pytorch相关报错【报错】
AttributeError: cannot assign module before Module.init() call
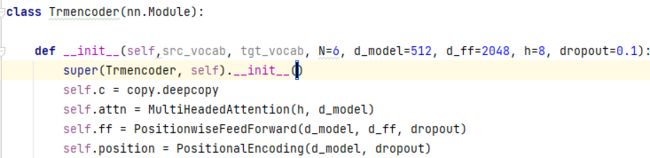
- 原因:自定义类中缺少
supre()函数

- 解决
KeyError: tensor(1)
报错原因:tensor不能作为字典的键
解决:转化为numpy
x = torch.tensor([1,2,3])
y = {1:'1',2:'2',3:'3'}
z = [y[i] for i in x.numpy()]
CUDA out of memory.
- 背景:使用clip处理数据,想要得到50w个句子的clip特征,每个句子是单独处理的。处理到300多的时候出现cuda out of memory错误。理论上不应该呀。
- 解决:
1)是否有没有杀干净的进程
2)batch size过大,调小
3)及时清理缓存,在报错的位置/新一轮epoch开始的时候
import torch, gc
gc.collect()
torch.cuda.empty_cache()
4 ) 验证的时候去掉梯度计算
def test(model,dataloader):
model.eval()
with torch.no_grad(): ###插在此处
for batch in tqdm(dataloader):
……
5 ) dataloader中的pin_memory设置为false
参考链接:pytorch cuda out of memory的四种解决方案
RuntimeError: CUDA error: initialization error
- 定位
def train_collate_fn(data):
data.sort(key=lambda x: x[-1], reverse=True)
# videos, regions, spatials, captions, pos_tags, lengths, video_ids = zip(*data)
videos, text_feature, captions, svb, mlm_input, mlm_cap, length, video_id = zip(*data)
print(f'video:{videos[0].device}, text:{text_feature[0].device}, mlm:{mlm_cap[0].device}, cap:{captions[0].device}')
videos = torch.stack(videos, 0)
# regions = torch.stack(regions, 0)
# spatials =torch.stack(spatials, 0)
text_feature = torch.stack(text_feature, 0) # 这一行报错
captions = torch.stack(captions, 0)
svb = torch.stack(svb, 0)
mlm_input = torch.stack(mlm_input, 0)
mlm_cap = torch.stack(mlm_cap, 0)
# pos_tags = torch.stack(pos_tags, 0)
# return videos, regions, spatials, captions, pos_tags, lengths, video_ids
print(videos[0].dtype)
return videos,text_feature, captions, svb, mlm_input, mlm_cap, length, video_id
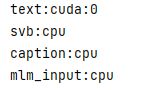
- 原因:在text_feature传入dataloader之前就已经在GPU上,导致初始化失败。因为这里的text_feature是使用clip模型得到的文本特征,模型和数据在gpu上,得到的结果也在gpu上,将其写入pkl文件之后读出没想到device还是gpu。
- 解决:在数据放入dataloader之前,device应该是cpu。将数据使用
.cpu()转换到cpu上 - 参考资料:
RuntimeError: CUDA error: initialization error
【Pytorch】RuntimeError: CUDA error: initialization error