Python实战基础20-解密文件及目录操作
任务1 为泸州驰援湖北的89名白衣勇士点赞
【任务描述】
设计python程序,实现用户可以为泸州驰援湖北的89名白衣勇士点赞留言。用户点赞留言内容保存到本地txt文件中。
import os # 导入os模块
import random # 导入随机模块
import string # 导入string模块
# 定义4个变量,存储用户点赞留言信息txt文件的本地路径
path1 = r'C:\output\ekdfs.txt'
path2 = r'C:\output\ekdzyy.txt'
path3 = r'C:\output\fybj.txt'
path4 = r'C:\output\qita.txt'
# 存储西南医科大学附属医院援鄂医护人员名单列表
西南医科大学附属医院 = ['兰四友', '李 多', '邹永胜', '李 强', '吕朝霞', '姜 敏', '邱少平', '兰黎艳', '邢 婷', '王 倩', '钟起燕', '黄桂芳',
'杨 梅', '周 凯', '高晓岚', '梅松涛', '邹林帆', '冯 磊', '伍 松', '温远淇', '邓 俊', '刘 勇', '赵丽娜', '方蘅雯', '潘永建', '刘西焱', '刘孝元',
'贺 茜', '曹 鑫', '牟清梦', '陈菊屏', '刘 英', '徐 陶', '尹德锋', '李玉娟', '黄 敏', '曾晓春', '郑 丽', '何雪梅', '张春梅', '周虹羽', '吴宇超',
'敬 宏', '李 舒', '炜赵越', '刘春丽', '石春霞', '张 佳', '熊 宣', '喻 敏']
# 存储西南医科大学附属中医医院援鄂医护人员名单列表
西南医科大学附属中医医院 = ['雷 波', '刘 操', '林 玲', '许志刚', '罗 英', '高婧臻', '魏光蓉', '魏梦穗', '蓝晓维', '郑雪梅', '周春梅', '李 婧', '梁 敏', '涂连洁', '袁茂思',
'胡 蓉', '罗 婷', '李晓娟', '曾 理']
# 存储泸州市妇幼保健院医护人员名单列表
泸州市妇幼保健院 = ['何先夜', '王德明', '陈小兰', '李冬梅']
# 存储泸州市其它医院医护人员名单列表
古蔺县人民医院 = ['杨云满', '余 倩']
古蔺县中医医院 = ['刘 铭', '杨 莉']
叙永县人民医院 = ['刘 路', '龚太康']
叙永县中医医院 = ['余 洪', '杨 梅']
泸县中医医院 = ['胡 波', '胡 馨']
泸县第二人民医院 = ['何 春', '李国华']
合江县人民医院 = ['赵 艳', '吴中华']
合江县中医医院 = ['黄 胜', '汤 霞']
def OutputNameList(list): # 定义函数,功能:输出列表对应的援鄂医院人员名单,参数:list
j = 0
for i in range(len(list)): # 遍历医护人员列表列表
print(list[i], end=' ')
j += 1
if j % 5 == 0: # 每行输出5个名字
print("\n")
def OutputQtNameList(): # 定义函数,功能:打印输出泸州市其它区县医院驰援武汉白衣勇士全部名单,参数:无
print("泸州市其它区县医院驰援武汉医护人员共计16人。具体名单如下:")
print("古蔺县人民医院 :杨云满 余 倩 共2人")
print("古蔺县中医医院:刘 铭 杨 莉 共2人")
print("叙永县人民医院:刘 路 龚太康 共2人")
print("叙永县中医医院:余 洪 杨 梅 共2人")
print("泸县中医医院:胡 波 胡 馨 共2人")
print("泸县第二人民医院:何 春 李国华 共2人")
print("合江县人民医院:赵 艳 吴中华 共2人")
print("合江县中医医院:黄 胜 汤 霞 共2人")
def SavaMessage(path, message): # 定义函数,功能:将用户点赞留言写入到对应文件中,参数:path,message
file = open(path, "a") # 以追加模式打开文件
file.write("用户" + ran_strUserName + "的点赞留言:" + message + "\n") # 写入一条动态信息
file.close() # 关闭文件对象
if __name__ == '__main__':
print("========= 向泸州援鄂白衣勇士们致敬!!!! ========\n")
print(" (* ̄︶ ̄)春风十里,最美是战“役”的你(* ̄︶ ̄) ")
print(" 欢迎您为泸州援鄂医护人员点赞留言 \n")
print("******没有从天而降的英雄,只有挺身而出的凡人*******\n")
ran_strUserName = ''.join(random.sample(string.ascii_letters + string.digits, 5)) # 为用户生成随机用户名
end = 'y'
operC = 'n'
while end == 'y' or end == 'Y':
print("医院序号")
print("1 西南医科大学附属医院 ")
print("2 西南医科大学附属中医医院 ")
print("3 泸州市妇幼保健院 ")
print("4 泸州市其它区县医院 ")
print("\n请输入您要点赞的医院序号:", end="")
operC = input()
if str(operC) == '1': # 选择1 西南医科大学附属医院
print("西南医科大学附属医院驰援湖北医护人员共计" + str(len(西南医科大学附属医院)) + "人。具体名单如下:")
OutputNameList(西南医科大学附属医院)
print("\n请输入您要点赞的留言:", end="")
message = input() # 保存用户输入的点赞留言
SavaMessage(path1, message)
print("您的留言已被记录在:" + "C:\output\ekdfs.txt") # 打印出用户点赞留言保存的本地路径
print("\n谢谢您为西南医科大学附属医院援鄂医护人员点赞!\n")
elif operC == '2': # 选择2 西南医科大学附属中医医院
print("西南医科大学附属中医医院驰援武汉医护人员共计" + str(len(西南医科大学附属中医医院)) + "人。具体名单如下:")
OutputNameList(西南医科大学附属中医医院)
print("\n请输入您要点赞的留言:", end="")
message = input() # 保存用户输入的点赞留言
SavaMessage(path2, message)
print("您的留言已被记录在:" + "C:\output\ekdzyy.txt") # 打印出用户点赞留言保存的本地路径
print("\n谢谢您为西南医科大学附属中医医院医护人员点赞!\n")
elif operC == '3': # 选择3 泸州市妇幼保健院
print("泸州市妇幼保健院驰援武汉医护人员共计" + str(len(泸州市妇幼保健院)) + "人。具体名单如下:")
OutputNameList(泸州市妇幼保健院)
print("\n请输入您要点赞的留言:", end="")
message = input() # 保存用户输入的点赞留言
SavaMessage(path3, message)
print("您的留言已被记录在:" + "C:\output\\fybj.txt") # 打印出用户点赞留言保存的本地路径
print("\n谢谢您为泸州市妇幼保健院援鄂医护人员点赞!\n")
elif operC == '4': # 选择4 泸州市其它区县医院
OutputQtNameList()
print("\n请输入您要点赞的留言:", end="")
message = input() # 保存输入的点赞留言
SavaMessage(path4, message)
print("您的留言已被记录在:" + "C:\output\qita.txt") # 打印出用户点赞留言保存的本地路径
print("\n谢谢您为泸州市其它区县医院援鄂医护人员点赞!\n")
print("继续相关操作吗(y/n)?", end="")
end = input() # 输入结束字符
print("操作结束!")
运行结果:

用户点赞留言保存在本地txt文件
1 基本文件操作
在python中,内置了文件(File)对象。在使用文件对象时,首先需要通过内置的open()方法创建一个文件对象,然后通过该对象提供的方法进行 基本文件操作。
例如,使用文件对象的write()方法向文件中写入内容,以及使用closed方法关闭文件等。
1.1 创建和打开文件
想要操作文件需要现先创建或者打开指定的文件并创建文件对象,可以通过内置的open()函数实现。
语法格式:
file = open(filename[,mode[,buffering]])
参数说明:
file:被创建的文件对象
filename:要创建或打开文件的文件名称,需要使用单引号或双引号括起来。如果要打开的文件和当前文件在同一个目录下,那么直接写文件名即可,否则需要指定完整路径。
mode:可选参数,用于指定文件的打开模式,其参数值如下表,默认是打开模式为只读(即r)。
| 值 | 说明 | 注意 |
| r | 以只读模式打开文件,文件的指针将会放在文件的开头 | 文件必须存在 |
| rb | 以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头,一般用于非文本文件,如图片、声音等 |
|
| r+ | 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖) | |
| rb+ | 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等 | |
| w | 以只写模式打开文件 | 文件存在,则将其覆盖,否则创建新文件 |
| wb | 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等。 | |
| w+ | 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 | |
| wb+ | 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 | |
| a | 以追加模式打开个文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则创建新文件用于写入 | |
| ab | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则创建新文件用于写入 | |
| a+ | 以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则创建新文件用于读写 | |
| ab+ | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件末尾(即新内容会被写入到已有内容之后),否则创建新文件用于读写 |
Buffering:可选参数,用于指定读写文件的缓冲模式,指为0表示不缓存;值为1表示缓存;如果大于1,则表示缓冲区的大小。默认为缓存模式。
使用open()方法可以实现以下几种功能:
1.1.1 打开一个不存在的文件时先创建该文件
在默认情况下,使用open()函数打开一个不存在的文件,会抛出如下图的异常:

要解决上图错误,主要有以下几种方法:
(1)在当前目录下(即与执行的文件相同的目录)创建一个名称为test.txt的文件
(2)在调用open()函数时,指定mode的参数值为w、w+、a、a+。这样,当要打开的文件不存在时,就可以创建新的文件了。
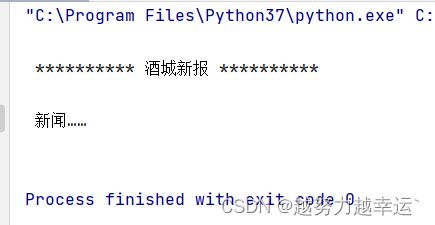
实例1:创建并打开酒城新报最新动态栏目的文件
首先输出一条提示信息,然后调用open()函数创建或打开文件,最后在输出一条提示信息。
print("\n","**********","酒城新报","**********")
file = open('message.txt','w') # 创建或打开保存酒城新报最新动态信息的文件
print("\n 新闻……\n")运行结果:
创建文件夹成功

1.1.2 以二进制形式打开文件
使用open()函数不仅仅可以以文本的形式打开文本文件,而且还可以以二进制形式打开非文本文件,如图片文件、音频文件、视频文件等。
例如,创建一个名为alcohol.png图片的文件,并且应用函数以二进制方式打卡该文件。
# 以二进制方式打开该文件,并输出创建的对象的代码
file = open("alcohol.png",'rb')
print(file)运行结果:
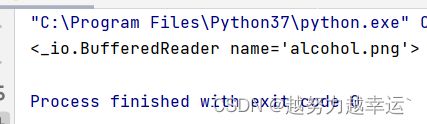
从上图可看出,创建的是一个BufferedReader对象。对于该对象生成后,可以再应用其它的第三方模块进行处理。
1.2 关闭文件
打开文件后,需要及时关闭,以免对文件造成不必要的破坏。关闭文件可以使用close()方法。
语法格式:
file.close()
1.3 打开文件时使用with语句
如果打开文件时抛出了异常,那么将导致文件不能被及时关闭。
为了更好的避免此类问题发生,可以使用Python提供的with语句,从而实现在处理文件时,无论是否抛出异常,都能保证with语句执行完毕后关闭已经打开的文件。
语法格式:
with expression as target:
with-body
参数说明:
Expression:用于指定一个表达式,这里可以是打开文件的open()函数。
target:用于指定一个变量,并且将expression的结果保存到该变量中。
with-body:用于指定with语句体,其中可以是执行with语句后相关的一些操作语句。如果不想执行任何语句,可以直接使用pass语句代替。
print("\n","**********","酒城新报","**********")
with open('message.txt','w') as file: # 创建或打开保存酒城新报最新动态信息的文件
pass
print("\n 新闻……\n")1.4 写入文件内容
在实例1中,虽然创建了并打开了一个文件,但是该文件中没有任何内容,它的大小是0KB。python的文件对象提供了write()方法,可以先文件中写入内容。
语法格式:
File.write(string)
其中,file为打开的文件对象;string为要写入的字符串。
实例2:向酒城新报的最新动态文件写入一条信息
首先应用open()函数以写方式打开一个文件,然后再调用write()方向该文件中写入一条动态信息,再调用close()方法关闭文件
print("\n","**********","酒城新报","**********")
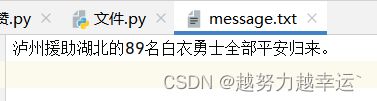
file = open('message.txt','w') # 创建或打开保存酒城新报最新动态信息的文件
#写入一条动态信息
file.write("泸州援助湖北的89名白衣勇士全部平安归来。 \n")
print('写入了一条新动态。。。。\n')
file.close() # 关闭文件对象message.txt文件
注意:在写入文件后,一定要调用close()方法关闭文件,否则写入的内容不会保存到文,件中。
多学两招:使用writelines()方法,可以向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要制定换行符\n。
1.5 读取文件
1.5.1 读取指定字符串
语法格式:
file.read([size]}
参数说明:
file:为打开的文件对象
size:可选参数,用于指定要读取的字符个数,如果省略,则一次性读取所有内容。
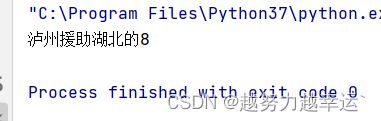
例如,要读取message.txt文件中的前8个字符
with open('message.txt','r') as file: # 打开文件
string = file.read(8) # 读取前8个字符
print(string)运行结果:
使用read(size)方法读取文件时,是从文件的开头读取。如果想要读取部分内容,可以先使用文件对象的seek()方法将文件的指针移动到新的位置,然后再应用read(size)方法读取。
语法格式:
file.seek(offest[,whence])
参数说明:
file:表示已经打开的文件对象
offset:用于指定移动的字符个数,其具体位置与whence参数有关。
whence:用于指定从什么位置开始计算。值为9表示从文件头开始计算,值为1表示从当前位置开始计算,值为2表示从文件尾开始计算,默认为0.
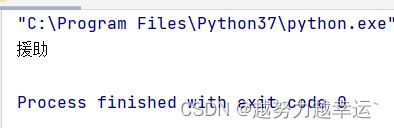
想要从文件的第4个字符开始读取2个字符
with open('message.txt','r') as file: # 打开文件
file.seek(4) # 移动文件指针到新的位置
string = file.read(2)# 读取2个字符
print(string)message.txt里的内容

运行结果:
说明:再使用seek()方法时,如果采用GBK编码,那么offset的值是按一个汉字(包括中文标点符号)占两个字符计算,而采用utf-8编码,则一个汉字占3个字符,不过无论采用何种编码英文和数字都是按一个字符计算的。这与read(size)方法不同。
实例3,显示酒城新报最新动态栏目内容
print("\n","="*20,"酒城新报最新动态栏目内容","="*20,"\n")
with open('message.txt','r') as file: # 打开保存酒城新报最新动态栏目内容的文件
message = file.read() # 读取全部动态信息
print(message) # 输出动态信息
print("\n","="*28,"over","="*28,"\n")运行结果:

1.5.2 读取一行
使用readline()方法读取一行数据
语法格式:
file.readline()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)。
实例4,逐行显示酒城新报最新动态栏目的内容
print("\n","="*20,"酒城新报最新动态栏目内容","="*20,"\n")
with open('message.txt','r') as file: # 打开保存酒城新报最新动态栏目内容的文件
number = 0 # 记录行号
while True:
number += 1
line = file.readline()
if line =='':
break # 跳出循环
print(number,line,end= "\n") # 输出一行内容
print("\n","="*28,"over","="*28,"\n")运行结果:

1.5.3 读取全部行
语法格式:
file.readlines()
同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)
print("\n","="*20,"酒城新报最新动态栏目内容","="*20,"\n")
with open('message.txt','r') as file: # 打开保存酒城新报最新动态栏目内容的文件
message = file.readlines()#读取全部动态信息
print(message) # 输出动态信息
print("\n","="*28,"over","="*28,"\n")运行结果:

从该运行结果可以看出,readlines()方法的返回值为一个字符串列表。在这个字符串列表中,每个元记录一行内容。如果文件比较大时,可以将列表的内容逐行输出。
print("\n","="*20,"酒城新报最新动态栏目内容","="*20,"\n")
with open('message.txt','r') as file: # 打开保存酒城新报最新动态栏目内容的文件
messageall = file.readlines()
for message in messageall:
print(message)
print("\n", "=" * 28, "over", "=" * 28, "\n")运行结果:

任务2 实现白酒资料分类整理功能
实现alcohol文件夹中的图片和文档能够分别存放到对应的文件夹中。
import os, shutil # 导入os模块和shutil模块
def goThroughFiles(path): # 遍历目录函数 参数: path为原始路径
print("【", path, "】 目录下包括的文件和目录:")
for root, dirs, files in os.walk(path, topdown=True): # 遍历指定目录
for name in dirs: # 循环输出遍历到的子目录
print("●", os.path.join(root, name))
for name in files: # 循环输出遍历到的文件
print("◎", os.path.join(root, name))
def crateFiles(path): # 创建目录函数 参数: path为要创建目录路径
if not os.path.exists(path): # 判断目录是否存在
os.mkdir(path) # 创建目录
print("目录创建成功! ")
print("新创建的目录路径为:" + path)
else:
print("该目录已经存在! ")
def moveFiles(path, new_path, dir_type): # 移动文件函数 参数: path为原始路径,new_path是移动到的目标目录,dir_type为数据类型
for root, dirs, files in os.walk(path): # 取得该文件夹下的所有文件
for i in range(len(files)):
if dir_type == 'Pic': # 数据类型为图片
if (files[i][-3:] == 'jpg') or (files[i][-3:] == 'png') or (files[i][-3:] == 'JPG'):
file_path = root + '/' + files[i]
new_file_path = new_path + '/' + files[i]
shutil.move(file_path, new_file_path) # 将每张图片依次移动到新目录下
elif dir_type == 'Word': # 数据类型为文档
if (files[i][-3:] == 'doc') or (files[i][-4:] == 'docx') or (files[i][-3:] == 'wps'):
file_path = root + '/' + files[i]
new_file_path = new_path + '/' + files[i]
shutil.move(file_path, new_file_path) # 将每个文档依次移动到新目录下
if __name__ == '__main__': # 主函数
print("====白酒资料分类整理====")
path = 'D:\\Alcohol'
print("遍历目录:")
goThroughFiles(path) # 遍历目录
Pic_path = 'D:\\Alcohol\\Pic'
Word_path = 'D:\\Alcohol\\Word'
print("分别创建两个分类子目录 —— Pic和Word:")
crateFiles(Pic_path) # 创建新目录
crateFiles(Word_path) # 创建新目录
print("将所有图片移动到子目录Pic文件夹中:")
moveFiles('D:\\Alcohol', Pic_path, 'Pic') # 移动图片
print("successful! 已完成移动!")
print("将所有文档移动到子目录Word文件夹中:")
moveFiles('D:\\Alcohol', Word_path, 'Word') # 移动文档
print("successful! 已完成移动!")
print("整理结束后,再次遍历目录:")
goThroughFiles(path) # 遍历目录
第5-17行使用os模块的walk()函数用于实现遍历目录的功能。
第11行代码使用os模块的mkdir()函数实现目录的创建。
第23和第28行使用shutil模块的move()函数实现将每张图片/文档依次移动到新目录下。
2 目录操作
使用内置的os和os.path模块实现直接操作目录。
注意:os模块是python内置的操作系统功能和文件系统相关的模块。该模块中的语句执行通常与操作系统有关,在不同的操作系统上,可能会得到不一样的结果。
常用的目录操作主要有判断目录是否存在、创建目录、删除目录和遍历目录等。
2.1 os和os.path语句
导入OS模块
import os
说明:导入os模块后,也可以使用其子模块os.path,os模块常有的变量有:
- name:用于获取操作系统类型。例如:os.name输出的结果为nt,则表示是Windows操作系统;如果是posix,则表示是Linux,Unix或Mac OS操作系统。
- linesep:用于获取当前操作系统上的换行符
- sep:用于获取当前操作系统所使用的路径分隔符
| 函数 | 说明 |
| os.getcwd() | 返回当前的工作目录 |
| os.listdir(path) | 返回指定路径下的文件和目录信息 |
| os.mkdir(path[, mode]) | 创建目录 |
| os.makedirs(path1/path2…[, mode]) | 创建多级目录 |
| os.rmdir(path) | 删除目录 |
| os.removedirs(path1/path2…) | 删除多级目录 |
| os.chdir(path) | 把path设置为当前工作目录 |
| os.walk(top[, topdown[, onerror]]) | 遍历目录树,该方法返回一个元组,包括所有路径名、所有目录列表和文件列表3个元素 |
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回 path 的绝对路径。 |
| os.path.basename(path) | 获取 path 路径的基本名称,即 path 末尾到最后一个斜杠的位置之间的字符串。 |
| os.path.commonprefix(list) | 返回 list(多个路径)中,所有 path 共有的最长的路径。 |
| os.path.dirname(path) | 返回 path 路径中的目录部分。 |
| os.path.exists(path) | 判断 path 对应的文件是否存在,如果存在,返回 True;反之,返回 False。和 lexists() 的区别在于,exists()会自动判断失效的文件链接(类似 Windows 系统中文件的快捷方式),而 lexists() 却不会。 |
| os.path.lexists(path) | 判断路径是否存在,如果存在,则返回 True;反之,返回 False。 |
| os.path.expanduser(path) | 把 path 中包含的 "~" 和 "~user" 转换成用户目录。 |
| os.path.expandvars(path) | 根据环境变量的值替换 path 中包含的 "$name" 和 "${name}"。 |
| os.path.getatime(path) | 返回 path 所指文件的最近访问时间(浮点型秒数)。 |
| os.path.getmtime(path) | 返回文件的最近修改时间(单位为秒)。 |
| os.path.getctime(path) | 返回文件的创建时间(单位为秒,自 1970 年 1 月 1 日起(又称 Unix 时间))。 |
| os.path.getsize(path) | 返回文件大小,如果文件不存在就返回错误。 |
| os.path.isabs(path) | 判断是否为绝对路径。 |
| os.path.isfile(path) | 判断路径是否为文件。 |
| os.path.isdir(path) | 判断路径是否为目录。 |
| os.path.islink(path) | 判断路径是否为链接文件(类似 Windows 系统中的快捷方式)。 |
| os.path.ismount(path) | 判断路径是否为挂载点。 |
| os.path.join(path1[, path2[, ...]]) | 把目录和文件名合成一个路径。 |
| os.path.normcase(path) | 转换 path 的大小写和斜杠。 |
| os.path.normpath(path) | 规范 path 字符串形式。 |
| os.path.realpath(path) | 返回 path 的真实路径。 |
| os.path.relpath(path[, start]) | 从 start 开始计算相对路径。 |
| os.path.samefile(path1, path2) | 判断目录或文件是否相同。 |
| os.path.sameopenfile(fp1, fp2) | 判断 fp1 和 fp2 是否指向同一文件。 |
| os.path.samestat(stat1, stat2) | 判断 stat1 和 stat2 是否指向同一个文件。 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组。 |
| os.path.splitdrive(path) | 一般用在 windows 下,返回驱动器名和路径组成的元组。 |
| os.path.splitext(path) | 分割路径,返回路径名和文件扩展名的元组。 |
| os.path.splitunc(path) | 把路径分割为加载点与文件。 |
| os.path.walk(path, visit, arg) | 遍历path,进入每个目录都调用 visit 函数,visit 函数必须有 3 个参数(arg, dirname, names),dirname 表示当前目录的目录名,names 代表当前目录下的所有文件名,args 则为 walk 的第三个参数。 |
| os.path.supports_unicode_filenames | 设置是否可以将任意 Unicode 字符串用作文件名。 |
2.2 路径
用于定位一个文件或者目录的字符串被称为一个路径。
2.2.1 相对路径
- 相对路径:是从当前文件所在的文件夹开始的路径
- test.txt,是在当前文件夹查找 test.txt 文件
- ./test.txt,也是在当前文件夹里找test.txt 文件,./表示的是当前文件夹。
- ../test.txt,从当前文件夹的上一级文件夹里查找test.txt文件。 ../ 表示的是上一级文件夹
- demo/test.txt,在当前文件夹里查找 demo 这个文件夹,并在这个文件夹里查找 test.txt文件
import os
print(os. getcwd()) #输出当前目录
with open("demo/message.txt" ) as file: #通过相对路径打开文件
pass多学两招:在指定文件路径时,也可以在表示路径的字符串前面加上字母r(或R),那么该字符串将原样输出,这时路径的分隔符就不需要再转义了。
2.2.2绝对路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的。
- 例 :如:C:/Users/chris/AppData/Local/Programs/Python/Python37/python.exe,从电脑的盘符开始,表示的就是一个绝对路径。
import os
print(os.path.abspath(r"demo\message.txt")) #获取绝对路径2.2.3 拼接路径
可以使用os.path模块提供的join()函数实现。
语法格式:
os.path.join(path1[,path2[,...]])
其中,path1,path2用于代表要拼接的文件路径,这些路径间使用逗号进行分隔。如果在要拼接的路径中,没有一个绝对路径,那么最后拼接出来的是一个相对路径。
import os
print(os.path.join("E:\example" ,"demo\message.txt" ))#拼接字符串说明:在使用join()函数时,如果要拼接的路径中,存在多个绝对路径,那么以从左到右为序最后一次出现的路径为准,并且该路径之前的参数都将被忽略。
import os
print(os.path.join("E:\example" ,"demo\message.txt" ))#拼接字符串注意:
- 使用os.path.join()函数拼接路径时,并不会检测该路径是否真实存在。
- 把两个路径拼接为一个路径时,不要直接使用字符串拼接,而是使用os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。
2.3 判断目录是否存在
语法结构:
os.path.exists(path)
path为要判断的目录,可以采用绝对路径,也可以采用相对路径
返回值:如果给定的路径存在,则返回True,否则返回False
import os
print(os.path.exists("C:\\demo")) #判断目录是否存在说明:os.path.exists()函数除了可以判断目录是否存在,还可以判断文件是否存在。
2.4 创建目录
2.4.1 创建一级目录
语法格式:
os.mkdir(path,mode=0o777)
参数说明:
path:用于指定要创建的目录,可以使用绝对路径,也可以使用相对路径
mode:用于指定数值模式,默认值0777。该参数在非UNIX系统上无效或被忽略。
# 在windows系统上创建一个C:\demo目录
import os
print(os.mkdir("C:\\demo")) # 创建C:\demo目录 如果在创建时已经存在将抛出异常FileExisteError异常。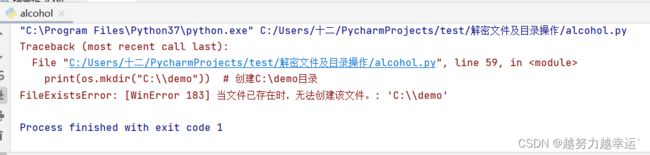
要解决上面的问题,可以在创建目录前,先判断指定的目录是否存在,只有当目录不存在时,才创建。
import os
path = "C:\\demo" #指定要创建的目录
if not os.path. exists(path): #判断目录是否存在
os. mkdir(path) #创建目录
print("目录创建成功! ")
else:
print("该目录已经存在! ")如果指定的目录有多级,而且最后一级的上级目录中有不存在的,则抛出FileNotFoundError异常,并且目录创建不成功。有两种解决方法:1、使用创建多级目录; 2、编写递归函数调用os.mkdir()函数实现。
import os #导入标准模块os
def mkdir(path): #定义递归创建目录的函数
if not os. path. isdir(path): #判断是否为有效路径
mkdir(os. path. split(path)[0]) #递归调用
else: #如果目录存在,直接返回
return
os.mkdir(path) #创建目录
mkdir("D:/mr/test/demo" ) #调用mkdir递归函数2.4.2 创建多级目录
makedirs()函数,该函数用于采用递归的方式创建目录。
语法格式:
os.makedirs(name,mode=0o777)
参数说明:
name:用于指定要创建的目录,可以使用绝对路径,也可以使用相对路径
mode:用于指定数值模式,默认值0777.该参数在非UNIX系统上无效或被忽略。
import os
os.makedirs("C:\\demo\\test\\dir\\mr")#创建C:\demo\test\dir\mr目录2.5 删除目录
语法格式:
os.rmdir(path)
import os
os.rmdir("C:\\demo\\test\\dir\\mr") #删除C:\demo\test\dir\mr目录注意:如果要删除的目录不存在,那么将抛出”FileNotFoundError:[WinError2]系统找不到指定文件“异常。因此,在执行os.rmdir()函数前,要先判断该路径是否存在。可使用os.path.exists()
import os
path = "C:\\demo\\test\\dir\\mr" #指定要创建的目录
if os. path. exists (path): #判断目录是否存在
os.rmdir("C:\\demo\\test\\dir\\mr") #删除目录
print("目录删除成功! ")
else:
print("该目录不存在! ")多学两招:使用rmdir()函数只能删除空的目录,如果想要删除非空目录,则需要使用shutil的rmtree()函数。
import shutil
shutil.rmtree( "C:\\demo\\test" ) #删除C:\demo目录下的test子目录及其内容2.6 遍历目录
walk()函数的语法格式:
os.walk(top[,topdown],[,onerror][,followlinks])参数说明:
top:用于指定要遍历内容的根目录
topdown:可选参数,用于指定遍历的顺序,如果值为True,表示自上而下遍历(即先遍历根目录);如果值为False,表示自下而上遍历(即先遍历最后一级子目录),默认值为True。
onerror:可选参数,用于指定错误处理方式,默认为忽略。如果不想忽略也可以指定一个错误处理函数。
followlinks:可选参数,默认情况下,walk()函数不会向下转换成解析到目录的符号链接,将该参数值设置为True,表示用于指定在支持的系统上访问由符号链接指向的目录。
返回值:返回一个包括3个元素(dirpath,dimames,filenames)的元组生成器对象。其中,dirpath表示当前遍历的路径,是一个字符串;dimames表示当前路径下包含的子目录,是一个列表;filenames表示当前路径下包含的文件,也是一个列表。
import os #导入os模块
tuples = os.walk("E:\\example")#遍历"E:\example"目 录
for tup1e1 in tuples : #通过for循环输出遍历结果
print(tup1e1 ,"\n") #输出每一级目录的元组注意:walk()函数只在Unix系统和Windows系统中有效。
实例5,遍历指定目录
import os # 导入os模块
path = "E:\\example" # 指定要遍历的根目录
print("【",path,"】 目录下包括的文件和目录:")
for root, dirs, files in os.walk(path, topdown=True):#遍历指定目录
for name in dirs: # 循环输出遍历到的子目录
print("●",os.path.join(root, name))
for name in files: # 循环输出遍历到的文件
print("◎",os.path.join(root, name))
3 高级文件操作
| 函数 | 说明 |
| access(path,accessmode) | 获取对文件是否有指定的访问权限(读取/写入/执行权限)。accessmode的值是R_OK(读取)、W_OK(写入)、X_OK(执行)或F_OK(存在如果有指定的权限,则返回1,否则返回0) |
| chmod(path,mode) | 修改path指定文件的访问权限 |
| remove(path) | 删除path指定的文件路径 |
| rename(src,dst) | 将文件或目录src重命名为dst |
| stat(path) | 返回path指定文件的信息 |
| startfile(path [,operation]) | 使用关联的应用程序打开path指定的文件 |
3.1 删除文件
语法格式:
os.remove(path)
path为要删除的文件路径,可以使用相对路径,也可以使用绝对路径。
例如,删除当前工作目录下的test.txt文件
import os # 导入os模块
os.remove('test.txt') # 删除当前工作目录下的test.txt文件执行上面的代码后可,如果在当前工作目录下存在test.txt,即可将其删除,否则显示如下图的异常:

为了避免以上异常,可以在删除文件时,先判断文件是否存在,只有存在时才执行删除操作。
import os #导入os模块
path = "test.txt" #要删除的文件
if os.path.exists(path): #判断文件是否存在
os.remove(path) #删除文件
print("文件删除完毕! ")
else:
print("文件不存在!")3.2 重命名文件和目录
语法格式:
os.rename(src,dst)
其中,src用于指定要进行重命名的目录或文件;dst用于指定重命名后的目录或文件。
同删除文件一样,在进行文件或目录重命名时,如果指定的目录或文件不存在,也将抛出FileNotFoundError异常,所以在进行文件或目录重命名时,也建议先判断文件或目录是否存在,只有存在时才进行重命名操作。
例如,想要将“C:\output\dir\test.txt”文件重命名为:“C:\output\dir\message.txt”
import os #导入os模块
src = r'C:\output\dir\test.txt' #要重命名的文件
dst = r'C:\output\dir\message.txt' #重命名后的文件
if os.path.exists(src): #判断文件是否存在
os.rename(src, dst) #重命名文件
print("文件重命名完毕! ")
else:
print("文件不存在! ")使用rename()函数重命名目录与命名文件基本相同,只要把原来的文件路径替换为目录即可。
例如,想要将当前目录下的demo目录重名名test
import os #导入os模块
src = "demo" #重命名的当前目录下的demo
dst = "test" #重命名为test
if os.path.exists(src): #判断目录是否存在
os. rename(src,dst) #重命名目录
print("目录重命名完毕! ")
else:
print("目录不存在! ")在使用rename()函数重命名目录时,只能修改最后一级的目录名称,否则将抛出异常
import os #导入os模块
src = r"C:\output\dir\demo" #重命名的demo上一级目录dir
dst = r"C:\output\test\demo" #重命名为test
if os.path.exists(src): #判断目录是否存在
os. rename(src,dst) #重命名目录
print("目录重命名完毕! ")
else:
print("目录不存在! ")运行结果:

3.3 获取文件基本信息
语法结构:
os.stat(path)
其中,path为要获取文件基本信息的文件路径,可以是相对路径,也可以是绝对路径。stat()函数的返回值是一个对象,该对象包含如下表的属性。通过访问这些属性可以获取文件的基本信息。
| 属性 | 说明 | 属性 | 说明 |
| st_mode | 保护模式 | st_dev | 设备名 |
| st_ino | 索引号 | st_uid | 用户ID |
| st_nlink | 硬链接号(被连接数目) | st_gid | 组ID |
| st_size | 文件大小,单位为字节 | st_atime | 最后一次访问时间 |
| st_mtime | 最后一次修改时间 | st_ctime | 最后一次状态变化的时间(系统不同返回结果也不同,例如,在Windeows操作系统下返回的是文件的创建时间) |
实例6,获取文件基本信息
import os # 导入os模块
fileinfo = os.stat("message.txt") # 获取文件的基本信息
print("文件完整路径:", os.path.abspath("message.txt")) # 获取文件的完整数路径
# 输出文件的基本信息
print("索引号:",fileinfo.st_ino)
print("设备名:",fileinfo.st_dev)
print("文件大小:",fileinfo.st_size," 字节")
print("最后一次访问时间:",fileinfo.st_atime)
print("最后一次修改时间:",fileinfo.st_mtime)
print("最后一次状态变化时间:",fileinfo.st_ctime)运行结果:

由于上面的结果中的时间和字节数都是一长串的整数,与平时见到的不同,所以一般情况下,为了让显示更加直观,还需要对其进行格式化。
这里主要编写两个函数,一个用于格式化时间,另一个用于格式化代表文件大小的字节数。
import os # 导入os模块
def formatTime(longtime):
'''格式化日期时间的函数
longtime:要格式化的时间
'''
import time # 导入时间模块
return time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(longtime))
def formatByte(number):
'''格式化日期时间的函数
number:要格式化的字节数
'''
for (scale,label) in [(1024*1024*1024,"GB"),(1024*1024,"MB"),(1024,"KB")]:
if number>= scale: # 如果文件大小大于等于1KB
return "%.2f %s" %(number*1.0/scale,label)
elif number == 1: # 如果文件大小为1字节
return "1 字节"
else: # 处理小于1KB的情况
byte = "%.2f" % (number or 0)
return (byte[:-3] if byte.endswith('.00') else byte)+" 字节" # 去掉结尾的.00,并且加上单位“字节”
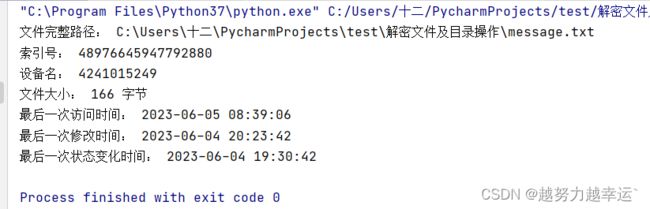
if __name__ == '__main__':
fileinfo = os.stat("message.txt") # 获取文件的基本信息
print("文件完整路径:", os.path.abspath("message.txt")) # 获取文件的完整数路径
# 输出文件的基本信息
print("索引号:", fileinfo.st_ino)
print("设备名:", fileinfo.st_dev)
print("文件大小:", formatByte(fileinfo.st_size))
print("最后一次访问时间:", formatTime(fileinfo.st_atime))
print("最后一次修改时间:", formatTime(fileinfo.st_mtime))
print("最后一次状态变化时间:", formatTime(fileinfo.st_ctime))
运行结果: