SIM:基于搜索的用户终身行为序列建模
SIM:基于搜索的用户终身行为序列建模
论文:《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》
下载地址:https://arxiv.org/abs/2006.05639
1、用户行为序列建模回顾
1.1 Pooling方式
Pooling方式最简单的就是对用户行为序列中的每个item做embedding后,进行max/mean-pooling,代表的论文是youtube的《Deep Neural Networks for YouTube Recommendations》,将用户观看过的视频序列取到embedding后,做了一个mean pooling作为用户历史兴趣的表达。
mean-pooling的方式将用户点击过的各个item当做同等重要。但实际上,用户点过的item对任务的贡献度是不同的,user历史上点过的和target item同一类目的item明显会起到更加重要的作用。在DIN中,将attention思想引入到行为序列建模中。将target item和行为序列中的item做一个attention,得到一个weight,然后进行加权求和来表征用户的兴趣。
1.2 RNN/Transformer方式
pooling方式没有考虑用户行为序列发生的先后顺序。将行为序列顺序引入到模型中,可以使用RNN及其变种LSTM/GRU。如DIEN中使用GRU对用户的兴趣进行抽取和使用AUGRU来表示用户兴趣的演化过程。
但RNN方式的一大缺点是对用户行为序列进行串行计算,耗时相对来说还是较高一些,可以考虑将RNN替换为Transformer的方式,来实现行为序列的并行计算,如阿里的BST。使用Transormer时需要结合行为的先后顺序信息,如在BST中,将当前时间戳和用户行为发生时间戳的差值离散化后的embedding加入到输入信息中。
更进一步,通过观察用户行为,发现用户在每个会话中的行为是相近的,而在不同会话之间差别是很大的,考虑这种跟Session相结合的用户行为序列,又有了DSIN。
1.3 多兴趣抽取
前面介绍的大多数算法仅仅将用户的兴趣表示成单个的Embedding,但用户的兴趣是多种多样的,使用单一的用户兴趣embedding容易造成头部效应。因此在MIND中,通过胶囊网络来生成多个表征用户兴趣的Embedding,来提升召回阶段的效果。
1.4 长用户行为建模
上述模型大都是直接输入用户行为序列中的item id列表,线上耗时限制导致长度不能太长,如DIEN模型,当QPS(每秒请求量)为500时,用户行为序列长度为1000时,DIEN的延迟达到了200ms,这显然是不能接受的。因此上述模型更多的是去刻画用户的短期兴趣,基于用户的短期行为进行建模让用户很容易被近期热点和大多数所代表,同时也无法建模用户长期以来坚持的兴趣,如品质、风格方面长期才能反映的喜好。
那么如何引入更长的用户行为序列,来进一步刻画用户的长期兴趣呢?SDM提供了一种思路,其主要的思想是:将用户的行为分为两种,第一个是近期的行为,另一个是之前较长的行为,这部分行为会按照店铺、品牌、品类进行聚类,来刻画用户对品质、风格方面长期才能反映的喜好。比如用户只买阿迪的鞋子或者只买帆布鞋等等。
另一种思路时考虑预先对行为序列做一些信息压缩。MIMN利用兴趣 memory 来建模用户的原始行为,将用户原始行为进行归纳和抽象为用户抽象的兴趣表达。同时设计了了UIC模块来存储固定大小的用户抽象的兴趣表达 memory,解决了线上耗时的问题。
但MIMN将大量用户行为压缩成为固定大小的兴趣 memory 的过程中,存在信息损失。当用户行为膨胀到数万数十万时,有限的兴趣 memory 向量维度难以完整记录用户原始的行为信息。
那么有没有一种方案是直接列用用户原始的行为,而且能够解决上万长度的用户序列的耗时问题呢?一种解决方案便是本文将要介绍的Search-based User Interest Model。
2、基于搜索的用户终身行为建模
2.1 整体介绍
首先回顾一下DIN的核心思路,DIN本质就是从用户行为序列中寻找跟target item相近的用户行为,来建模用户相关的兴趣。基于此,能否预先从用户历史行为中找到跟target item相近的物品,来减少行为序列的长度,再使用DIN或DIEN等模型来建模用户的兴趣?
阿里提出的Search-based User Interest Model(SIM)通过两阶段的方式,来对用户终身行为序列进行建模。其整体框架如下:
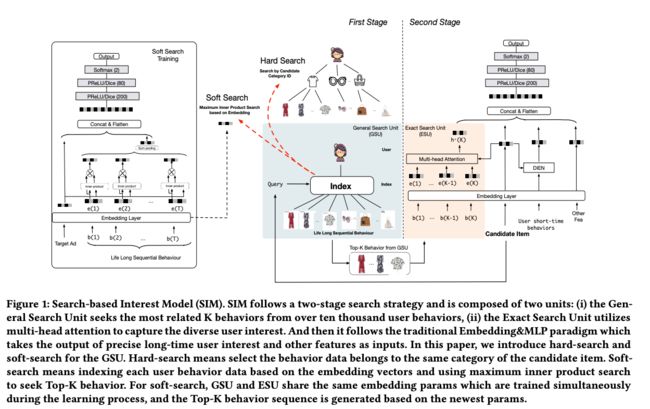
在第一个阶段,通过General Search Unit,从用户行为序列找到K个与目标物品最为相关的序列结合,K要远远小于用户总的行为序列长度;在第二个阶段,使用前一阶段得到的较短的行为序列,通过Exact Search Unit来精准建模用户的兴趣,可以采用类似DIN或者DIEN等复杂的模型。接下来,主要对这两个Unit进行介绍。
2.2 General Search Unit
对于给定的目标item,只有一部分的与该item关系紧密的用户行为是有价值的,这部分的用户行为对于用户最终的决策起到了更为重要的作用。因此,通过General Search Unit去找到这部分的行为序列。搜索的方式包括两种,hard-search和soft-search,其表示如下:

对于hard-search来说,直接根据品类去搜索,其中Ca代表目标item的品类,Ci代表用户行为序列中第i个item的品类。为了更高效的搜索,对于用户行为的存储采取了用户行为树的方式,如下图所示:
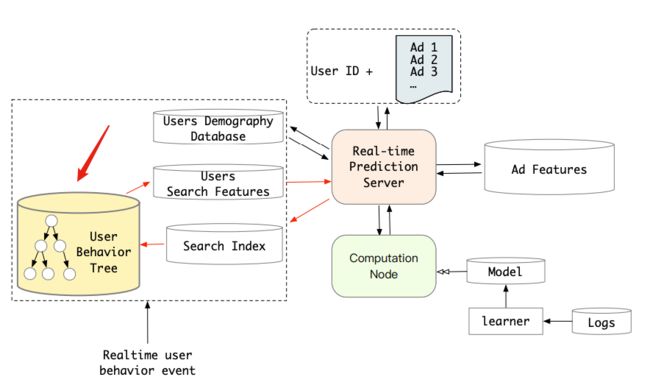
用户行为采用Key-Key-Value的树结构进行存储,第一层的Key代表用户id,第二层的Key代表品类Id,第三层的Value则是该品类下的用户行为。
对于soft-search来说,利用目标item和行为序列中item的embedding,通过内积的方式计算二者的相似度,线上应用的时候,采用局部敏感HASH的方式进行高效的搜索。item的embedding通过如下的网络训练得到【这不就是DIN么,一模一样!!!】:

那么阿里实际应用的是哪种方式呢?通过统计发现,通过soft-search得到结果和hard-search非常接近,品类相同的item拥有更高的相似度,尽管soft-search的效果略好于hard-search,但是综合考虑性能和计算耗时,最终还是选择了hard-search的方式。
同时值得一提的是,用户行为序列的长度会被截断到200,来保证线上的耗时满足要求。
2.3 Exact Search Unit
在第一个stage,我们得到了长度较短的用户子行为序列,那么在第二个阶段,通过Exact Search Unit并结合子行为序列和目标item,来精确建模用户的兴趣。
论文中的ESU采用的是Multi-head attention的结构【换成其他的也可以】,同时为每一个用户行为引入了时间状态属性。对于每一个历史行为,计算该行为发生时间距当前时间的时间差,离散化之后转换为对应的embedding作为输入【类似bert 位置embedding的方式】。时间离散化的方式没有指明,一种可以参考的方式是通过2的幂次进行离散化。

最终的Loss是两个阶段的loss的和,每个阶段的Loss都是logloss:
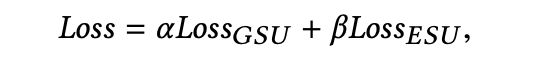
如果采用hard-soft的方式的话,GSU阶段其实是无参数的,该部分loss的权重为0。
3、实验结果
最后来看一下SIM的实验效果,首先看一下在淘宝数据集和阿里工业数据集(展示广告数据集)的表现:

具体的实验结果咱们看看就好,不过这里有一点还是比较有意思,首先我们定义一下d_category:这里指的是与用户点击的item 品类相同的行为最近发生日期离当前的天数。假设当前用户点击了一双球鞋,上一次点击球鞋是15天前,那么对该用户来说,球鞋这个品类的d_category=15。
如果把14天以内定义为短期,14天以上定义为长期,下图代表了不同d_category下,SIM和DIEN推荐且被用户点击的item的分布,以及SIM相对于DIEN的点击数量的提升:

图中40-60这个部分,指模型推荐且被用户点击的item,其相同类目的行为最早发生在过去的40-60天内,可以看到虽然SIM和DIEN的推荐并点击的结果主要集中在近期部分,但是在长期部分SIM的推荐且被点击的数量显著高于DIEN。这从侧面说明SIM相对更好的建模了长期兴趣。
[1].推荐系统遇上深度学习(八十七)-[阿里]基于搜索的用户终身行为序列建模