【PyTorch深度学习】PVCGN、聚类对私家车流入流出量进行可视化和预测实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、数据预处理
私家车轨迹数据在获取后,会存在一系列数据的质量问题,如数据缺失、冗余,在对移动轨迹数据分析和挖掘前,根据不同的应用场景和研究目标,对原始数据进行有效的预处理。主要介绍私家车的行程数据的预处理方法,选取了7个主要的字段:ObjectID, StartTime, StartLon, StartLat, StopTime, StopLon, StopLat
由于车辆在实时动态的获取数据,并且交通状态、道路网络等行驶环境复杂,例如车辆行驶到高大建筑物附近存在遮挡或者有较强电磁波干扰的地方时又或者定位装置出现故障未及时排查时,都会导致定位装置产生与真实值存在偏差的位置数据
家车轨迹数据预处理的方法和代码,具体为清除主要字段缺失的数据、清除行程起始时间相等的数据和清除起始地点小于3m的数据
首先,剔除主要字段为0的数据。其次,私家车出行小于1分钟的行程记录标记为无效记录,将被删除。最后,删除私家车起始位置位置较近的行程记录,通过Haversine距离计算载客点之间的距离,设置距离阈值为3米,起始位置小于3米的订单将被删除
二、问题陈述及模型框架
将基于获取的私家车流量的时间序列CSV文件,以开源的深度学习预测模型为例,进行Pytorch框架在私家车流量预测应用案例中的实战教学。本节基于私家车轨迹数据将城市划分成多个子区域,统计每个子区域的历史私家车流量,以物理-虚拟协作图网络(Physical-virtual collaboration graph network, PVCGN)模型为例对未来连续几个时间段的私家车流入量和流出量进行预测
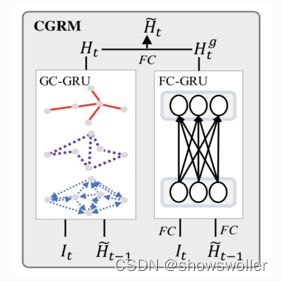
PVCGN模型
如下左图可以看出该模型的核心组件为协作门控循环网络。基于历史数据构建多视角图结构,将这些多图合并到图卷积门控循环单元中,以进行时空表示学习。此外,全连接门控循环单元也被应用于捕获全局的流量演变趋势。如下右图,联合GC-GRU和FC-GRU开发了CGRM模型预测未来的流量

三、数据准备
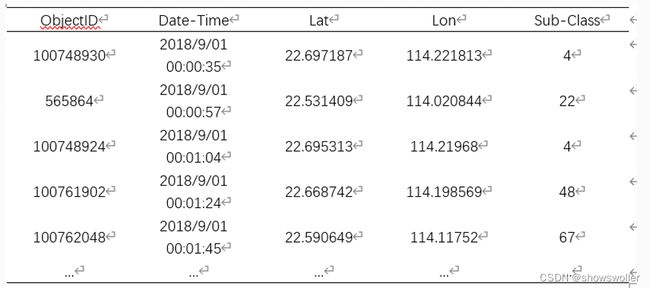
使用湖南大学开源的深圳市私家车轨迹数据,时间跨度为2018/9/1至2018/9/15,共有211000条数据。数据集包含了7个字段,分别是车辆脱敏后的唯一编号、出发时间、出发点经度、出发点纬度、到达时间、到达点经度、到达点纬度。每条数据表示了一辆私家车的行程信息,数据示例如下表所示

数据的具体字段说明如下表

四、数据建模
轨迹聚类
本实战为一个简单的有监督学习任务。首先采用K均值聚类算法(K-means clustering algorithm,K-means)对私家车轨迹数据聚类,聚类的目的是对私家车用户常去的地点打标签,划分出私家车用户常去的地点群,从而将城市划分成多个子区域。城市区域的空间划分可以通过多种方式实现,为简化流程,旨在获得城市区域的标签
由于聚类算法的随机性,在选取数据时需要将出发地点和到达地点的数据一起聚类。为了后续构建相似图、关联图以及距离图,在计算时需要输出聚类中心的经纬度以及其所属的类簇。将K值设置为80
利用pandas库的read_csv功能从CSV文件中导入数据,再使用concat函数将出发地点、到达地点数据拼接到一起。使用sklearn.cluster模块下的K-means函数构造estimator聚类器,并利用estimator的labels_和cluster_centers_属性来获取聚类标签与聚类中心。使用matplotlib.pyplot模块下的scatter函数将聚类结果绘制成散点图,颜色相同的点属于同一个簇
轨迹聚类结果
每个类簇所包含的样本点数

聚类中心点

车流量的时空分布统计
设计统计算法统计聚类得到的地点群的车流量,共划分了80个子区域。根据数据集在时间上的分布规律,将时间片设置为1小时,则一天被划分为24个时间片。统计算法将每一条出发记录记为一次车辆流出,将每一条到达记录记为一次私家车流入。若在一个时间片内,m簇包含n条出发或到达记录,则表示此时段内m区域的流出或流出量为n。本节所设计的统计算法在每次循环迭代中使用了count函数,提取了私家车流量在时间与空间上的分布
为了便于统计,首先将聚类之后的数据集按照时间顺序排序。借助time模块的strftime函数来格式化日期,并得到可读字符串,再使用strptime函数将其解析为时间元组,实现了时间的相加运算。开始遍历数据集,以一小时为单位,初始化列表infos,并使用append函数存储一小时内所有数据的聚类标签。对于infos中的每个数值,使用count函数统计每个数值的个数。当一轮循环结束时,再使用clear功能清空infos,完成统计
车流量的时空分布统计结果:每小时80个区域的私家车流入量

在2018年9月1日至2018年9月15日期间,80个区域总共有210942次车辆流入、210980次车辆流出,平均流入量为14062次/天、平均流出量为14065次/天。本节分别统计了单日流入量与单日流出量,并绘制成柱状图。从下图中,可以看出工作日的车流量较为稳定并整体高于休息日的车流量,符合城市居民的出行规律

车流量的时空分布统计小结
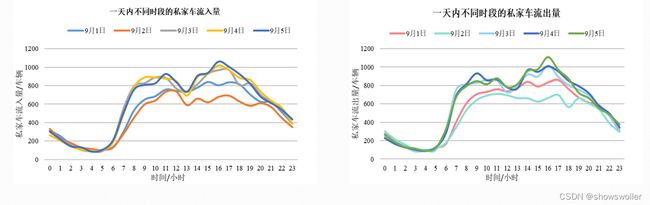
本节选用了9月1日至9月5日的数据,继续统计不同时间段的私家车流量。从上张图中可以看出,0:00-6:00的车流量呈下降趋势,私家车出行量较少,并于4:00-6:00达到车流量分布的波谷。6:00-10:00的车流量有显著的上升趋势,其中8:00-10:00是一天当中的早高峰时段,城市居民的出行主要以工作、上学为目的。10:00-12:00的车流量较为稳定,呈现小幅度的上下波动。12:00-14:00为居民午休时间,这一时段的车流量有小幅度的下降。14:00-16:00的车流量的上升趋势较为平缓,并于16:00-18:00达到一天的峰值,此时段是晚高峰时段,大部分居民的出行是以下班、放学、聚餐和购物等活动为目的。18:00以后的私家车出行随着时间的流逝而呈现出整体下降的趋势
多视角时空图的构建
本节设计算法构造距离图、相似图和关联图,利用多图来提取不同区域之间的多视角时空关联。每个图有相同的80个结点,分别代表80个聚类中心,每一种图的边有不同的定义。首先,构建距离矩阵P,P(i,j)表示聚类中心i到聚类中心j的实际距离,即利用经纬度值与Haversine公式所计算出的球面距离。算法仅仅计算了主对角线以上的矩阵值,并设置对角线处的值P(i,i)为0,再根据矩阵的对称性来进行值填充,避免了重复计算、节省时间。
多视角时空图的构建无向距离图示例

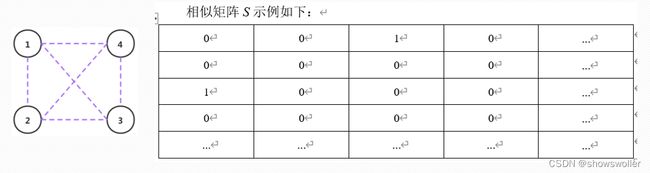
构建相似矩阵S,首先计算P(i, j)的平均值(0≤i, j≤79),即结点之间实际距离的平均值distance_mean。若P(i, j)的值大于distance_mean,则设置S(i,j)的值为1,否则S(i, j)为0
接着构建关联矩阵C,C(i, j)表示在整个数据集中从聚类中心i到聚类中心j的车辆总数,描述了两个区域之间的动态交互。C(i, i)需要进行计算,因为部分私家车会在同一个区域内进出。定义二维数组trans_matrix[i][j]进行累加统计
多视角时空图的构建有向关联图示例

使用pickle库中的dump函数,将矩阵P、S、C分别封装为graph_sz_conn.pkl、graph_sz_sml.pkl、graph_sz_cor.pkl,代表了距离图、相似图和关联图
数据格式转换
预测模型的输入共包含3个pkl文件,即训练集、验证集和测试集,均存储了私家车流入流出数据。本节将私家车流量数据(2018/9/1-2018/9/15)划分为3个部分,分别是训练集(2018/9/1-2018/9/10)、验证集(2018/9/11-2018/9/12)和测试集(2018/9/13-2018/9/15)。参考模型的输入数据格式,设计算法将3组数据集分别存储到train.pkl、val.pkl和test.pkl中,每个pkl文件均为包含了4个多维数组的字典。以train.pkl为例,共设有233组时间片,每组包含4个时间片,本节拟使用前4个时间片(1h*4=4h)的私家车流量(80个区域的私家车流入与流出)来预测后4个时间片的私家车流量,也就是使用x_train来预测y_train,例如0:00-04:00 →04:00-08:00
数据格式转换:pkl文件字段说明

数据格式转换:参数说明

数据格式转换: pkl文件具体信息

PVCGN模型
使用CGRM模块与Seq2Seq框架来构建PVCGN模型,以预测未来各时段各区域的私家车流量。PVCGN包含了一个编码器和一个解码器,两者分别包含两个CGRM模块。在编码器中,为了积累相关历史信息,将流量数据输入到底层CGRM模块中。并将其输出的隐藏状态输入到上层的CGRM模块中以进行高层次的特征学习。在解码器中,初次迭代时将输入数据设置为0,使用编码器的最终隐藏状态来初始化解码器的隐藏状态。再将上层CGRM模块的输出隐藏状态输入到全连接层中,从而预测未来的车流量。在接下来的迭代中,底层的CGRM模块将上一次迭代所得的预测值作为输入,上层的CGRM模块继续利用全连接层进行预测,最终获得未来的预测值序列
五、模型训练及测试结果
将封装好的6个pkl文件输入到PVCGN深度学习模型中,使用model.train()语句来启用Batch Normalization和 Dropout并开始训练。为了方便模型的加载以及节约时间,使用pytorch中的state_dict字典对象和save函数来保存每轮训练后的模型参数。测试部分使用model.eval()语句从训练模式切换到测试模式,并使用with torch.no_grad()语句停止梯度更新,以起到加速和节省显存的作用。PVCGN离线训练和测试的代码ggnn_train.py在Github上已经开源
使用了均方根误差、平均绝对误差和平均绝对百分比误差来评估模型。这3个指标都描述了预测值与真实值之间的误差程度,值越小说明模型的精确度越高
实验评估使用scaler下的inverse_transform函数将标准化的数据还原,得到原始数据。再使用自定义的函数计算各评估参数的数值
在预测部分,使用的实验设备的操作系统为Ubuntu 18.04,GPU为NVIDIA RTX2080Ti。所用软化及其版本号如下图所示

在进行参数设置时,我们主要考虑了数据规模、计算能力等因素。Batch Size表示每个batch中的训练样本数量,为了在内存效率和内存容量之间寻求最佳平衡,本章将Batch Size设置为32,将epoch设置为200次,随着epoch数量的增加,神经网络中更新迭代的次数增多,从最开始的不拟合状态,慢慢进入优化拟合状态。
通过调整超参数rnn_units(隐藏层单元的个数)来确定最优模型,记录训练过程中隐藏层单元的个数对于MAE、MAPE和RMSE的影响,实验结果如下图所示

如下图所示,可以发现当隐藏层单元的个数为32时,MAE和后面的MAPE曲线均处于波谷,即达到最小值

虽然当隐藏层单元的个数为16时,RMSE的值最低,但是前面的MAE曲线和MAPE的值均较高。因此隐藏层单元的个数的最优值为32,此时模型的预测能力最优,当epoch为83时达到最优预测结果

六、代码
最后 部分代码如下
ggnn_train.py
import random
import argparse
import time
import yaml
import numpy as np
import torch
import os
from torch import nn
from torch.nn.utils import clip_grad_norm_
from torch import optim
from torch.optim.lr_scheduler import MultiStepLR
from torch.nn.init import xavier_uniform_
from lib import utils
from lib import metrics
from lib.utils import collate_wrapper
from ggnn.multigraph import Net
import torch.backends.cudnn as cudnn
try:
from yaseed)
torch.manual_seed(seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
cuda = True
cudnn.benchmark = True
# 读取配置文件
def read_cfg_file(filename):
with open(filename, 'r') as ymlfile:
cfg = yaml.load(ymlfile, Loader=Loader)
return cfg
torch.cuda.empty_cache()
def run_model(model, data_iterator, edge_index, edge_attr, device, output_dim):
"""
return a list of (horizon_i, batch_size, num_nodes, output_dim)
"""
# while evaluation, we need model.eval and torch.no_grad
model.eval()
y_pred_list = []
for _, (x, y, xtime, ytime) in enumerate(data_iterator):
y = y[..., :output_dim]
sequences, y = collate_wrapper(x=x, y=y,
edge_index=edge_index,
edge_attr=edge_attr,
device=device)
# (T, N, num_nodes, num_out_channels)
with torch.no_grad():
y_pred = model(sequences)
y_pred_list.append(y_pred.cpu().numpy())
return y_pred_list
# 模型性能评估
def evaluate(model,
dataset,
dataset_type,
edge_index,
edge_attr,
device,
output_dim,
logger,
detail=True,
cfg=None,
format_result=False):
if detail:
logger.info('Evaluation_{}_Begin:'.format(dataset_type))
scaler = dataset['scaler']
y_preds = run_model(
model,
data_iterator=dataset['{}_loader'.format(dataset_type)].get_iterator(),
edge_index=edge_index,
edge_attr=edge_attr,
device=device,
output_dim=output_dim)
y_preds = np.concatenate(y_preds, axis=0) # concat in batch_size dim.
mae_list = []
mape_list = []
rmse_list = []
mae_sum = 0
mape_sum = 0
rmse_sum = 0
# horizon = dataset['y_{}'.format(dataset_type)].shape[1]
horizon = cfg['model']['horizon']
for horizon_i in range(horizon):
y_truth = scaler.inverse_transform(
dataset['y_{}'.format(dataset_type)][:, horizon_i, :, :output_dim])
y_pred = scaler.inverse_transform(
y_preds[:y_truth.shape[0], horizon_i, :, :output_dim])
mae = metrics.masked_mae_np(y_pred, y_truth, null_val=0, mode='dcrnn')
mape = metrics.masked_mape_np(y_pred, y_truth, null_val=0)
rmse = metrics.masked_rmse_np(y_pred, y_truth, null_val=0)
mae_sum += mae
mape_sum += mape
rmse_sum += rmse
mae_list.append(mae)
mape_list.append(mape)
rmse_list.append(rmse)
msg = "Horizon {:02d}, MAE: {:.2f}, MAPE: {:.4f}, RMSE: {:.2f}"
if detail:
logger.info(msg.format(horizon_i + 1, mae, mape, rmse))
if detail:
logger.info('Evaluation_{}_End:'.format(dataset_type))
if format_result:
for i in range(len(mape_list)):
print('{:.2f}'.format(mae_list[i]))
print('{:.2f}%'.format(mape_list[i] * 100))
print('{:.2f}'.format(rmse_list[i]))
print()
else:
return mae_sum / horizon, mape_sum / horizon, rmse_sum / horizon
class StepLR2(MultiStepLR):
"""StepLR with min_lr"""
def __init__(self,
optimizer,
milestones,
gamma=0.1,
last_epoch=-1,
min_lr=2.0e-6):
"""
:optimizer: TODO
:milestones: TODO
:gamma: TODO
:last_epoch: TODO
:min_lr: TODO
"""
self.optimizer = optimizer
self.milestones = milestones
self.gamma = gamma
self.last_epoch = last_epoch
self.min_lr = min_lr
super(StepLR2, self).__init__(optimizer, milestones, gamma)
def get_lr(self):
lr_candidate = super(StepLR2, self).get_lr()
if isinstance(lr_candidate, list):
for i in range(len(lr_candidate)):
lr_candidate[i] = max(self.min_lr, lr_candidate[i])
else:
lr_candidate = max(self.min_lr, lr_candidate)
return lr_candidate
def adjacency_to_edge_index(A):
node_x, node_y = A.nonzero()
return np.asarray(list(zip(node_x, node_y))).transpose(1, 0)
def adjacency_to_edge_weight(A):
sources, targets = A.nonzero()
assert (len(sources) == len(targets))
edge_weight = []
for i in range(len(sources)):
w = A[sources[i], targets[i]]
edge_weight.append(w)
return np.asarray(edge_weight)
def _get_log_dir(kwargs):
log_dir = kwargs['train'].get('log_dir')
if log_dir is None:
batch_size = kwargs['data'].get('batch_size')
learning_rate = kwargs['train'].get('base_lr')
num_rnn_layers = kwargs['model'].get('num_rnn_layers')
rnn_units = kwargs['model'].get('rnn_units')
structure = '-'.join(['%d' % rnn_units for _ in range(num_rnn_layers)])
others = ''
if kwargs['model'].get('global_fusion', False) is True:
others = others + '_' + 'gf'
if kwargs['model'].get('use_input', False) is True:
others = others + '_' + 'input'
K = kwargs['model'].get('K')
graph_type = kwargs['model'].get('graph_type')
run_id = 'ggnn_%s_%s_k%d%s_lr%g_bs%d_%s/' % (
structure,
graph_type,
K,
others,
learning_rate,
batch_size,
time.strftime('%m%d%H%M%S'))
base_dir = kwargs.get('base_dir')
log_dir = os.path.join(base_dir, run_id)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
return log_dir
def init_weights(m):
if type(m) == nn.Linear:
xavier_uniform_(m.weight.data)
xavier_uniform_(m.bias.data)
def main(args):
cfg = read_cfg_file(args.config_filename)
log_dir = _get_log_dir(cfg)
log_level = cfg.get('log_level', 'INFO')
logger = utils.get_logger(log_dir, __name__, 'info.log', level=log_level)
device = torch.device(
'cuda') if torch.cuda.is_available() else torch.device('cpu')
# all edge_index in same dataset is same
# edge_index = adjacency_to_edge_index(adj_mx) # alreay added self-loop
logger.info(cfg)
batch_size = cfg['data']['batch_size']
test_batch_size = cfg['data']['test_batch_size']
# edge_index = utils.load_pickle(cfg['data']['edge_index_pkl_filename'])
sz = cfg['data'].get('name', 'notsz') == 'sz'
adj_mx_list = []
graph_pkl_filename = cfg['data']['graph_pkl_filename']
if not isinstance(graph_pkl_filename, list):
graph_pkl_filename = [graph_pkl_filename]
src = []
dst = []
for g in graph_pkl_filename:
if sz:
adj_mx = utils.load_graph_data_sz(g)
else:
_, _, adj_mx = utils.load_graph_data(g)
for i in range(len(adj_mx)):
adj_mx[i, i] = 0
adj_mx_list.append(adj_mx)
adj_mx = np.stack(adj_mx_list, axis=-1)
if cfg['model'].get('norm', False):
print('row normalization')
adj_mx = adj_mx / (adj_mx.sum(axis=0) + 1e-18)
src, dst = adj_mx.sum(axis=-1).nonzero()
edge_index = torch.tensor([src, dst], dtype=torch.long, device=device)
edge_attr = torch.tensor(adj_mx[adj_mx.sum(axis=-1) != 0],
dtype=torch.float,
device=device)
output_dim = cfg['model']['output_dim']
for i in range(adj_mx.shape[-1]):
logger.info(adj_mx[..., i])
# print(adj_mx.shape) (207, 207)
if sz:
dataset = utils.load_dataset_sz(**cfg['data'],
scaler_axis=(0,
1,
2,
3))
else:
dataset = utils.load_dataset(**cfg['data'])
for k, v in dataset.items():
if hasattr(v, 'shape'):
logger.info((k, v.shape))
scaler = dataset['scaler']
scaler_torch = utils.StandardScaler_Torch(scaler.mean,
scaler.std,
device=device)
logger.info('scaler.mean:{}, scaler.std:{}'.format(scaler.mean,
scaler.std))
model = Net(cfg).to(device)
# model.apply(init_weights)
criterion = nn.L1Loss(reduction='mean')
optimizer = optim.Adam(model.parameters(),
lr=cfg['train']['base_lr'],
eps=cfg['train']['epsilon'])
scheduler = StepLR2(optimizer=optimizer,
milestones=cfg['train']['steps'],
gamma=cfg['train']['lr_decay_ratio'],
min_lr=cfg['train']['min_learning_rate'])
max_grad_norm = cfg['train']['max_grad_norm']
train_patience = cfg['train']['patience']
val_steady_count = 0
last_val_mae = 1e6
horizon = cfg['model']['horizon']
for epoch in range(cfg['train']['epochs']):
total_loss = 0
i = 0
begin_time = time.perf_counter()
train_iterator = dataset['train_loader'].get_iterator()
model.train()
for _, (x, y, xtime, ytime) in enumerate(train_iterator):
optimizer.zero_grad()
y = y[:, :horizon, :, :output_dim]
sequences, y = collate_wrapper(x=x, y=y,
edge_index=edge_index,
edge_attr=edge_attr,
device=device)
y_pred = model(sequences)
y_pred = scaler_torch.inverse_transform(y_pred)
y = scaler_torch.inverse_transform(y)
loss = criterion(y_pred, y)
loss.backward()
clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
total_loss += loss.item()
i += 1
val_result = evaluate(model=model,
dataset=dataset,
dataset_type='val',
edge_index=edge_index,
edge_attr=edge_attr,
device=device,
output_dim=output_dim,
logger=logger,
detail=False,
cfg=cfg)
val_mae, _, _ = val_result
time_elapsed = time.perf_counter() - begin_time
logger.info(('Epoch:{}, train_mae:{:.2f}, val_mae:{},'
'r_loss={:.2f},lr={}, time_elapsed:{}').format(
epoch,
total_loss / i,
val_mae,
0,
str(scheduler.get_lr()),
time_elapsed))
if last_val_mae > val_mae:
logger.info('val_mae decreased from {:.2f} to {:.2f}'.format(
last_val_mae,
val_mae))
last_val_mae = val_mae
val_steady_count = 0
else:
val_steady_count += 1
# after per epoch, run evaluation on test dataset.
if (epoch + 1) % cfg['train']['test_every_n_epochs'] == 0:
evaluate(model=model,
dataset=dataset,
dataset_type='test',
edge_index=edge_index,
edge_attr=edge_attr,
device=device,
output_dim=output_dim,
logger=logger,
cfg=cfg)
if (epoch + 1) % cfg['train']['save_every_n_epochs'] == 0:
save_dir = log_dir
if not os.path.exists(save_dir):
os.mkdir(save_dir)
config_path = os.path.join(save_dir,
'config-{}.yaml'.format(epoch + 1))
epoch_path = os.path.join(save_dir,
'epoch-{}.pt'.format(epoch + 1))
torch.save(model.state_dict(), epoch_path)
with open(config_path, 'w') as f:
from copy import deepcopy
save_cfg = deepcopy(cfg)
save_cfg['model']['save_path'] = epoch_path
f.write(yaml.dump(save_cfg, Dumper=Dumper))
if train_patience <= val_steady_count:
logger.info('early stopping.')
break
scheduler.step()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--config_filename',
default=None,
type=str,
help='Configuration filename for restoring the model.')
args = parser.parse_args()
main(args)
创作不易 觉得有帮助请点赞关注收藏~~~