@JoinColumn(name = "pid", foreignKey = @ForeignKey(name="none", value = ConstraintMode.NO_CONSTRAINT))
private Set<BaseDict> children;
}
//DictRepository.java
@Repository
public interface DictRepository extends JpaRepository<BaseDict, String> {
}
结果集接收数据
//DictSummary.java
public interface DictSummary{
String getId();
Integer getChildNo();
}
//DictRepository.java
@Repository
public interface DictRepository extends JpaRepository<BaseDict, String> {
@Query("select pid as id, count(id) as childNo from BaseDict where pid=?1 group by pid")
List<DictSummary> findChild(String pid);
}
NativeQuery
@Service
@Transactional(rollbackFor = RuntimeException.class)
public class DaoServiceImpl implements DaoService{
@PersistenceContext
EntityManager em;
public List<Map<String,Object>> findDict(){
List<Map<String,Object>> retList = em.createNativeQuery("select a.* from BaseDict a.id left join select a. ")
.unwrap(NativeQuery.class)
.setResultTransformer(AliasToEntityMapResultTransformer.INSTANCE)
.getResultList();
return retList;
}
}
Spring-Data-JPA增强
通过上面的介绍,Spring-Data-JPA已经可以适配各种数据库操作场景,但为了应对一套代码适应多种数据库的场景,如果不使用JPQL查询语言,也可以将不同类型数据库的SQL写在daoMapper.xml中,编写对应的DAOHelper来获取SQL,然后配合em.createNativeQuery来实现复杂查询的多数据库支持。