数据结构之堆的应用
在我们学习了堆之后我们知道,无论是大堆还是小堆,堆顶的元素要么最大,要么最小。
对于堆插入的时间复杂度为O(logn)也就是向上调整算法的复杂度,删除一个堆中的元素为O(logn),堆在我们日常生活中还是常用到的。
目录
1.top k问题(优质筛选问题)
2.堆排序
1.向上调整建堆
建小堆-----最后排序为降序
建大堆------最后排序为升序
2.向下调整建堆
建小堆--排序结果为降序
建大堆---排序结果为升序
向上与向下比较
1.top k问题(优质筛选问题)
什么是top k问题?即求数据结合中前k个最大元素或最小元素,一般情况下数据量较大。
假设N是100万,k是100,求100 万中的前10个最大数,当数足够大,排序已经无法实现了,空间太大,无法内存中开辟,在磁盘上开辟(但磁盘中无法建堆),而且磁盘运行速度很慢。
如:求得大量数字中的前k个大或前k个小的数,普通的算法时间复杂度较高,效率较慢,数量太大,无法寻找。利用堆的特性,算法效率高,面对数量大的数据也适用。
1.用数据集合中前k个元素来建堆。
前k个最大元素 建大堆
前k个最小元素 建小堆

我们这里设置随机数10个,这里你可以改变,越大越能体现堆的功能,找出其中的最大五个,
思路就是先读取五个数进入数组里,之后再从第k+1个数开始与堆顶比较,比堆顶大就替换,每一次都要向下调整,确保是一个小堆,到最后最大的五个数就是小堆的五个数,第一个是五个里最小的。
#include
#include
#include
void Adjustdown1(int* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if ((child + 1 < size) && a[child + 1] < a[child])//若右孩子存在且小于左孩子
{
++child;
}
if (a[child] < a[parent])
{
//交换
int tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void creatnDATA()
{
int n = 10;
srand(time(NULL));
const char* file = "data.txt";
FILE* fp = fopen(file, "w");
if (fp == NULL)
{
perror("fopen fail");
return;
}
for (size_t i = 0; i < n; i++)
{
int x = rand() % 100000;
fprintf(fp, "%d\n", x);
}
fclose(fp);
}
void printtopk(int k)
{
const char* file = "data.txt";
FILE* fp = fopen(file, "r");
if (fp == NULL)
{
perror("fopen fail");
return;
}
int* kminheap = (int*)malloc(sizeof(int) * k);
//从文件中读k个数
for (size_t i = 0; i < k; i++)
{
fscanf(fp, "%d", &kminheap[i]);
}
//建小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown1(kminheap, k, i);
}
int val = 0;
//比较 ,如果比堆顶大,则需要交换,之后再向下调整。
while (!feof(fp))
{
//从第k+1个数处再开始读
fscanf(fp, "%d", &val);
//val用来存放读的数
if (val > kminheap[0])
{
kminheap[0]=val;
Adjustdown1(kminheap, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", kminheap[i]);
}
printf("\n");
}
int main()
{
creatnDATA();
printtopk(5);
return 0;
} 2.堆排序
正常的思维,所谓对堆排序就是用堆这个数据结构来实现排序,思路也很简单,取堆头存入数组,向下调整,在出堆,循环往复。
如下,在有堆的前提,我们可以实现堆排序:
//前提有堆的实现
void heapsort(int *a,int n)
{
HP f;
Heapinit(&f);
for (int i = 0; i < n; i++)
{
Heappush(&f, a[i]);
}
int i = 0;
while (!HeapEmpty(&f))
{
//进行排序
int top = HeapTop(&f);
a[i++] = top;
Heappop(&f);
}
}
int main()
{
int a[] = {10,6,9,3,5,7,65};
heapsort(a,sizeof(a)/sizeof(int));
for (int i=0; i < sizeof(a) / sizeof(int); i++)
{
printf("%d ", a[i]);
}
}但我们也会发现其空间复杂度较高,需要拷贝数据,虽然这个堆排序效率还行,但是我们又看到想要以这种方法实现我们还的需要实现堆的所有操作!!!!这太麻烦了,那这种排序又有谁会用呢?
实则不然,真正的堆排序是利用堆的思路,我们是把传进来这个数组直接建堆,省去一部分操作,提高效率。因此建堆又有两种方式:
1.向上调整建堆
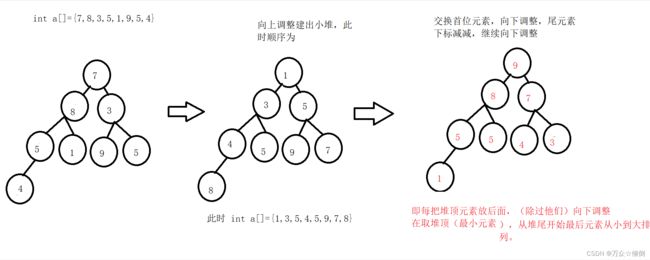
给出排序的数组,以此来建堆,根据堆的结构
建小堆-----最后排序为降序
void Adjustup1(HPDATAtype* a, int child)
{
//根据孩子找父亲
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
HPDATAtype p = a[child];
a[child] = a[parent];
a[parent] = p;
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void Adjustdown1(HPDATAtype* a, int size,int parent)
{
int child =parent * 2 +1;
while (child 0)
{
//把最小的数据交换到最后一个位置
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
Adjustdown1(a, end, 0);
--end;
}
} 建大堆------最后排序为升序

void Adjustup2(HPDATAtype*a, int child)
{
//根据孩子找父亲
int parent = (child - 1) / 2;
while (child>0)
{
if ( a[child]>a[parent])
{
HPDATAtype p = a[child];
a [child] = a[parent];
a[parent]=p;
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void Adjustdown2(HPDATAtype* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if ((child + 1 < size) && a[child + 1] > a[child])//若右孩子存在且小于左孩子
{
++child;
}
if (a[child] > a[parent])
{
//交换
int tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void heapsort2(int* a, int n)
{
//向上调整建堆
//从第一个元素开始就向上调整,保证前面都是堆结构,建大堆
for (int i = 0; i < n; i++)
{
Adjustup2(a, i);
}
//在调整 ,选出一个个次小的数
int end = n - 1;
while (end > 0)
{
//把最小的数据交换到最后一个位置
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
Adjustdown2(a, end, 0);
--end;
}
}利用向上调整算法建堆,时间复杂度O(N*logN),这里是以2为底N的对数。
2.向下调整建堆
建堆与向上调整建堆是相反的,向下调整建堆,从数组后面开始调整,也就是从二叉树后面开始从前调整,知道符合堆的特性。
向下调整建堆也分建大堆还是小堆,根据你设计向下调整算法时,取决于条件-孩子大与父亲还是父亲大于孩子。
这里建小堆,调整数组是下标从中间开始的。
建小堆--排序结果为降序
void Adjustdown1(HPDATAtype* a, int size,int parent)
{
int child =parent * 2 +1;
while (child=0; i--)
{
Adjustdown1(a, n, i);
}
int end = n-1;
while (end>0)
{
//进行排序
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
Adjustdown1(a, end, 0);
--end;
}
} 建大堆---排序结果为升序
void Adjustdown2(HPDATAtype* a, int size, int parent)
{
int child = parent * 2 + 1;
while (child < size)
{
if ((child + 1 < size) && a[child + 1] > a[child])//若右孩子存在且小于左孩子
{
++child;
}
if (a[child] > a[parent])
{
//交换
int tmp = a[child];
a[child] = a[parent];
a[parent] = tmp;
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void heapsort5(int* a, int n)
{
HP f;
Heapinit(&f);
//向下调整建大堆
//与向生调整建堆相反,这里是从数组后面开始调整堆,也就是从二叉树的下面开始
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown2(a, n, i);
}
int end = n - 1;
while (end > 0)
{
//进行排序
int tmp = a[0];
a[0] = a[end];
a[end] = tmp;
Adjustdown2(a, end, 0);
--end;
}
}
向上与向下比较
根据计算我们发现向下调整建堆是优于向上调整建堆的,这里的对于向下调整算法实现复杂度是O(N),向上调整算法的时间复杂度为(N*logN),应为向下调整算法,就如同在数组中插入,而向上调整算法经过错位相减或等比数列法计算大概为N*logN)。