GhostNet(CVPR 2020) 原理与代码解析
论文 https://arxiv.org/abs/1911.11907v2
目录
Ghost Module
Ghost Bottleneck
GhostNet
作者发现特征图中存在冗余的情况

如图所示,同色的两个特征图之间存在很强的线性关系,可以通过一些成本较低的操作得到。
Ghost Module
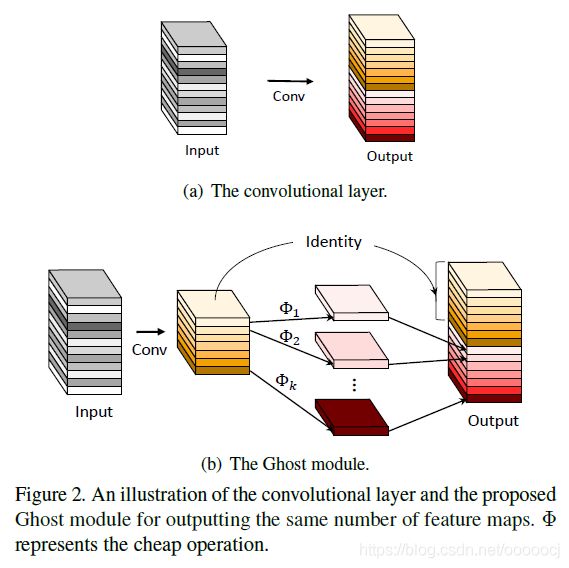
作者提出了Ghost module,具体做法是,通过常规卷积生成部分特征图,论文中将这部分特征图称为intrinsic feature maps。然后对这些intrinsic特征图进行简单的线性变换生成ghost feature maps,然后将两者进行concat保持最终的输出通道数不变。
Ghostmodule的代码如下
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, :self.oup, :, :]其中,ratio是intrinsic特征图和ghost特征图通道数的比例,一般设为2,即各占总输出通道数的1/2。primary_conv是常规卷积用来生成intrinsic特征图,cheap_operation是深度卷积用来生成ghost特征图,然后将两者进行concat得到最终输出。
常规卷积转换成ghost module后计算量的比值如下

其中,h'×w'×c是输入特征图的尺寸,k是常规卷积大小,n是输出特征图通道数。s是ghost module中常规卷积的占比即上面代码中的ratio,d是线性变换即深度卷积的大小。另外,d≈k,一般为3或5。s![]() c,一般s=2,c可能为512、1024甚至更大。因此最终计算量的压缩比大约就是s,即减少了1/2。
c,一般s=2,c可能为512、1024甚至更大。因此最终计算量的压缩比大约就是s,即减少了1/2。
Ghost Bottleneck
作者以ghost module为基础,构建了Ghost bottleneck
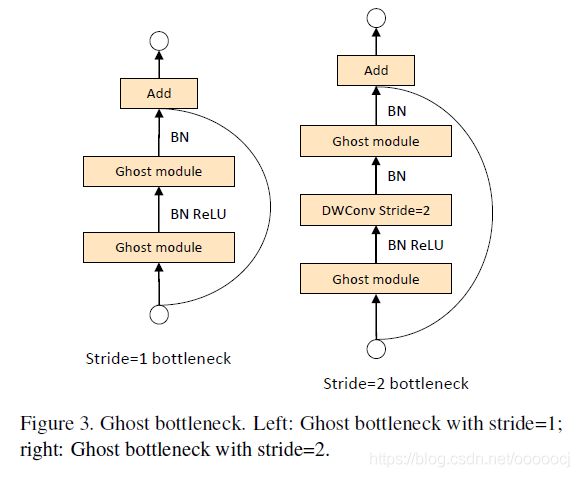
代码如下
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size - 1) // 2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size - 1) // 2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x其中一些具体实现的细节如下,只有第一个Ghost module后有ReLU函数;使用se时,se是在第一个Ghost module或者stride=2的深度卷积后,se中降维比例se_ratio=0.25;stride=2时,shortcut依次经过stride=2的深度卷积、BN、1×1卷积、BN,然后再进行Add。
GhostNet
最后通过堆叠Ghost bottleneck,作者提出了GhostNet,其结构如下
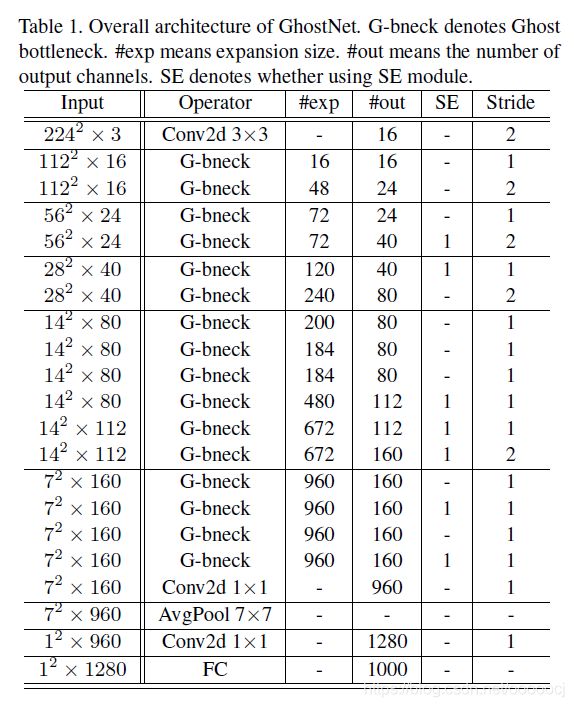
需要注意到是,具体实现中卷积核的大小
cfgs = [
# k, t, c, SE, s
[3, 16, 16, 0, 1],
[3, 48, 24, 0, 2],
[3, 72, 24, 0, 1],
[5, 72, 40, 1, 2],
[5, 120, 40, 1, 1],
[3, 240, 80, 0, 2],
[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 1, 1],
[3, 672, 112, 1, 1],
[5, 672, 160, 1, 2],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 1, 1]
]