回归预测 | MATLAB实现SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
回归预测 | MATLAB实现SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
目录
-
- 回归预测 | MATLAB实现SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
-
- 效果一览
- 基本介绍
- 模型描述
- 程序设计
- 参考资料
效果一览
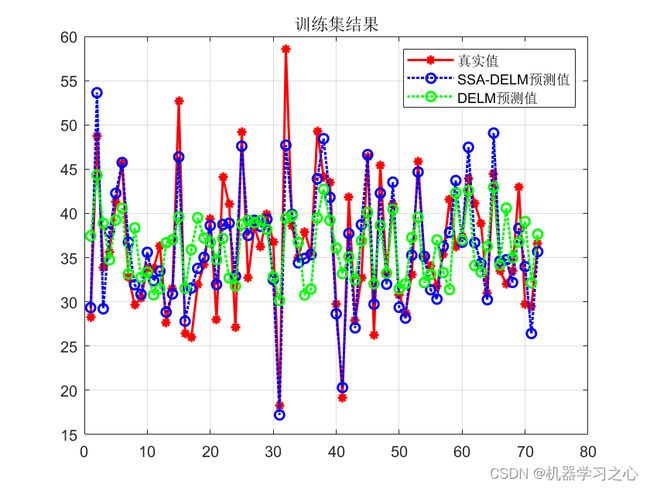
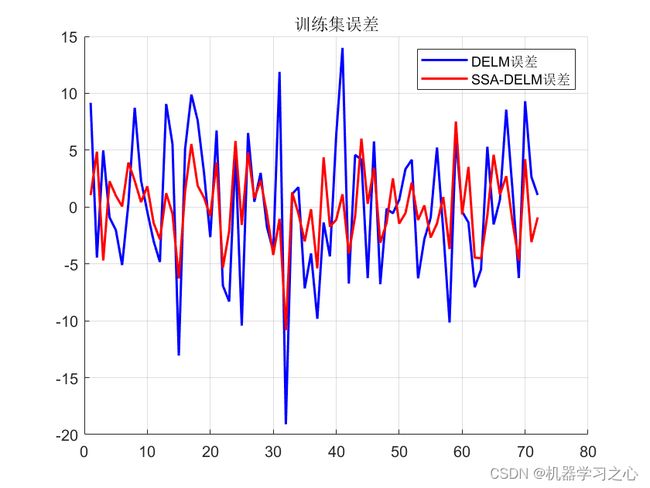
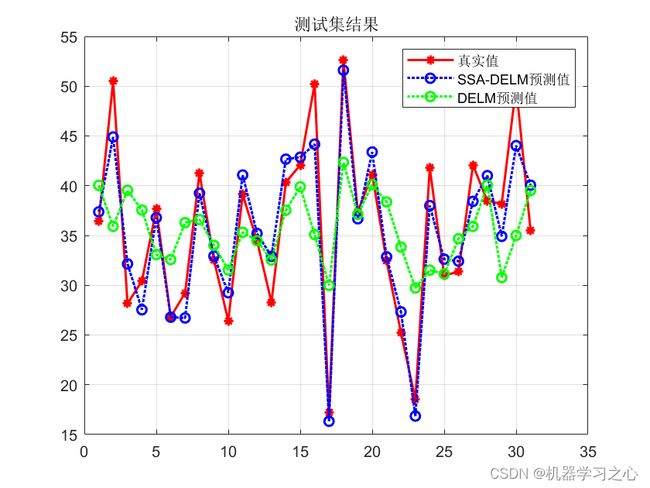
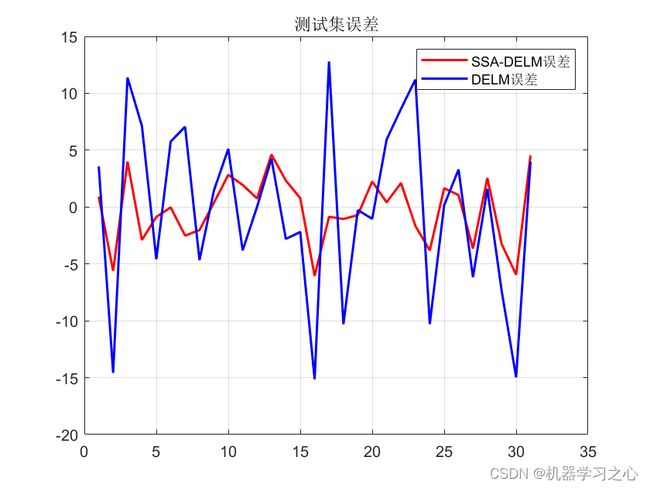

基本介绍
Matlab实现SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
1.输入多个特征,输出单个变量;
2.SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
3.含优化前后对比图
4.优化前后MSE对比:
DELM训练集MSE:39.1837
DELM测试集MSE:57.8267
SSA_DELM训练集MSE:10.9448
SSA_DELM测试集MSE:8.5069
模型描述
- SSA-DELM麻雀算法是一种基于麻雀搜索算法和深度极限学习机(DELM)的优化算法,用于多输入单输出回归预测问题的优化。
深度极限学习机是一种深度神经网络结构,通过堆叠多个隐层,可以学习到更高层次的抽象特征表示,从而提高模型的预测准确性。然而,深度极限学习机的训练需要大量的计算资源和时间,因此需要一种高效的优化算法来加速训练过程。- SSA-DELM麻雀算法是基于麻雀搜索算法的一种新型优化算法,通过模拟麻雀在搜索食物和避免危险的过程中的行为,来搜索最优解。在SSA-DELM麻雀算法中,麻雀代表一组待优化的参数,而食物和危险则代表解空间中的最优解和局部最优解。算法通过不断迭代,不断更新麻雀的位置和速度,直到找到全局最优解或者达到最大迭代次数为止。
- 在多输入单输出回归预测问题中,SSA-DELM麻雀算法可以用来优化深度极限学习机的权重和偏置参数,以最小化预测误差。具体地,算法通过将输入数据经过多个隐层的非线性变换,得到高层次的抽象特征表示,然后将这些特征输入到输出层进行回归预测。在每次迭代中,算法根据当前麻雀的位置和速度,更新神经网络的参数,以逐步优化模型的预测准确性。
- 总的来说,SSA-DELM麻雀算法是一种有效的优化算法,可以用于优化深度极限学习机模型在多输入单输出回归预测问题中的性能。
- SSA-DELM麻雀算法优化深度极限学习机多输入单输出回归预测的具体公式如下:
- 麻雀位置和速度更新公式
- 麻雀的位置和速度可以通过以下公式进行更新:
v i j ( t + 1 ) = w ⋅ v i j ( t ) + c 1 ⋅ r 1 j ⋅ ( p b e s t , i j − x i j ( t ) ) + c 2 ⋅ r 2 j ⋅ ( g b e s t , j − x i j ( t ) ) v_{ij}(t+1)=w \cdot v_{ij}(t)+c_1 \cdot r_{1j} \cdot (p_{best,ij}-x_{ij}(t))+c_2 \cdot r_{2j} \cdot (g_{best,j}-x_{ij}(t)) vij(t+1)=w⋅vij(t)+c1⋅r1j⋅(pbest,ij−xij(t))+c2⋅r2j⋅(gbest,j−xij(t))
x i j ( t + 1 ) = x i j ( t ) + v i j ( t + 1 ) x_{ij}(t+1)=x_{ij}(t)+v_{ij}(t+1) xij(t+1)=xij(t)+vij(t+1)
- 其中, v i j ( t ) v_{ij}(t) vij(t)是第 j j j个隐层第 i i i个神经元在时间 t t t的速度, x i j ( t ) x_{ij}(t) xij(t)是第 j j j个隐层第 i i i个神经元在时间 t t t的位置。 p b e s t , i j p_{best,ij} pbest,ij是第 j j j个隐层第 i i i个神经元历史上访问过的最优位置, g b e s t , j g_{best,j} gbest,j是所有隐层第 j j j个神经元历史上访问过的最优位置。 w w w是惯性权重, c 1 c_1 c1和 c 2 c_2 c2是两个常数, r 1 j r_{1j} r1j和 r 2 j r_{2j} r2j是两个随机数。
- 深度极限学习机模型预测公式
- 深度极限学习机模型的预测公式如下:
y = ∑ i = 1 n 2 w i ⋅ h i + b y=\sum_{i=1}^{n_2} w_i \cdot h_i+b y=i=1∑n2wi⋅hi+b
- 其中, y y y是模型的输出, n 2 n_2 n2是输出层的神经元个数, w i w_i wi是输出层第 i i i个神经元的权重, h i h_i hi是第 i i i个神经元的输出, b b b是偏置项。
h i h_i hi的计算公式如下:
h i = g ( ∑ j = 1 n 1 w i j ⋅ x j + b i ) h_i=g(\sum_{j=1}^{n_1} w_{ij} \cdot x_j+b_i) hi=g(j=1∑n1wij⋅xj+bi)
- 其中, n 1 n_1 n1是输入层的神经元个数, x j x_j xj是输入层第 j j j个神经元的输出, w i j w_{ij} wij是连接输入层第 j j j个神经元和隐层第 i i i个神元的权重, b i b_i bi是隐层第 i i i个神经元的偏置项, g ( ⋅ ) g(\cdot) g(⋅)是激活函数。
- 优化目标函数公式
- SSA-DELM麻雀算法的优化目标函数是MSE,可以表示为:
M S E = 1 n ∑ i = 1 n ( y i − y i ^ ) 2 MSE=\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y_i})^2 MSE=n1i=1∑n(yi−yi^)2
-
其中, n n n是样本数, y i y_i yi是第 i i i个样本的真实值, y i ^ \hat{y_i} yi^是对第 i i i个样本的预测值。
-
MSE是所有预测误差平方的平均值,因此它的值越小,表示预测结果与真实值之间的差异越小,预测效果越好。MSE的单位与预测值的单位平方相同。
- 模型参数优化公式
- 模型参数优化可以通过以下公式进行:
w i j ( t + 1 ) = x i j ( t + 1 ) w_{ij}(t+1)=x_{ij}(t+1) wij(t+1)=xij(t+1)
b i ( t + 1 ) = x i ( t + 1 ) b_{i}(t+1)=x_{i}(t+1) bi(t+1)=xi(t+1)
-
其中, w i j ( t ) w_{ij}(t) wij(t)和 b i ( t ) b_{i}(t) bi(t)是第 i i i个隐层第 j j j个神经元在时间 t t t的权重和偏置项, x i j ( t + 1 ) x_{ij}(t+1) xij(t+1)和 x i ( t + 1 ) x_{i}(t+1) xi(t+1)是第 i i i个隐层第 j j j个神经元在时间 t + 1 t+1 t+1的位置和第 i i i个隐层在时间 t + 1 t+1 t+1的位置,即经过更新后的最优位置。
-
在每次迭代中,通过不断更新麻雀的位置和速度,计算出对应的深度极限学习机模型的权重和偏置项,然后用这些参数进行预测,并计算出对应的平方误差损失函数。最终,通过不断迭代更新麻雀的位置和速度,使得平方误差损失函数逐步减小,直到达到最小值,从而得到最优的深度极限学习机模型参数。
程序设计
- 完整程序和数据获取方式1:私信博主,同等价值程序兑换;
- 完整程序和数据下载方式2(资源处直接下载):Matlab实现SSA-DELM和DELM麻雀算法优化深度极限学习机多输入单输出回归预测对比
%_________________________________________________________________________%
% 麻雀优化算法 %
%_________________________________________________________________________%
function [Best_pos,Best_score,curve]=SSA(pop,Max_iter,lb,ub,dim,fobj)
ST = 0.6;%预警值
PD = 0.7;%发现者的比列,剩下的是加入者
SD = 0.2;%意识到有危险麻雀的比重
PDNumber = round(pop*PD); %发现者数量
SDNumber = round(pop*SD);%意识到有危险麻雀数量
if(max(size(ub)) == 1)
ub = ub.*ones(1,dim);
lb = lb.*ones(1,dim);
end
%种群初始化
X0=initialization(pop,dim,ub,lb);
X = X0;
%计算初始适应度值
fitness = zeros(1,pop);
for i = 1:pop
fitness(i) = fobj(X(i,:));
end
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
GBestF = fitness(1);%全局最优适应度值
for i = 1:pop
X(i,:) = X0(index(i),:);
end
curve=zeros(1,Max_iter);
GBestX = X(1,:);%全局最优位置
X_new = X;
for i = 1: Max_iter
disp(['第',num2str(i),'次迭代'])
BestF = fitness(1);
WorstF = fitness(end);
R2 = rand(1);
for j = 1:PDNumber
if(R2<ST)
X_new(j,:) = X(j,:).*exp(-j/(rand(1)*Max_iter));
else
X_new(j,:) = X(j,:) + randn()*ones(1,dim);
end
end
for j = PDNumber+1:pop
% if(j>(pop/2))
if(j>(pop - PDNumber)/2 + PDNumber)
X_new(j,:)= randn().*exp((X(end,:) - X(j,:))/j^2);
else
%产生-1,1的随机数
A = ones(1,dim);
for a = 1:dim
if(rand()>0.5)
A(a) = -1;
end
end
AA = A'*inv(A*A');
X_new(j,:)= X(1,:) + abs(X(j,:) - X(1,:)).*AA';
end
end
Temp = randperm(pop);
SDchooseIndex = Temp(1:SDNumber);
for j = 1:SDNumber
if(fitness(SDchooseIndex(j))>BestF)
X_new(SDchooseIndex(j),:) = X(1,:) + randn().*abs(X(SDchooseIndex(j),:) - X(1,:));
elseif(fitness(SDchooseIndex(j))== BestF)
K = 2*rand() -1;
X_new(SDchooseIndex(j),:) = X(SDchooseIndex(j),:) + K.*(abs( X(SDchooseIndex(j),:) - X(end,:))./(fitness(SDchooseIndex(j)) - fitness(end) + 10^-8));
end
end
%边界控制
for j = 1:pop
for a = 1: dim
if(X_new(j,a)>ub)
X_new(j,a) =ub(a);
end
if(X_new(j,a)<lb)
X_new(j,a) =lb(a);
end
end
end
%更新位置
for j=1:pop
fitness_new(j) = fobj(X_new(j,:));
end
for j = 1:pop
if(fitness_new(j) < GBestF)
GBestF = fitness_new(j);
GBestX = X_new(j,:);
end
end
X = X_new;
fitness = fitness_new;
%排序更新
[fitness, index]= sort(fitness);%排序
BestF = fitness(1);
WorstF = fitness(end);
for j = 1:pop
X(j,:) = X(index(j),:);
end
curve(i) = GBestF;
end
Best_pos =GBestX;
Best_score = curve(end);
end
function OutWeight = DELMTrainWithInitial(InputWietht,P_train,T_train,ELMAEhiddenLayer,ActivF,C)
hiddenLayerSize = length(ELMAEhiddenLayer); %获取ELM-AE的层数
outWieght = {};%用于存放所有的权重
P_trainOrg = P_train;
count = 1;
%% ELM-AE提取数据特征
for i = 1:hiddenLayerSize
Num = ELMAEhiddenLayer(i)*size(P_train,2);
InputW = InputWietht(count:count+Num-1);
count = count+Num;
InputW = reshape(InputW,[ELMAEhiddenLayer(i),size(P_train,2)]);
[~,B,Hnew] = ELM_AEWithInitial(InputW,P_train,ActivF,ELMAEhiddenLayer(i)); %获取权重
OutWeight{i} = B';
P_train =P_train*B'; %输入经过第一层后传递给下一层
end
%% 最后一层ELM进行监督训练
P = P_train;
N =size(P,2);
I = eye(N);
beta = pinv((P'*P+I/C))*P'*T_train;
OutWeight{hiddenLayerSize + 1} = beta; %存储最后一层ELM的信息。
end
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/127931217
[2] https://blog.csdn.net/kjm13182345320/article/details/127418340