Nginx【反向代理负载均衡动静分离】--下
Nginx【反向代理负载均衡动静分离】–下
Nginx 工作机制&参数设置
master-worker 机制
示意图
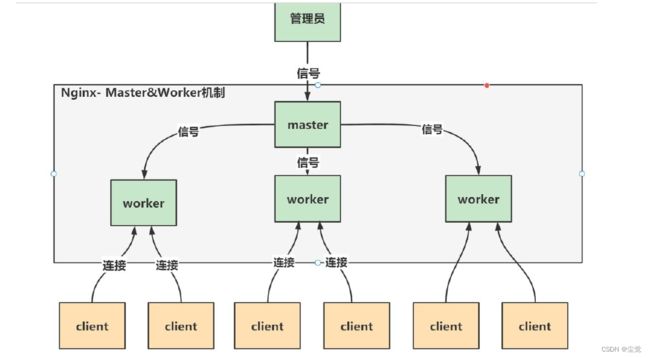
图解
- 一个master 管理多个worker

一说master-worker 机制
● 争抢机制示意图

图解
- 一个master Process 管理多个worker process, 也就是说Nginx 采用的是多进程结构, 而不是多线程结构.
- 当client 发出请求(任务)时,master Process 会通知管理的worker process
- worker process 开始争抢任务, 争抢到的worker process 会开启连接,完成任务
- 每个worker 都是一个独立的进程,每个进程里只有一个主线程
- Nginx 采用了IO 多路复用机制(需要在Linux 环境), 使用IO 多路复用机制, 是Nginx 在使用为数不多的worker process 就可以实现高并发的关键
二说master-worker 机制
示意图

对上图说明
● Master-Worker 模式
1、Nginx 在启动后,会有一个master 进程和多个相互独立的worker 进程。
2、Master 进程接收来自外界的信号,向各worker 进程发送信号,每个进程都有可能来处理这个连接。
3、Master 进程能监控Worker 进程的运行状态,当worker 进程退出后(异常情况下),会自动启动新的worker 进程。
● accept_mutex 解决"惊群现象"/理论
1、所有子进程都继承了父进程的sockfd,当连接进来时,所有子进程都将收到通知并“争着”与它建立连接,这就叫“惊群现象”。
2、大量的进程被激活又挂起,只有一个进程可以accept() 到这个连接,会消耗系统资源。
3、Nginx 提供了一个accept_mutex ,这是一个加在accept 上的一把共享锁。即每个worker 进程在执行accept 之前都需要先获取锁,获取不到就放弃执行accept()。有了这把锁之后,同一时刻,就只会有一个进程去accpet(),就不会有惊群问题了。
4、当一个worker 进程在accept() 这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,完成一个完整的请求。
5、一个请求,完全由worker 进程来处理,而且只能在一个worker 进程中处理。
● 用多进程结构而不用多线程结构的好处/理论
1、节省锁带来的开销, 每个worker 进程都是独立的进程,不共享资源,不需要加锁。在编程以及问题查上时,也会方便很多。
2、独立进程,减少风险。采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master 进程则很快重新启动新的worker 进程
● 实现高并发的秘密-IO 多路复用
1、对于Nginx 来讲,一个进程只有一个主线程,那么它是怎么实现高并发的呢?
2、采用了IO 多路复用的原理,通过异步非阻塞的事件处理机制,epoll 模型,实现了轻量级和高并发
3、nginx 是如何具体实现的呢,举例来说:每进来一个request,会有一个worker 进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker 不会这么傻等着,他会在发送完请求后,注册一个事件:“如果upstream 返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker 才会来接手,这个request 才会接着往下走。由于web server 的工作性质决定了每个request 的大部份生命都是在网络传输中,实际上花费在server 机器上的时间片不多,这就是几个进程就能解决高并发的秘密所在
小结
Nginx 的master-worker 工作机制的优势
1、支持nginx -s reload 热部署, 这个特征在前面我们使用过
2、对于每个worker 进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多
3、每个worker 都是一个独立的进程,但每个进程里只有一个主线程,通过异步非阻塞的方式/IO 多路复用来处理请求, 即使是高并发请求也能应对.
4、采用独立的进程,互相之间不会影响,一个worker 进程退出后,其它worker 进程还在工作,服务不会中断,master 进程则很快启动新的worker 进程
5、一个worker 分配一个CPU , 那么worker 的线程可以把一个cpu 的性能发挥到极致
参数设置
worker_processes
● 需要设置多少个worker
- 每个worker 的线程可以把一个cpu 的性能发挥到极致。所以worker 数和服务器的cpu数相等是最为适宜的。设少了会浪费cpu,设多了会造成cpu 频繁切换上下文带来的损耗。
- 设置worker 数量, Nginx 默认没有开启利用多核cpu,可以通过增加worker_cpu_affinity配置参数来充分利用多核cpu 的性能
#2 核cpu,开启2 个进程
worker_processes 2;
worker_cpu_affinity 01 10;
#2 核cpu,开启4 个进程,
worker_processes 4;
worker_cpu_affinity 01 10 01 10;
#4 核cpu,开启2 个进程,0101 表示开启第一个和第三个内核,1010 表示开启第二个和第四个内核;
worker_processes 2;
worker_cpu_affinity 0101 1010;
#4 个cpu,开启4 个进程
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
#8 核cpu,开启8 个进程
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
worker_cpu_affinity 理解

配置实例

- 重新加载nginx/usr/local/nginx/sbin/nginx -s reload
- 查看nginx 的worker process 情况

worker_connection
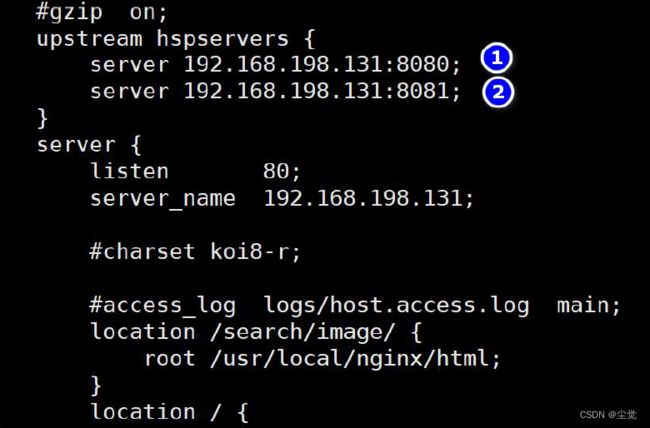
- worker_connection 表示每个worker 进程所能建立连接的最大值,所以,一个nginx 能建立的最大连接数,应该是worker_connections * worker_processes
(1)默认:worker_connections: 1024
(2)调大:worker_connections: 60000,(调大到6 万连接)
(3)同时要根据系统的最大打开文件数来调整.
系统的最大打开文件数>= worker_connections*worker_process 根据系统的最大打开文件数来调整,worker_connections 进程连接数量要小于等于系统的最大打开文件数,worker_connections 进程连接数量真实数量=worker_connections * worker_process
查看系统的最大打开文件数
ulimit -a|grep "open files"
open files (-n) 65535
- 根据最大连接数计算最大并发数:如果是支持http1.1 的浏览器每次访问要占两个连接,所以普通的静态访问最大并发数是: worker_connections * worker_processes /2,而如果是HTTP 作为反向代理来说, 最大并发数量应该是worker_connections *worker_processes/4。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端
服务的连接,会占用两个连接,
看一个示意图

配置Linux 最大打开文件数
- 使用ulimit -a 可以查看当前系统的所有限制值,使用ulimit -n 可以查看当前的最大打开文件数。
- 新装的linux 默认只有1024,当作负载较大的服务器时,很容易遇到error: too many open files。因此,需要将其改大。
- 使用ulimit -n 65535 可即时修改,但重启后就无效了。(注ulimit -SHn 65535 等效ulimit -n 65535,-S 指soft,-H 指hard)
- 有如下三种修改方式:
- 在/etc/rc.local 中增加一行ulimit -SHn 65535
- 在/etc/profile 中增加一行ulimit -SHn 65535
- 在/etc/security/limits.conf 最后增加如下两行记录
- *soft nofile 65535
- *hard nofile 65535
在CentOS 中使用第1 种方式无效果,使用第3 种方式有效果,而在Debian 中使用第2 种有效果
5. 参考: https://blog.csdn.net/weixin_43055250/article/details/124980838
搭建高可用集群
Keepalived+Nginx 高可用集群(主从模式)
集群架构图
解读
1、准备两台nginx 服务器, 一台做主服务器, 一台做备份服务器
2、两台Nginx 服务器的IP 地址, 可以自己配置, 不一定和我的一样(具体可以使用ifconfig 命令)
3、安装keepalived , 保证主从之间的通讯
4、对外提供统一的访问IP(虚拟IP-VIP)
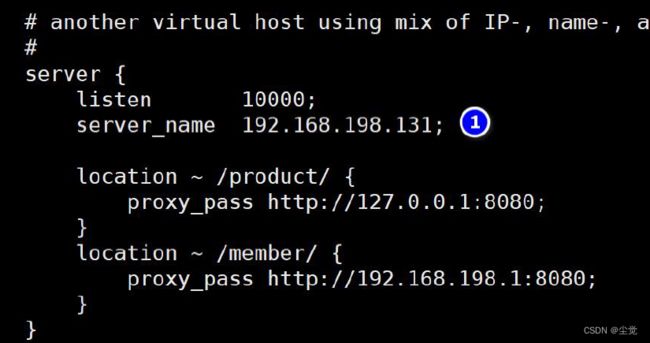
示意图

具体搭建步骤
搭建高可用集群基础环境
准备两台Linux 服务器192.168.198.130 和192.168.198.131
- 可以克隆来完成
- 也可以直接拷贝一份

在两台Linux 服务器, 安装并配置好Nginx
- 安装配置Nginx 步骤前面讲过, 如果你克隆的Linux, 本身就有安装好了Nginx, 直接使用即可.
- 验证安装是否成功, 在windows 可以通过IP 访问到Nginx,
- 因为我们是拷贝了一份Linux , 而新的Linux 的Ip 已经变化了, 所以需要克隆的Linux的nginx.conf 文件中的IP 地址, 做相应的修改

在两台Linux 服务器, 安装keepalived
- 下载keepalived-2.0.20.tar.gz 源码安装包, https://keepalived.org/download.html

- 上传到两台Linux /root 目录下
- mkdir /root/keepalived
- 解压文件到指定目录: tar -zxvf keepalived-2.0.20.tar.gz -C ./keepalived
- cd /root/keepalived/keepalived-2.0.20
- ./configure --sysconf=/etc --prefix=/usr/local
说明: 将配置文件放在/etc 目录下, 安装路径在/usr/local
- make && make install
说明: 编译并安装
8) 如果成功, 就会安装好keepalived 【可以检查一下】
说明: keepalived 的配置目录在/etc/keepalived/keepalived.conf
keepalived 的启动指令在/usr/local/sbin/keepalived
- 提示: 两台Linux 都要安装keepalived
完成高可用集群配置
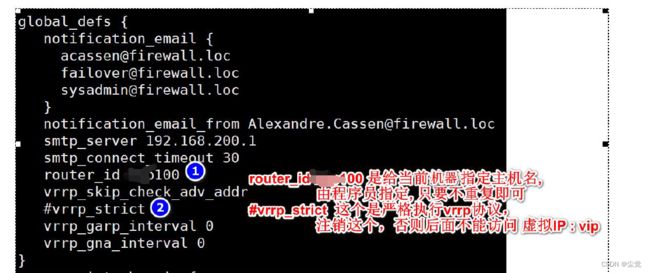
1 、将其中一台Linux( 比如192.168.198.130) 指定为Master : vi/etc/keepalived/keepalived.conf

2、将其中一台Linux( 比如192.168.198.131) 指定为Backup( 备份服务器) : vi/etc/keepalived/keepalived.conf


3、启动两台Linux 的keepalived 指令: /usr/local/sbin/keepalived
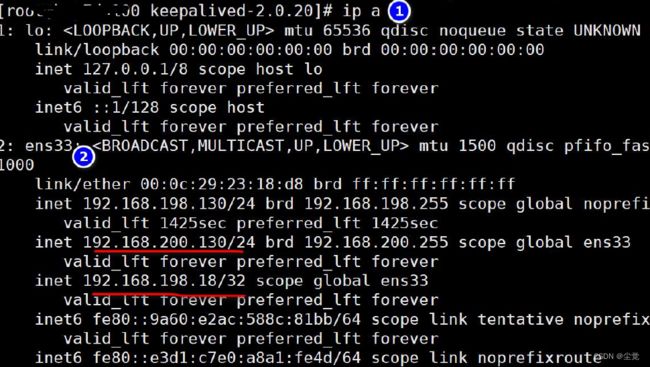
4、观察两台linux 的ens33 是否已经绑定192.168.198.18

注意事项和细节
1、keepalived 启动后无法ping 通VIP,提示ping: sendmsg: Operation not permittedhttps://blog.csdn.net/xjuniao/article/details/101793935
2、nginx+keepalived 配置说明和需要避开的坑https://blog.csdn.net/qq_42921396/article/details/123074780
测试
1、首先保证windows 可以连通192.168.198.18 这个虚拟IP

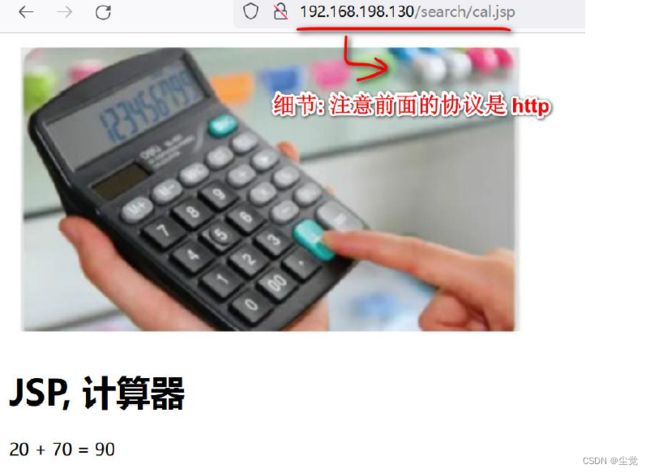
2、访问nginx 如图
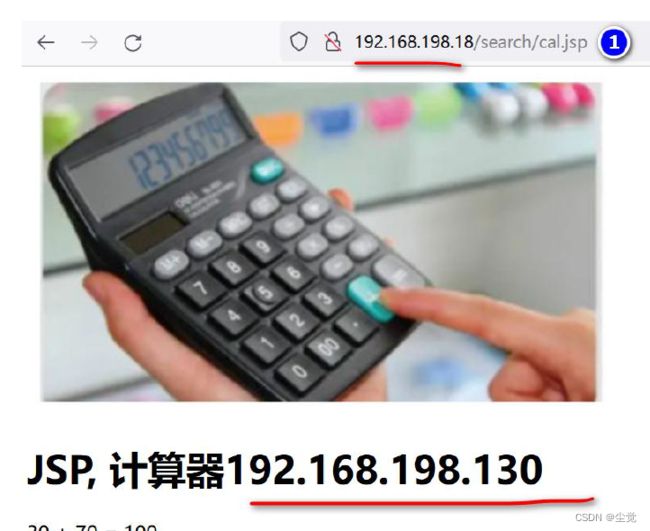
说明:大家可以看到, 因为192.168.198.130 是Master 他的优先级高, 所以访问的就是192.168.198.130 的Nginx, 同时仍然是支持负载均衡的.
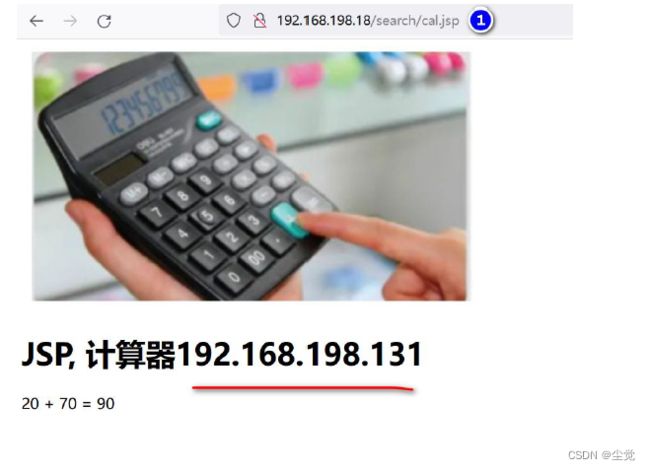
3、停止192.168.198.130 的keepalived 服务, 否则直接关闭192.168.198.130 主机, 再次访问http://192.168.198.18/search/cal.jsp , 这时虚拟IP 绑定发生漂移, 绑定到192.168.198.131 Backup 服务, 访问效果如图
这里直接关闭192.168.198.130 Master 的keepalived 来测试

自动检测Nginx 异常, 终止keepalived
实现步骤
1、编写shell 脚本: vi /etc/keepalived/ch_nginx.sh简单说明: 下面的脚本就是去统计ps -C nginx --no-header 的行数, 如果为0 , 说明nginx已经异常终止了, 就执行killall keepalived
#!/bin/bash
num=`ps -C nginx --no-header | wc -l`
if [ $num -eq 0 ];then
killall keepalived
fi
修改ch_nginx.sh 权限
chmod 755 ch_nginx.sh
修改192.168.198.130 主Master 配置文件
指令: vi /etc/keepalived/keepalived.conf

4、重新启动192.168.198.130 Master 的keepalived , 这时因为Master 的优先级高,会争夺到VIP 优先绑定.
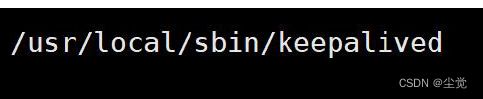

5、手动关闭192.168.198.130 Master 的Nginx

注意观察keepalived 也终止了

6、再次访问nginx , 发现192.168.198.18 这个虚拟IP 又和192.168.198.131 备份服务器绑定了.
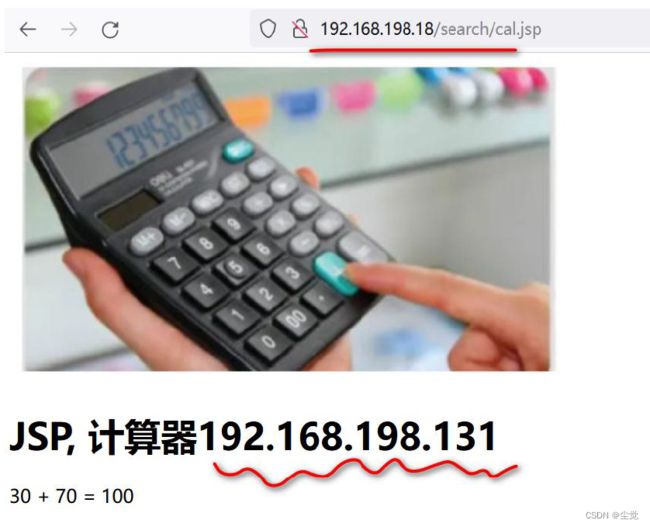
注意事项
keepalived vrrp_script 脚本不执行解决办法
-打开日志观察
tail -f /var/log/messages
-重启keepalived
systemctl restart keepalived.service
–说明一下,曾经出现过文件找不到可以修改执行脚本文件名,不要有_就OK
- 如果配置有定时检查Nginx 异常的脚本, 需要先启动nginx ,在启动keepalived ,否则keepalived 一起动就被killall 了
- 提醒: 小伙伴们配置时,会遇到各种各样问题,有针对性解决即可
配置文件keepalived.conf 详解
#这里只注释要修改的地方
global_defs {
notification_email {
[email protected] #接收通知的邮件地址
}
notification_email_from [email protected] #发送邮件的邮箱
smtp_server 192.168.200.1 #smtp server 地址
smtp_connect_timeout 30
router_id Node132 #Node132 为主机标识
vrrp_skip_check_adv_addr
#vrrp_strict #这里需要注释,避免虚拟ip 无法ping 通
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER #主节点MASTER 备用节点为BACKUP
interface ens33 #网卡名称
virtual_router_id 51 #VRRP 组名,两个节点的设置必须一样,指明属于同一VRRP 组
priority 100 #主节点的优先级(1-254 之间),备用节点必须比主节点优先级低
advert_int 1 #组播信息发送间隔,两个节点设置必须一样
authentication { #设置验证信息,两个节点必须一致
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #指定虚拟IP, 两个节点设置必须一样
192.168.200.16
}
}