yolo-v4
目录
一:前言
二:一些数据增强的方法
三:自提议
四:dropout
普通的dropout
yolov4的dropblock
五:Label smothing 标签平滑
六: GIOU,DIOU,CIOU
七: 对网络结构的改进
Spp结构
Cspnet
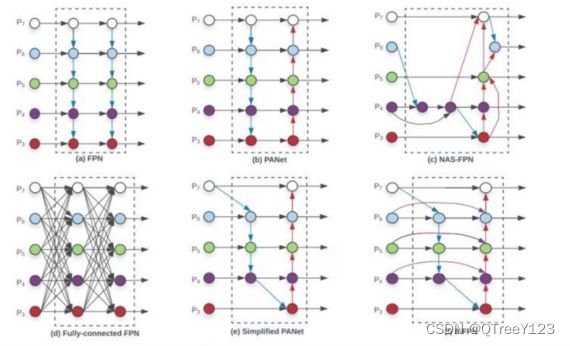
八:PANet
yolov3中的FPN特征金字塔结构
Bi-FPN
九:Mish激活函数(RuLu的改进)
一:前言
YOLOv4是一种目标检测算法,它是YOLO系列(You Only Look Once)的最新版本。YOLO算法是一种实时目标检测算法,能够在一次前向传播过程中同时进行目标检测和定位。YOLOv4在YOLOv3的基础上进行了改进和优化,提高了检测精度和速度。
以下是YOLOv4的一些主要改进和特点:
-
骨干网络改进:YOLOv4使用了更强大的骨干网络,如CSPDarknet53和CSPResNeXt50,以提高特征提取能力和检测性能。
-
特征金字塔网络(FPN):YOLOv4引入了特征金字塔网络,通过多尺度特征融合来处理不同尺度的目标,提高了对小目标的检测能力。
-
PANet:YOLOv4结合了PANet(Path Aggregation Network)的思想,通过横向连接和级联结构来提高不同分辨率特征的信息传递和融合。
-
判别式特征:YOLOv4在网络中引入了判别式特征,使得网络更容易学习到具有判别性的特征,提高了检测的准确性。
-
精细化检测:YOLOv4采用了多尺度训练和测试,以便检测不同尺度的目标,并使用IoU损失函数进行更准确的目标定位。
-
数据增强:YOLOv4使用了更多的数据增强技术,如Mosaic数据增强、CutMix数据增强等,增强了网络的鲁棒性和泛化能力。
-
快速推理:YOLOv4通过优化网络结构、使用精细化的Anchor框和采用更高效的推理策略,提高了检测速度。
V4贡献:
亲民政策,单GPU就能训练的非常好,接下来很多小模块都是这个出发点
两大核心方法,从数据层面和网络设计层面来进行改善
消融实验,感觉能做的都让他给做了,这工作量不轻
全部实验都是单GPU完成,不用太担心设备了

二:一些数据增强的方法

先做数据增加,增强完之后再把四张图片拼接在一起

给网络增加一些游戏难度,加目标的部分部位给遮挡住

三:自提议

四:dropout
普通的dropout
之前的dropout是随机丢弃一些神经元

yolov4的dropblock

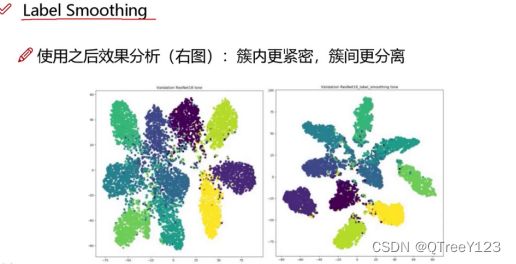
五:Label smothing 标签平滑
将标签数值减小一点点

使用后:簇内更紧密,簇间更分离
六: GIOU,DIOU,CIOU:
可以避免损失为0停止训练。IOU(Intersection over Union)损失属于定位损失(Localization Loss)的一部分。

但是GIOU存在问题。。。。
改进开始使用DIOU(距离度量),使得分母和分子的距离都越近越好,p^2表示欧式距离

但是DIOU还有一点点缺陷,,因为仅仅解决了当两个框完全一样的时候。没有考虑到长宽比。。。
再改进,所以使用CIOU,a长宽比越大,av的值也就越大,iou损失也就越大

soft-MNS是意思是,我先不提除掉,先抑制一点你的这个框,就降低你一点分,然后通过后面你学习,最后看你综合表现,看你能不能学习回来大于我这个阈值,能学习回来就代表你有能力,

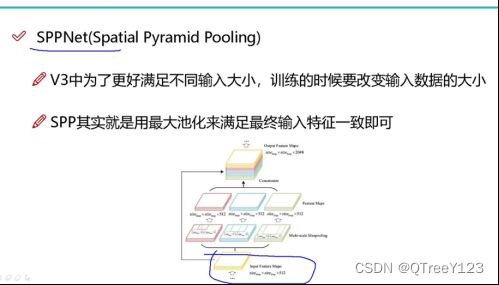
七: 对网络结构的改进
Spp结构
yolov3x出现了spp结构


Cspnet
把channel减小了,大大的减小了计算量,效率更高,很符合yolo的出发点。

注意力机制:分别再channel,位置上,都给不同的特征图分配不一样的权重

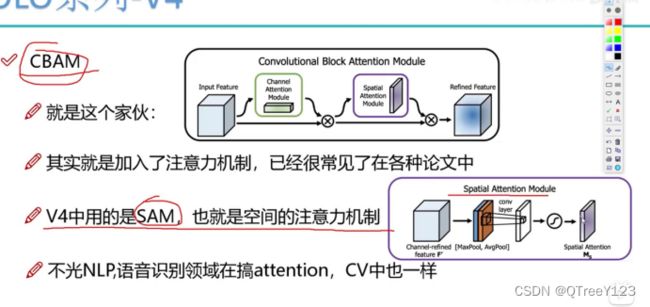
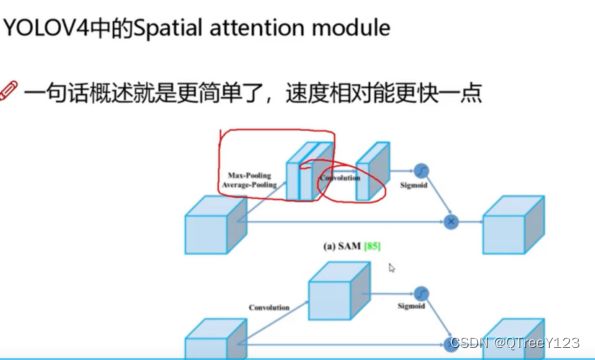
不过引入channel的attention的话会大大增加计算量,所以不用CBAM,而是引入了SAM只有空间的注意力机制。
然后又改进了SAM的一点点,把之前的maxpooling avgpooling变成之间卷积一步到位,主旨都是减小计算量。
八:PANet
YOLOv3中使用的FPN使用自顶向下的路径来提取语义丰富的特征并将其与精确的定位信息结合起来。
但对于为大目标生成mask,这种方法可能会导致路径过于冗长,因为空间信息可能需要传播到数百个层。
PANet是一个加强版的FPN,它通过融合自底向上和自顶向下两条路径的方式增强了骨干网络的表征能力。

不用加法而是用乘法
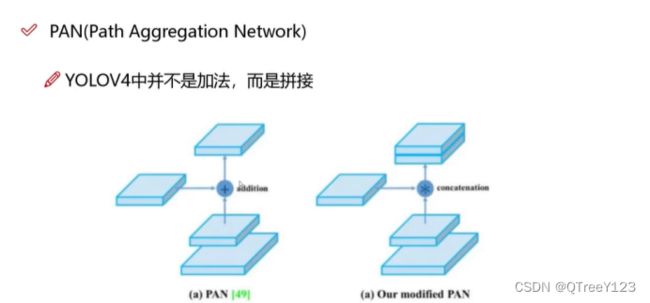

总而言之,YOLOv4中Panet模块使用拼接而不是加法,是为了更好地融合不同层级的特征信息,并提升目标检测的性能。
Panet模块旨在解决多尺度特征的融合问题,它接收来自不同层级的特征图,并将它们进行拼接(concatenate),形成一个更丰富的特征表示。通过拼接而不是加法,可以保留每个层级特征的细节信息,并将它们有机地结合起来。
yolov3中的FPN特征金字塔结构

其对特征点进行不断的下采样后,拥有了一堆具有高语义内容的特征层,然后重新进行上采样,使得特征层的长宽重新变大,用大size的feature map去检测小目标。
然不可以简单只上采样,因为这样上采样的结果对小目标的特征与信息也不明确了,因此我们可以将下采样中,与上采样中长宽相同的特征层进行堆叠,这样可以保证小目标的特征与信息。和U-net结构很相似。但多了堆叠的过程。
Bi-FPN
在EfficientDet中提出了一种加权的双向特征金字塔网络,它允许简单和快速的多尺度特征融合。作者的目的是为了追求更高效的多尺度融合方式。
以往的特征融合是平等地对待不同尺度特征,作者引入了权重(类似于attention),更好地平衡不同尺度的特征信息。在论文中作者也有与其他FPN的对比。
BiFPN(Bi-directional Feature Pyramid Network)使用了一种称为"weighted feature fusion"的操作,它综合了加法和concatenation(cat)的思想。
总的来说 Bi-FPN相当于给各个层赋予了不同权重去进行融合,让网络更加关注重要的层次,而且还减少了一些不必要的层的结点连接。
九:Mish激活函数(RuLu的改进)

消除敏感度

sigmoid函数的作用是将输入映射到0到1之间的概率值,这样做可以对置信度进行归一化,使其表示一个概率的概念。值接近0表示低置信度,值接近1表示高置信度。
这种处理方式有助于模型更好地区分物体和背景,以及判断预测框中是否存在物体。通过应用sigmoid函数,可以使置信度输出符合概率的定义,并更适合用于后续的阈值筛选或目标检测任务的处理。
在 YOLOv3 中,不同尺度的特征图通过拼接(concatenation)的方式合并为一个整体的特征图。然后,通过这个整体特征图计算总体的损失,并进行一次梯度更新来同时更新所有层的参数。 虽然在梯度更新的过程中使用了整体特征图,但每个尺度上的损失是分别计算的。通过拼接后的特征图,不同尺度上的目标检测结果都对总体的损失有贡献,而参数的更新是基于总体损失计算的梯度进行的。因此,可以说是分别更新了不同尺度大小的梯度,以优化整个模型。
参数被更新完梯度后,这些参数保存哪了?
在常见的深度学习框架中(如PyTorch、TensorFlow等),参数的更新是自动完成的,无需手动将更新后的参数传入网络层。优化器(如Adam、SGD等)会自动更新模型的参数,并在后续的训练过程中使用这些更新后的参数。