Elasticsearch:数据是如何被写入的?
在我之前的文章 “Elasticsearch:索引数据是如何完成的”,我详述了如何索引 Elasticsearch 的数据的。在今天的文章中,我将从另外一个视角来诠释如何写入数据到 Elasticsearch。更多关于 Elasticsearch 数据操作,请阅读文章 “Elasticsearch:彻底理解 Elasticsearch 数据操作”。
发送写请求时,它会通过我们路由机制。 此过程有助于确定哪个复制组(主分片及其副本分片统称为复制组,详细请阅读文章 “Elasticsearch:复制 - replication”)存储当前文档。
在写请求时,是有区别的。 写入请求直接发送到主分片,而不是复制组的任何分片。 写操作由这个主分片处理。
主分片的第一项工作是验证请求。 它检查请求的结构并验证字段值。 例如,尝试将一个类型为对象的字段输入到一个只应包含数字的字段中将导致主分片出现验证错误。

一旦请求通过了验证阶段,主分片就会在本地开始写入操作。 它确保数据在其自己的副本分片中正确写入和更新。
Elasticsearch通过这种方式保证数据准确高效地写入到复制组内的相关分片中。

为了提高性能,主分片将操作并行发送到其副本分片。重要的是要记住,即使无法复制到副本分片,该操作仍然会成功。
因此,简而言之,当收到写入请求时,它会被定向到主分片。 主分片验证操作,在本地执行,然后将其分发到其副本分片(如果适用)。
这是写入模型的高级概述,但让我们更深入地了解 Elasticsearch 如何处理数据复制错误。
由于 Elasticsearch 是分布式的,很多操作是异步发生的,所以可能会遇到硬件故障等问题。 不幸的是,这些故障随时可能发生并导致重大中断。 让我举个例子来证明这一点:
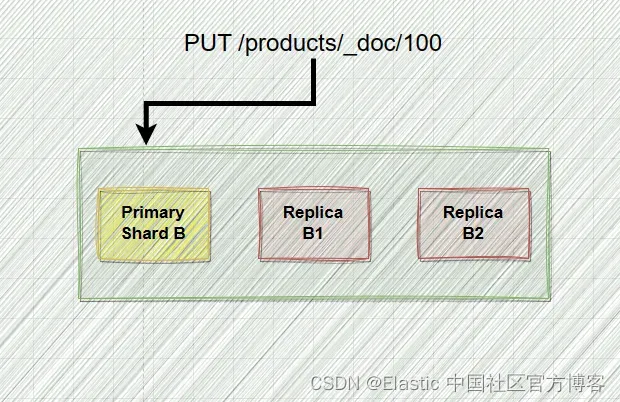
假设我们收到了一个要索引的新文档。 主分片处理操作验证和本地文档索引。 我们的复制组中有两个副本分片,主分片将操作传递给它们。
不幸的是,主分片在操作到达副本分片之一之前失败,这可能是由于硬件问题。

发生这种情况时,Elasticsearch 会启动恢复过程。 我不会详细介绍这个过程的复杂细节,因为它非常复杂。 但是,我可以告诉你,它涉及提升其中一个副本分片成为新的主分片,因为每个复制组都需要一个主分片。

这就是问题出现的地方。 剩下的两个分片没有相同的状态,因为其中一个成功地索引了新文档,而另一个则错过了。
没有接收到索引操作的副本分片误认为是最新的,但事实并非如此。
正如你可以想象的那样,从这一点开始,事情开始变得有些奇怪。 新文档只能有50%的几率被搜索到(这是因为 replica B2 不含有这个文档 ),这取决于哪个分片服务于检索它的请求。 这是一个非常混乱的情况!
这只是可能发生的潜在陷阱之一。 事实上,在任何给定时间,很多事情都可能出错。 虽然此类事件发生的可能性相对较低,但 Elasticsearch 为它们做好准备至关重要。 随着集群规模的增长以及节点数量的增加以及写入索引的数据量的增加,这一点变得更加重要。
幸运的是,Elasticsearch 通过称为 “Primary Terms and Sequence Numbers - 主要术语和序列号” 的功能解决了这些挑战和其他几个挑战。 在不深入研究错综复杂的技术的情况下,让我为你提供对这些概念的一般理解。
Primary terms 是 Elasticsearch 在复制组的主分片发生变化时区分新旧主分片的一种方式。
复制组的 Primary terms 本质上只是主分片更改次数的计数器。
在你刚刚看到的示例中,复制组的主项将增加 1,因为主分片发生故障,其中一个副本分片被提升为新的主分片。


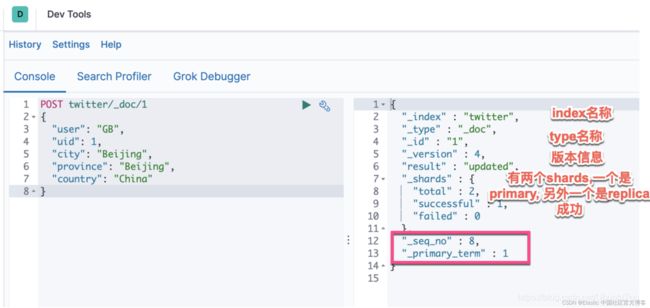
所有复制组的主要术语都保存在集群的状态中。 作为写操作的一部分发生的是,当前的 primary terms 被附加到发送到副本分片的操作。 这使副本分片能够判断主分片在转发操作后是否发生了变化。
虽然这种机制有助于 Elasticsearch 避免某些问题,但它本身是不够的。 除了将每个操作与 primary terms 相关联之外,还为每个操作分配了一个序列号。 这个序列号充当一个计数器,随着每个操作递增,至少直到主分片发生变化。
主分片负责在处理写入请求时增加序列号。 序列号帮助 Elasticsearch 跟踪特定主分片上发生的操作的顺序。
Primary terms 和序列号(sequence number)使 Elasticsearch 能够从主要分片发生变化的情况下恢复,例如由于网络错误。
它不是比较磁盘上的数据,而是可以使用主要术语和序列号来确定哪些操作已经完成,哪些是更新特定分片所必需的。
但是,在使用大型索引时,比较数百万个操作会出现问题,尤其是在高速索引和查询数据时。 为了加快这个过程,Elasticsearch 保留了全局和本地检查点,它们只是序列号。
每个复制组都有一个全局检查点,每个副本分片都有一个本地检查点。 全局检查点是复制组中所有活动分片达到或超过的序列号。 这意味着任何序列号低于全局检查点的操作都已经在复制组中的所有分片上执行过。
如果主分片失败并稍后重新加入集群,Elasticsearch 只需要比较它知道的最后一个全局检查点之后发生的操作。 类似地,如果副本分片失败,则只有序列号大于其本地检查点的操作在返回时才必须执行。
本质上,Elasticsearch 只需要检查分片无法恢复时发生的操作,而不是查看复制组的完整历史记录。 当然,这个过程有额外的复杂性,但我不想让你厌烦。
现在你已经了解了主要术语、序列号和检查点的基础知识,你应该能够很好地跟进。 请记住,主要术语和序列号在对写入请求的响应和使用其 ID 访问文档时都可用。