【MySQL进阶】表的增删改查操作(CRUD)+(SQL执行顺序)
- 1. 新增(复制数据)
- 2. 查询 - 进阶
-
- 2.1 聚合查询
- 2.2 group by
- 2.3 having
- 2.4 联合查询
-
- 2.4.1 内连接
- 2.4.2 外连接
- 2.4.3 自连接
- 2.4.4 子查询
- 2.4.5 合并查询
- 3 SQL的执行顺序(where...)
1. 新增(复制数据)
语法
-- 字段名 == 列名
-- 将表2的数据复制到表1中
-- 两张表的结构要一样
insert into 表名1 [(列名,列名..)] select 字段名/列名 from 表名2
create table test_ (id int , name varchar(20));
insert into test_(id,name) select id,name from student;
- 操作的两张表在结构上要一致,才能进行新增复制.
- 上述操作即:将student表中的id,name内容复制到test_表中.
2. 查询 - 进阶
2.1 聚合查询
聚合函数:
| 函数 | |
|---|---|
| COUNT( [ DISTINCT ] expr) | 返回查询的数据的 数量 |
| SUM( [ DISTINCT ] expr) | 返回查询到数据的 总和 ,不是数字没有意义,如:id = 1,id = 5,查询id的总和是 6; |
| AVG( [ DISTINCT ] expr) | 返回查询到的数据的 平均值,不是数字没有意义,如::id = 1,id = 5,查询id的平均值是3 |
| MAX( [ DISTINCT ] expr) | 返回查询到的数据的 最大值,不是数字没有意义. |
| MIN( [ DISTINCT ] expr) | 返回查询到的数据的 最小值,不是数字没有意义. |
语法:
select 函数(列名) from 表名;
案列:
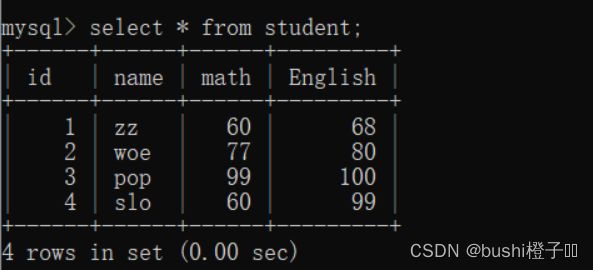
有student表的数据如下:
count()
统计班级有多少同学:
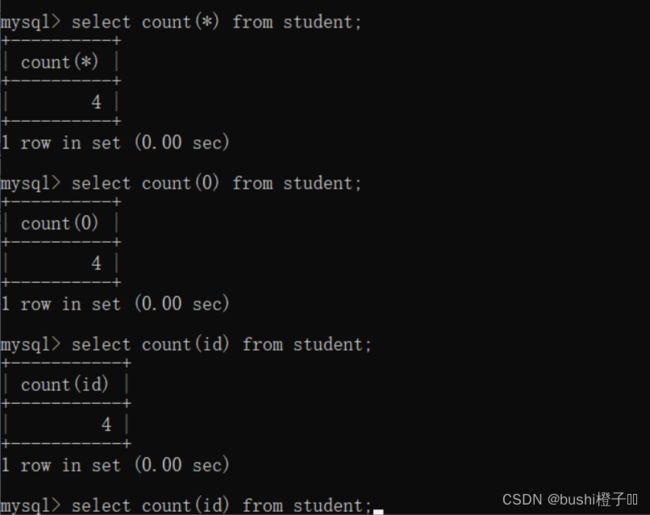
统计班级的math有多少个,math为null不会计入结果
插入一个math和English都为null的数据到student表中
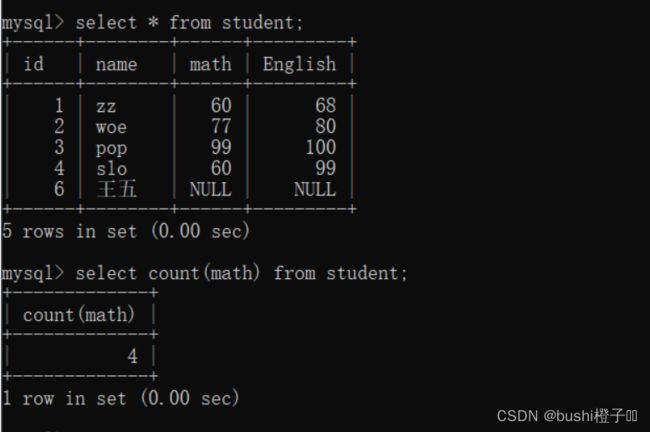
sum()
统计不及格 < 60 的数学总分 ,没有结果返回null
select sum(math) from student where math < 60;
avg()
统计平均总分
-- as 给查询出来的临时表列名 取个别名 没忘记吧?(前面的内容)
select avg(math+English) as 平均总分 from student;
max()和min()
-- 查询math最高分
select max(math) from student;
-- 查询math最低分
select min(math) from student;
2.2 group by
select中使用group by 子句可以对指定列进行分组查询.
需要满足:使用group by进行分组查询时,select 指定的字段必须是"分组依据字段",其他字段若想出现在select中则必须包含在聚合函数中.
语法
select 列名1,聚合函数名(列名2),..from 表名 group by 列名1,列名2...;
案例:
准备测试表及数据:员工表,有id(主键),name(姓名),role(角色),salary(薪水)
-- 建表
create table emp(
id int primary key auto_increment,
name varchar(20) ,
role varchar(20),
salary numeric(11,2)
);
-- 指定列名插入数据
insert into emp (name ,role , salary) values
('小微','经理',6500),
('猪猪女孩','服务员',2000),
('云朵','咖啡师',5500),
('彩云','咖啡师',5000),
('本人','咖啡师',4800);
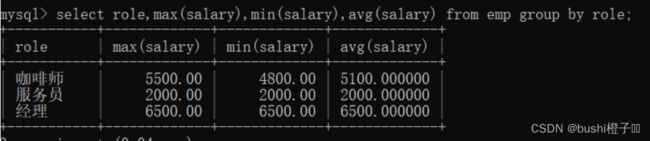
- 查询每个角色的最高工资,最低工资,平均工资
-- 按角色 进行分组查询
-- role是"分组依据的字段"
select role,max(salary),min(salary),avg(salary) from emp group by role;
2.3 having
group by 字句进行分组以后,需要对分组结果再进行条件过滤时,不能使用where 语句,而需要用having;
语法:
select 列名1,聚合函数名(列名2),..from 表名 group by 列名1,列名2...having 表达式..;
- 查询平均工资低于5000的角色和他的平均工资
-- 查询完后,再进行筛选
-- 把平均工资大于5000 的全部排除到结果外
select role,max(salary),min(salary),avg(salary) from emp group by role having avg(salary) < 5000;

2.4 联合查询
实际开发中往往数据是来自不同的表,所有需要多表联合查询.多表查询是对多个表的数据进行取 笛卡尔积:
把表1的第一行和表2的第一行进行配对,再和表2的第二行配对.
表1的第二行和表2的第一行进行配对,再和表2的第二行配对.
也就是两个表的行数乘积
不过这些个个匹配的数据,有大部分是无意义的数据,所以需要进行筛选,也就是接下来需要学习到的.
select * from 表1,表2;
-- 可以加条件 只查找 表1的id和name 对应的表2的math
select 表1.id,表1.name,表2.math from 表1,表2 where 表1.id = 表2.student_ID;
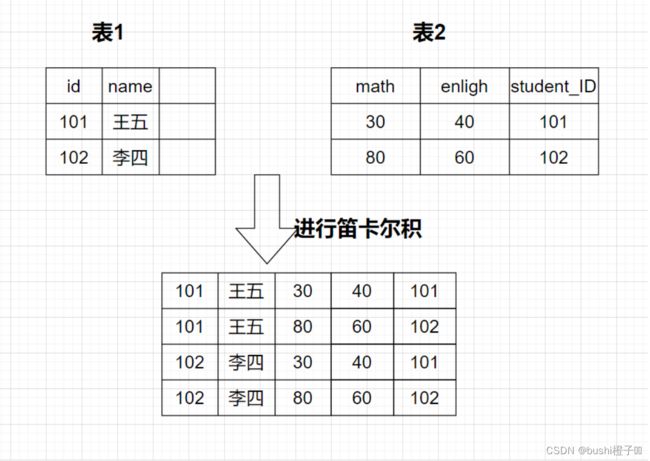
注意:关联查询可以对关联表使用别名.
准备数据:
-- 建表
-- 使用关键字作为列名需要:`列名`
create table classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
create table student(
id int primary key auto_increment,
name varchar(20),
sn int unique,
classes_id int,
foreign key (classes_id) references classes(id)
);
create table course(
id int primary key auto_increment,
name varchar(20)
);
create table score(
id int primary key auto_increment,
score decimal(3,1),
student_id int,
course_id int,
foreign key (student_id) references student(id),
foreign key (course_id) references course(id)
);
-- 初始化数据
insert into classes(id,name,'desc') values
(1,'软件20级4班','学习c,java,数据库'),
(2,'计算机系19级1班','学习计算机原理');
insert into student (id,sn,name,classes_id) values
(3,'20200401','小飞','1'),
(4,'20200402','小花','1'),
(9,'20210206','肖京腾','2');
insert into course(name) values
('java,c'),
('计算机原理'),
('数据库'),
('语文'),
('数学');
insert into score (score,student_id,course_id) values
-- 小飞
(80,3,1),(60,3,3),
-- 小花
(80,4,2);
2.4.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
-- 两者等同
select 字段 from 表1 别名1, 表2 别名2 where 连接条件 and 其他条件;
案例
查询"小飞"同学的成绩
//方法1
select sco.score from student stu join score sco on stu.id = sco.student_id and stu.name = "小飞";
//方法2
select sco.score from student stu, score sco where stu.id=sco.student_id and
stu.name='小飞';

.是成员访问运算符- student join score 表示 上student和score 进行联合.可以多表联合,比如 student和score联合完 可以再 join course表;表示 student和score联合完成一个表后,这个结合表再和course联合.
- 查询所有学生成绩,如果有学生成绩是null,是不会被查询出来的.
2.4.2 外连接
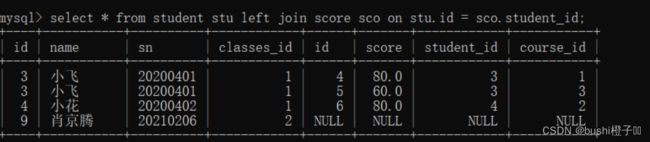
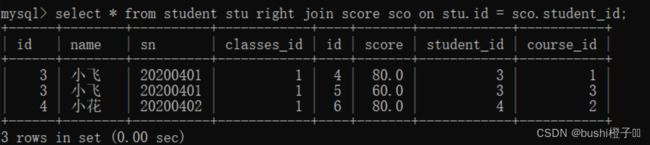
外连接分为左外连接[left]和右外连接[right] . 如果联合查询,需要左侧的表完全显示就要用到左连接,右则的表完全显示用右连接.
语法: 在join 前+ left / right
-- 把表1的内容全部显示出来,是null也会查询出来
select 字段名 from 表1 left join 表2 on 连接条件;
-- 把表2的内容全部显示出来,是null也会查询出来
select 字段名 from 表1 left join 表2 on 连接条件;
查询所有同学的成绩
查询学生表,成绩表,课程表 ,3张表的关联查询:
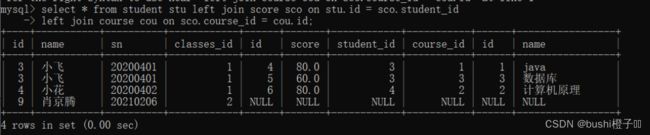
2.4.3 自连接
自连接:自己和自己进行迪尔卡积.就是把行转成列,SQL中无法针对行和行之间进行条件比较,但是有的需求,又需要进行行和行之间比较,这时候就可以使用自连接,把行转成列.
查询"数据库"和"java"成绩高的信息
-
先查询 分数表
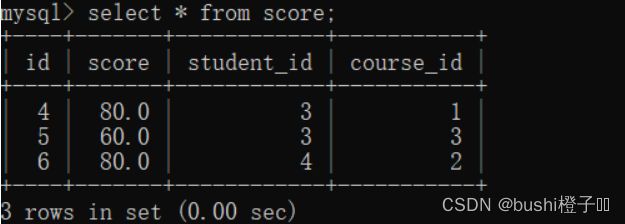
-
再查询 课程信息
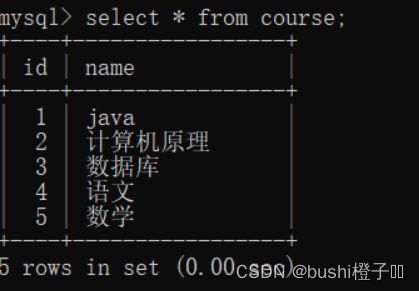
这两张表进行对比,可以看出"java"要比"数据库"成绩高
- 进行分数表的自连接

很明显,报错信息显示,表名重复, 如果要进行一张表自连接,需要起个别名.
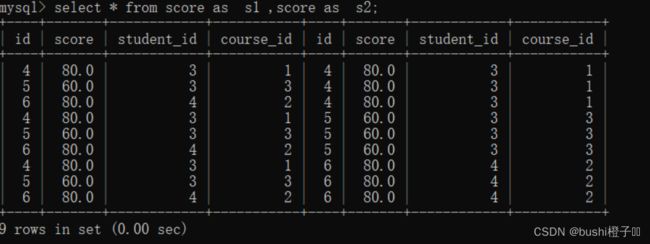
自连接也会产生大量的无效匹配数据,所以也需要指定连接条件,在这里我们需要指定每个同学和自己的"数据库","java"成绩进行比较.
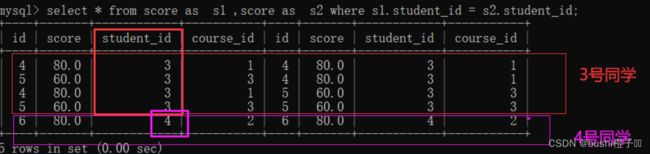
"java"的课程id是1,"数据库"课程id是3.
此时就可以看出"java"和"数据库"的对应关系80 > 60.仔细看见表可以发现 有左3 右1 和 左1右3的排列组合,因为排列组合是把所有可能性都排列出来了.可以把符合条件的记录挑选出来.

这个时候就把符合条件的数据挑选出来了, 且没有重复数据.可以看出谁是 “java” > "数据库"的数据; 由于这里案例数据少,所有已经就剩下一条数据了,一般而言还需要进行最后一步分数比较.
最终把"java">"数据库"的数据给筛选出来:

以上是分步查找的,要显示学生及成绩信息,可以一条语句显示:
select stu.*,s1.score java,s1.score 数据库
from
score s1,
join score s2 on s1.student_id = s2.student_id
join student stu on s1.student_id = stu.id
join course c1 on s1.course_id = c1.id
join course c2 on s2.course_id = c2.id
and s1.score < s2.score
and c1.name = "java"
and c2.name = "数据库";
2.4.4 子查询
子查询是指嵌入到其他SQL语句中的select语句,也叫嵌套查询(套娃?)
- 单行子查询:返回一行记录的子查询
查询与"小飞"同学的同班同学
-- 分步查询 不用子查询
-- 查询出来 小飞的班级id是 1
select classes_id from student where student.name = "小飞";
select name from student where classes_id = 1 and name != "小飞";
-- 实际上 子查询就是这两句合并了
-- 查询name="小飞"的结果,把这个结果作为外面条件
--wehre classes_id = 结果
select * from student where classes_id = (select classes_id from student where name = "小飞");
classes_id =的 后面的子查询必须只返回一条记录,此时才可以写作 =,否则错误!
- 多行子查询:返回多行记录的子查询
查询"数学"或"语文"课程的成绩信息
- [NOT] IN关键字
-- 1.查询课程id 数学的 = 5 语文的id= 4
select id from course where name = "数学" or name = "语文";
-- 2.查询成绩
select * from score where course_id = 5 or course_id = 4;
-- 使用in关键字 一步到位
select * from score where course_id in (select id from course where name = "数学" or name = "语文");
in查询的结果是放入内存中, 如果查询结果太大,内存就放不下,in就用不了,这时候就需要exists代替,其实如果查询结果太大,最好还是分步来查询
- [NoT] Exists 关键字 (可读性差,执行效率低)
select * from score where exists (select score.id from course where(name = '数学' or name = '语文') and course.id = score.course_id);
2.4.5 合并查询
本质是把两个查询结果合并成一个;并且两个结果的列相同,列名相同,类型相同,才能合并.
- union 操作符
该操作用于取得两个结果集的并集,会自动去掉结果集中的重复行.
查询id小于3,或者名字为"语文"的课程
-- 使用unio
select * from course where id < 3 union
select * from course where name = "语文";
-- 使用 or
select * from course where id < 3 or name = "语文";
-
union all
该操作不会去掉重复行.
select * from course where id < 3 union all
select * from course where name = "语文";
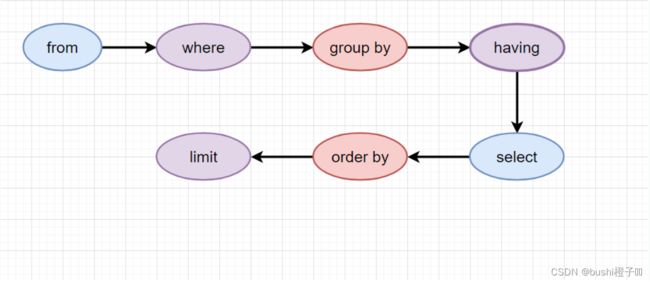
3 SQL的执行顺序(where…)