Pyecharts(三) —— 星巴克门店分布
Python数据可视化
- Pyecharts(三) —— 星巴克门店分布
-
- 一、背景
- 二、数据可视化
-
- 2.1 星巴克全球分布图
- 2.2 门店数量在前15的城市
- 2.3 门店所有权占比
- 2.4 星巴克在中国的分布
-
- 2.4.1 根据经纬度绘制热力地图
- 2.4.2 国内星巴克门店最多的20个城市
Pyecharts(三) —— 星巴克门店分布
大家可以关注知乎或微信公众号的share16,我们也会同步更新此文章。
一、背景
该数据集囊括了截至2017-02月全球星巴克门店的基础信息,其中包括品牌名称、门牌地址、所在国家、经纬度等一系列详细的信息。
点此下载数据集
二、数据可视化
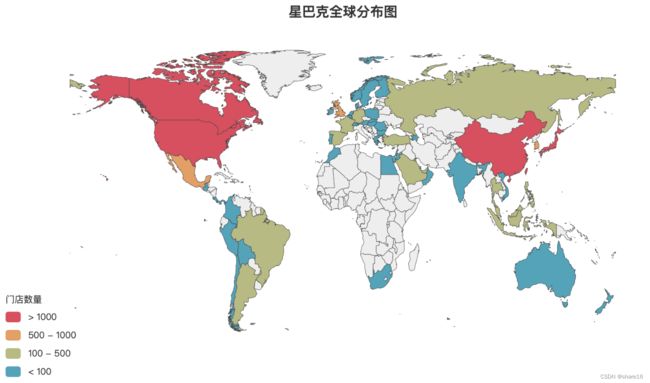
2.1 星巴克全球分布图
import pandas as pd
from pyecharts.charts import *
import pyecharts.options as opts
df = pd.read_csv('/XXXXXX/星巴克.csv')
a = list(df.所在国家.value_counts().to_dict().items())
map = Map()
map.add('',list(df.所在国家.value_counts().to_dict().items()),maptype='world',is_roam=False,
is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(title_opts=opts.TitleOpts(title='星巴克全球分布图',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(max_=14000))
map.render_notebook()
map.set_global_opts(title_opts=opts.TitleOpts(title='星巴克全球分布图',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(range_text=['门店数量'],
is_piecewise=True, #分段显示
pieces=[{'min':1000},{'min':500,'max':1000},
{'min':100,'max':500},{'max': 100}]))
map.render_notebook()

# 空值填充
df_t = df.fillna(value=dict(county_name='NA', city_name='NA'))
df_t = df_t.groupby(['所在国家', '所在城市'])['品牌名称'].count().reset_index()
data = []
country = []
# 数据处理成Pyecharts需要的格式
for idx, row in df_t.iterrows():
if row['所在国家'] in country:
data[-1]['children'].append(dict(name=row['所在城市'], value=row['品牌名称']))
else:
data.append(dict(name=row['所在国家'], children=[dict(name=row['所在城市'], value=row['品牌名称'])]))
country.append(row['所在国家'])
tree = TreeMap()
tree.add('星巴克门店',data,leaf_depth=1, # 叶子节点深度 国家和城市两层,深度为1
label_opts=opts.LabelOpts(position="inside",formatter='{b}:{c}门店'), # 标签设置
levels=[ # 针对每一层的样式设置
opts.TreeMapLevelsOpts(
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color="#555",border_width=4,gap_width=4)),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6], # 颜色饱和度范围
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7,gap_width=2,border_width=2))])
tree.set_global_opts(title_opts=opts.TitleOpts(title="各国/地区星巴克门店数量(可点击下钻到城市)"),
legend_opts=opts.LegendOpts(is_show=False))
tree.render_notebook()

从地图上看,星巴克门店主要集中于美国,其次在亚洲的中国、日本;非洲、大洋洲几乎看不到星巴克门店的存在,其中的原因可能是消费水平考虑或当地居民不喜欢星巴克这种商业咖啡。
从上述数据a中能看到,星巴克的门店基本覆盖了美国整个领土,远远领先其他国家,总门店数已达13000余家;除美国之外,中国是拥有星巴克门店最多的国家,门店数3128家;门店数量前五的国家是美国、中国、加拿大、日本、韩国,可以看出星巴克主要市场集中于北美和亚洲市场。
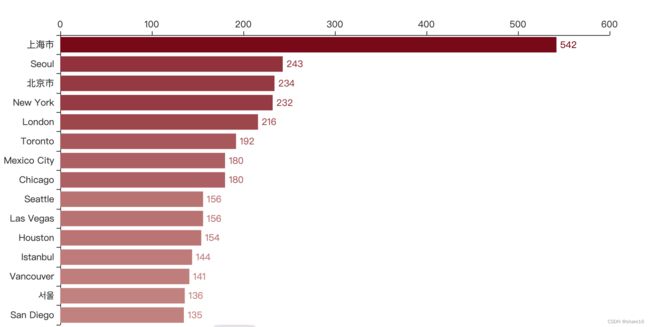
2.2 门店数量在前15的城市
c = df.groupby('所在城市').品牌名称.count().reset_index().sort_values('品牌名称',ascending=False).iloc[:15,:]
x_c,y_c = list(c.所在城市),list(c.品牌名称)
b = Bar()
b.add_xaxis(x_c)
b.add_yaxis('',y_c,label_opts=opts.LabelOpts(position='right'))
b.set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),yaxis_opts=opts.AxisOpts(is_inverse=True),
visualmap_opts=opts.VisualMapOpts(is_show=False,max_=300,dimension=0,
range_color=['#FFE7D3','#7A0616'] )) #range_color-可省略
b.reversal_axis()
b.render_notebook()
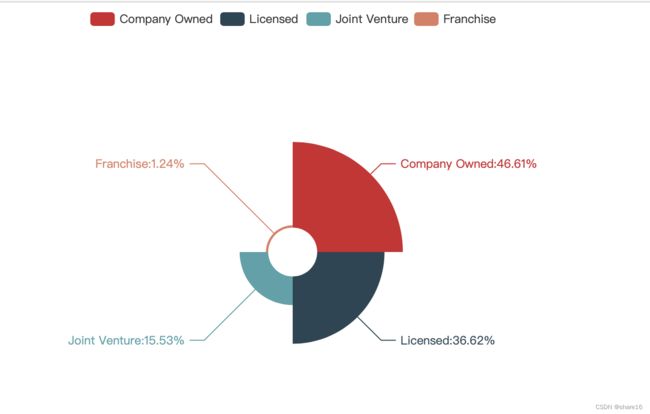
2.3 门店所有权占比
#radius:设置内外径的大小来实现圆环的效果
#rosetype:可取值radius或area
d = df.groupby('门店所有权').品牌名称.agg('count').sort_values(ascending=False)
p = Pie()
p.add('',list(d.to_dict().items()),radius=['10%','45%'],rosetype='area',
label_opts=opts.LabelOpts(formatter="{b}:{d}%") )
p.render_notebook()
2.4 星巴克在中国的分布
2.4.1 根据经纬度绘制热力地图
df_china = df[df.所在国家=='China']
a = df_china.groupby(['经度','纬度']).品牌名称.count()
jwd,data = [],[]
for i,j in list(a.to_dict().items()):
jwd.append((str(i[0])+'-'+str(i[1]),i[0],i[1]))
data.append((str(i[0])+'-'+str(i[1]),j))
''' 绘制地图热力图,必须max_或颜色等'''
geo = Geo()
for i in jwd:
geo.add_coordinate(i[0],i[1],i[2])
geo.add_schema(maptype='china',is_roam=False)
geo.add('',data,type_='heatmap',is_large=True, # 当图表数据量大时可设置为True
blur_size=10, # 光晕大小
point_size=2, # 点的大小
)
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=False,max_=1))
geo.render_notebook()

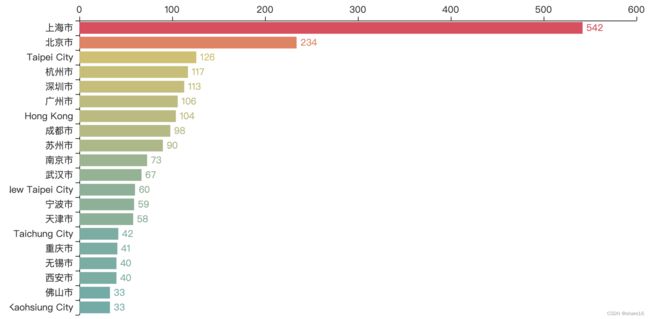
2.4.2 国内星巴克门店最多的20个城市
df_china = df[df.所在国家=='China']
b = df_china.groupby('所在城市').品牌名称.count().sort_values(ascending=False).reset_index().iloc[:20,:]
x_b,y_b = list(b.所在城市),list(b.品牌名称)
bar = Bar()
bar.add_xaxis(x_b)
bar.add_yaxis('',y_b,label_opts=opts.LabelOpts(position='right'))
bar.set_global_opts(xaxis_opts=opts.AxisOpts(position='top'),
yaxis_opts=opts.AxisOpts(is_inverse=True),
visualmap_opts=opts.VisualMapOpts(is_show=False,max_=300,dimension=0))
bar.reversal_axis()
bar.render_notebook()
谢谢大家