机器学习在编译器中的应用
原文来自微信公众号“编程语言Lab”:机器学习在编译器中的应用
搜索关注“编程语言Lab”公众号(HW-PLLab)获取更多技术内容!
欢迎加入编程语言社区 参与交流讨论(加入方式:添加文末小助手微信,备注“编程语言社区”)。
作者 | 王焕廷
整理 | Hana
作者简介
王焕廷,英国利兹大学计算机专业博士生,研究方向为编译器优化,漏洞检测。
个人主页 / Github 主页:https://github.com/HuantWang
个人邮箱:[email protected]
近些年来,越来越多的学者和研究人员将目光对准了机器学习技术在编译器领域的应用。在本文里,我们将阐述机器学习和编译器优化之间的关系,并介绍其中的一些典型应用。
编译器 & 机器学习
对于 编译器 本身,我们可以将其理解成一个翻译器程序,一个将 “一种语言(通常为高级编程语言,如 C 语言)” 翻译为 “另一种语言(通常为低级语言,如可执行的汇编指令)” 的程序。关于编译器的作用,可以归纳为代码翻译和性能优化两部分。首先,它们必须正确地将程序翻译为可执行的二进制文件;其次,它们必须找到最有效(执行速度最快或代码量最小)的汇编指令。
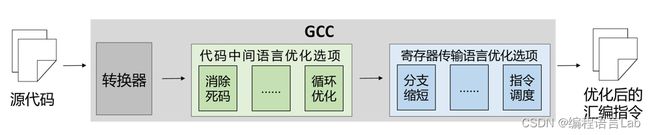
传统编译器 GCC 的翻译优化过程如下图所示,源代码被传入编译器中,经过转换器进行从高级语言到低级语言的优化,再经过编译器中对不同级别语言的优化选项进行优化,最终得到优化后的汇编指令。当前,绝大多数针对编译器的研究工作和工程实践都集中在 性能优化 这一目标上 1。
而 机器学习 技术,近些年来已经被广泛应用于生活中的不同领域:如自然语言处理、自动驾驶、图像处理等。机器学习技术旨在基于已知(或先验)的数据对未知的数据样本结果进行预测。如果能合理地使用机器学习算法构筑对应的模型去寻找最有效的汇编指令,那无疑将大大减少编译器优化工程师的压力。
基于机器学习的编译技术,本质上在解决 “最优化” 的问题,更通俗地讲,它试图将优化问题转换成预测问题并加以解决。一般来说,开发人员将编译器领域的代码优化问题转换为机器学习中的预测问题,并将基于机器学习构筑的模型作为最优代码的预测器,从而对代码优化结果进行预测。
编译器发展过程中的 “变”vs“不变”
基于机器学习的编译器优化技术作为一个研究领域,一直受到研究人员的广泛关注。然而,相比于机器学习技术在传统的图像、自然语言处理领域中的大放异彩,它在编译器领域的应用却一直无法得到广泛应用。我们发现,传统的编译器优化模块仍然依赖于几十年前的架构,基于机器学习的优化模块并未在编译器领域得到充分体现。
因此,一个值得我们思考的问题是,为什么会出现这样的情况呢?是传统的编译优化方式已经足够好,所以编译器开发人员不需要对已有方法进行改进了吗?
事实并非如此,目前主流的编译器架构已经被研究了很多年,其架构本身却一直没有任何变化。这套 “过时” 的架构在设计之初,计算机的发展还受限于硬件算力(如过小的内存)、低效的算法和闭塞的编译器社区环境。上述种种限制导致传统的编译优化方法在诸如循环优化等问题上还是存在优化效果不如人意的现象。
随着时代的发展,在最近几十年里,编译器的开发环境已经有了巨大的、令人欣喜的变化。
首先,编译器开发设备具备更高的算力,这得益于计算设备拥有更大的内存以及多核 CPU 和高性能 GPU 的诞生。当然,更多的经费投入也变相提高了编译器开发设备的质量。下图展示了随着时间的迁移,计算机算力提升趋势的 “摩尔定律”——大约每 18 个月,芯片的性能将会提高一倍 2。
其次,更快的算法和神经网络的出现让计算机自动化地学习编译器的优化模式成为可能。
最后,大数据时代中类似于 Github 的开源仓库以及全球化的数据交流平台,赋予了从海量数据中挖掘优化模式的可能性。
如此,机器学习在编译器开发中自动优化代码,而不再依赖于编译器开发专家,这种自动调优的工作模式出现在我们眼前。它可以用于选择最佳编译器优化策略,也可以确定一段代码应该在 CPU 还是在 GPU 上运行。
那么,当我们注意到这些令人欣喜的变化后,应该如何利用这些技术来帮助我们完成多年未发生本质变化的编译器优化领域的革新呢?
算力,算法,数据
前文中提到,随着时代的发展,支撑我们将机器学习技术应用到编译器优化的可能支柱有以下三个:更高的算力,更优的算法,更庞大的数据。所以,我们接下来要思考的问题是,当下,我们如何利用这些技术,带动编译器优化的变革?
用尽每一分算力
编译器优化问题的本质可以归纳为 一个庞大的搜索空间下的搜索问题。可选择的编译器指令构成的搜索空间大小(可选择的编译器指令搭配数目),远远超过了可观测宇宙中原子的数量。在编译器优化的实际使用中,往往还存在很多其他的问题,如设备相关性:同样的程序在进行编译优化时,往往会由于底层平台的不同,采取不同的优化策略,这大大增加了编译优化的工程量和复杂度。因此,编译器开发人员则更多地关注自动化编译框架的实现。这一框架应满足:无关于底层架构;适配不同的编译器;能根据不同的编译器对搜索空间进行快速搜索。
下图是一个自动化的编译优化框架的工作流程。当一个程序被输入给编译器后,由编译器编译为一个可执行的二进制文件,文件再被传递给底层硬件。这时,底层硬件的执行结果(执行时间)被传递给搜索算法,搜索算法通过执行结果的反馈对编译优化选项进行调整,从而指导编译器的优化策略。如此反复,最后得到最优的优化代码。
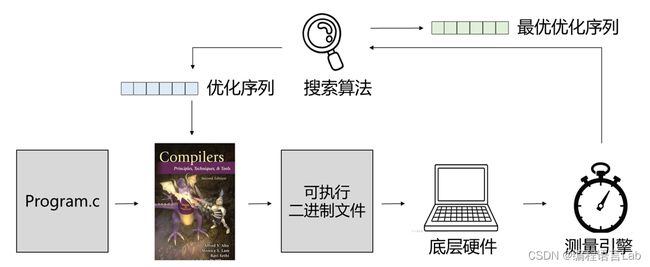
但是,尽管全自动化的优化框架可以很大程度上利用目前的算力优势,而优化一个程序可能仍然需要高达数小时的时间来进行搜索。那么,在算力之外,我们还有什么技术可以利用吗?
深度神经网络算法——编译优化的策马鞭
往复的搜索往往需要很长的时间来编译运行,根据以往的研究结果,即便耗费数个小时,可能依旧无法搜索出一个令人满意的程序片段的优化结果。进而,我们思考是否强大的算法能够帮助我们对编译优化的搜索过程进行加速,甚至直接跳过这一繁琐的迭代过程呢?监督学习技术和神经网络算法 便映入了我们的眼帘。
下图给出了一个关于机器学习如何应用于编译器的直观视图。

这个过程包括 特征工程、模型训练 和 实际部署:
- 特征工程:首先,编译器开发人员需要对不同的程序进行特征工程建模,特征用以描述不同程序片段的属性或特性,如代码块的数量,分支数量和指令数量等静态结构特征或行时分析获得的动态分析信息(例如性能计数器值)。
- 模型训练:然后训练集中的程序会被提取特征,这些特征再输入给机器学习算法进行建模和预测模式的学习。
- 实际部署:最后,模型会被部署在编译器中,这时,只需要对新的项目中的新的代码块进行同样的特征提取,并将特征输入给模型,模型就会立刻给出最佳的优化预测。
监督学习技术已经被科研人员广泛应用于编译器优化的工作中。无论是对程序究竟是应该在 CPU 运行还是在 GPU 运行进行预测 3,还是是对循环展开的次数进行预测 4,深度神经网络都在其中发挥了很好的作用。
同时,新的问题也随着神经网络模型的广泛使用应运而生:一个机器学习模型学习到的预测模式,往往受限制于它所学习的数据集。所以,如何 获取更贴合现实世界中数据分布的训练集,来帮助我们训练出更贴合实际环境的模型,也是开发人员正在关注的问题。
数据挖掘

一个鲁棒的机器学习模型,往往需要数亿行代码数据集的支撑。而随着互联的发展,编译器的开发人员在进行数据建模时,可以不仅仅局限于标准的、人为构造的数据集。构造机器学习模型并让它学习现实生活中真实的程序员的代码风格,藉此挖掘相对真实的代码结构,是开发人员所一直憧憬的。然而,将这个想法转化为一个实用的数据收集系统并非易事。但如果,编译器开发人员能获知真实环境下的代码分布,从而构建出能够生成无限多的真实代码的系统,就能利用这些生成的数据对特征选择或者模型选择进行改进了。
已有的工作中 5,科研人员使用神经网络,学习生成可运行程序。该神经网络从大量程序片段中对语义和语法中进行建模,生成有代表性但不同于它所学习的程序的多核 OpenCL 程序。在使用这些生成的 OpenCL 程序对基于学习的程序优化工作进行改进后,模型的优化效果均有明显的提升,这是更贴近现实世界数据分布的训练集对编译器优化模型的帮助。
打通最后一层障碍 —— SUPERSONIC
机器学习固然是一种强大的技术,已经肉眼可见地影响着我们的世界,并且在编译器领域有了初步的应用。然而,它和编译器开发人员之间,仍然存在着一个巨大的技术壁垒:现在的机器学习应用中,往往需要编译器专家通过他们的先验知识,手动选择并调整特定于他们编译器优化任务的机器学习架构。对于普通开发人员来说,很难有效地将需要解决的编译器优化问题正确地进行机器学习建模。
下图举例说明了机器学习失效的常见原因,当机器学习模型学习到的知识与优化目标不相关时,数据的特征空间呈离散分布,很难进行准确的分类;而对特征的归纳不完全,也会导致程序在建模后的特征发生丢失,从而影响模型的有效性。此外,对于神经网络架构的错误组合或者对数据分布的错误归纳,也会导致模型的失效。综上,想要将机器学习应用于特定的编译器任务中,还有着巨大的技术壁垒

现在,从事编译器优化的研究人员针对上述问题已经进行了一系列探索,比如一些工作提供了封装好的机器学习算法接口,来帮助没有机器学习算法经验的开发人员调用算法到他们的优化工作中 67。此外,全自动的进行程序特征建模和机器学习架构组合也是科研人员所关注的领域。
最新的工作 SUPERSONIC 8 是一个开源框架,它帮助编译器开发人员将机器学习技术应用于他们领域的任务中,并且不要求编译器开发人员掌握机器学习相关的专业知识。其核心是使用深度强化学习技术和多任务学习技术相结合,来开发一个机器学习架构搜索框架,便于帮助开发人员从庞大的架构搜索空间中自动找到和调优正确的机器学习架构,然后直接部署到优化任务中来帮助开发人员进行程序优化。
相关论文已于 2022 年发表在编译器领域顶级会议 Compiler Construction(CC’22),更多请访问:
Github 地址:https://github.com/HuantWang/SUPERSONIC
论文地址:https://dl.acm.org/doi/10.1145/3497776.3517769
PPT 地址:https://github.com/HuantWang/SUPERSONIC/blob/master/docs/Supersonic.pdf
下图展示了 SUPERSONIC 搜索架构的系统框架。SUPERSONIC 提供了 Python API,用户仅仅需要修改数行代码,就能够清晰地定义自己的搜索问题,然后框架则会自动组合可选的机器学习组件进行尝试。最后,调优后的机器学习架构可以通过预测的方式,来优化新的,与训练集中分布不同的程序。

该框架帮助开发人员描述和定义优化空间,并自动搜索适合于当前任务的机器学习架构。开发人员只需要在 Python API 中修改几行代码中即可将机器学习技术应用到自己的优化任务中。
这项工作中,研究人员为了证明框架的通用性和实用性,分别在四种不同的编译器优化问题上,和不同的硬件设备上进行了机器学习架构搜索。
下图的试验结果表明,SUPERSONIC 均能够取得优于已有基线工作的整体性能,甚至超越专家手动调优的结果。使用该框架建议的机器学习架构进行优化,从优化程序需要的时间来看,平均能够提高 1.75 倍的部署时间(最快可达 100 倍)。

总结
毫无疑问,基于机器学习的编译优化现在是一个主流的编译器研究领域。在过去的十年左右的时间里,已经产生了大量的学术研究和相关论文,他们着眼当前编译器开发大环境下不断更新的算力,算法和数据,投身于将机器学习应用于编译器优化的发展进程中。
Reference
Wang Z, O’Boyle M. Machine learning in compiler optimization[J]. Proceedings of the IEEE, 2018, 106(11): 1879-1901. ↩︎
Visualizing Moore’s Law with React & D3. https://reactfordataviz.com/articles/moores-law/ ↩︎
Cummins C, Petoumenos P, Wang Z, et al. End-to-end deep learning of optimization heuristics[C]//2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, 2017: 219-232. ↩︎
Ye G, Tang Z, Wang H, et al. Deep program structure modeling through multi-relational graph-based learning[C]//Proceedings of the ACM international conference on parallel architectures and compilation techniques. 2020: 111-123. ↩︎
Cummins C, Petoumenos P, Wang Z, et al. Synthesizing benchmarks for predictive modeling[C]//2017 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2017: 86-99. ↩︎
Cummins C, Wasti B, Guo J, et al. CompilerGym: robust, performant compiler optimization environments for AI research[C]//2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2022: 92-105. ↩︎
Liang E, Liaw R, Nishihara R, et al. RLlib: Abstractions for distributed reinforcement learning[C]//International Conference on Machine Learning. PMLR, 2018: 3053-3062. ↩︎
Wang H, Tang Z, Zhang C, et al. Automating reinforcement learning architecture design for code optimization[C]//Proceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction. 2022: 129-143. ↩︎