ElasticSearch全文详解及具体配置
一、全文检索基础
1.什么是全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
2.相关概念
- 索引库
索引库就是存储索引的保存在磁盘上的一系列的文件。里面存储了建立好的索引信息以及文档对象

一个索引库相当于数据库中的一张表
-
document对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。每个文档都有一个唯一的编号,就是文档id
document对象相当于表中的一条记录
-
field对象
如果我们把document看做是数据库中一条记录的话,field相当于是记录中的字段。field是索引库中存储数据的最小单位。field的数据类型大致可以分为数值类型和文本类型,一般需要查询的字段都是文本
类型的,field的还有如下属性:-
是否分词:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询
-
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都
要作为查询条件 -
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取 比如:商品
名称、订单号,凡是将来要从Document中获取的Field都要存储 -
term对象 从文档对象中拆分出来的每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。term是创建索引的关键词对象
-
二、ElasticSearch简介
2.1 什么是ElasticSearch
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
2.2 ElasticSearch对比Solr
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提
供 - Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于Elasticsearch
三、Elasticsearch 安装
采用docker安装
- docker镜像下载
docker pull elasticsearch:5.6.8
- 安装es容器
docker run -di --name=kkb_es -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
9200端口(Web管理平台端口) 9300(服务默认端口)
- 开启远程连接
elasticsearch从5版本以后默认不开启远程连接,程序直接连接会报错
我们需要修改es配置开启远程连接
登录容器
docker exec -it kkb_es /bin/bash
进去config目录
cd config
修改elasticsearch.yml文件
若出现vi命令无法识别,则安装该编辑器
设置apt下载源
docker cp ~/sources.list kkb_es:/etc/apt/sources.list
安装vim编辑器
apt-get update
apt-get install vim
安装好之后就可以修改elasticsearch.yml配置文件了
http.host: 0.0.0.0
transport.host: 0.0.0.0
#集群的名称
cluster.name: my-application
#跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 192.168.249.4
配置完毕之后退出容器,重启该容器
docker restart kkb_es
- 系统参数配置
因为elasticsearch在启动时会比较占据资源,所以将虚拟机进行系统调优开放更多的资源
修改vi /etc/security/limits.conf,追加如下内容
* soft nofile 65536
* hard nofile 65536
修改vi /etc/sysctl.conf,追加内容
vm.max_map_count=655360
执行下面命令,使修改后的内核参数生效
sysctl -p
重启虚拟机,再启动容器,即可远程访问
reboot
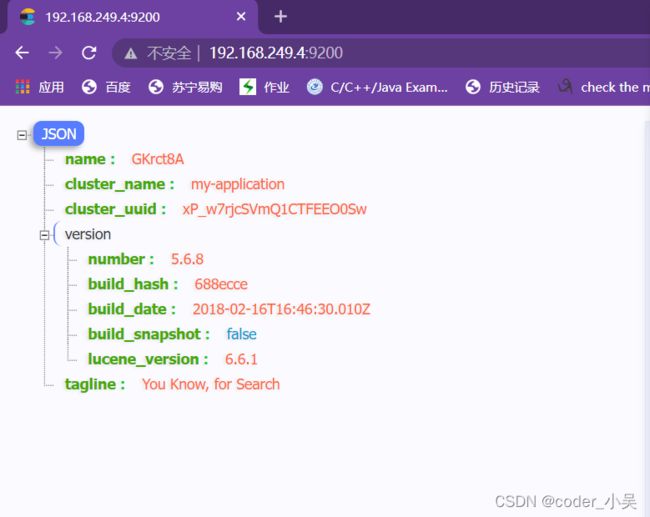
四、ElasticSearch的客户端操作
IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现
安装
- 下载地址https://github.com/medcl/elasticsearch-analysis-ik/releases
将ik分词器上传到服务器.解压并改名为ik
unzip elasticsearch-analysis-ik-5.6.8.zip
mv elasticsearch ik
将ik目录拷贝到docker容器的plugins目录下
docker cp ./ik kkb_es:/usr/share/elasticsearch/plugins
- 测试
访问 :http://192.168.249.4:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员出现如下页面
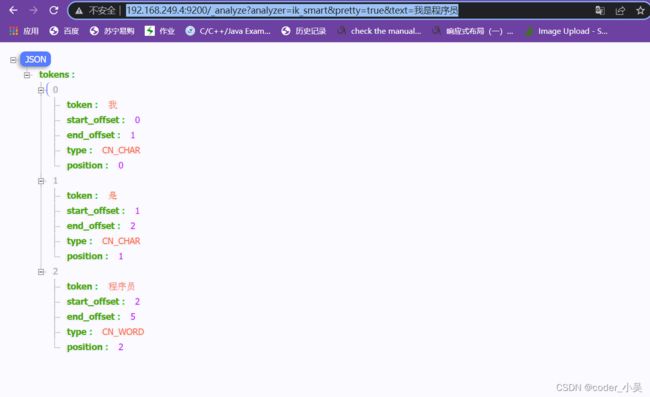
-
ik_max_word:会将文本做最细粒度的拆分
比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
-
ik_smart:会做最粗粒度的拆分
比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
Kibana使用
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现
Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化
下载安装
这里使用docker安装
- 镜像安装
docker pull docker.io/kibana:5.6.8
- 安装kibana容器
docker run -it -d -e ELASTICSEARCH_URL=http://192.168.249.4:9200 --name kibana -p 5601:5601 kibana:5.6.8
ELASTICSEARCH_URL=http://192.168.249.4:9200:是指链接的es的地址
restart=always:每次服务都会重启,也就是开启启动
5601:5601:端口号
- 测试
访问http:192.168.249.4:5601如下图所示

Kibana使用
Kibana具体使用可以查看其他文档,这里不再赘述
ElasticSearch编程操作
创建工程
org.elasticsearch
elasticsearch
5.6.8
org.elasticsearch.client
transport
5.6.8
org.apache.logging.log4j
log4j-to-slf4j
2.9.1
org.slf4j
slf4j-api
1.7.24
org.slf4j
slf4j-simple
1.7.21
log4j
log4j
1.2.12
junit
junit
4.12
创建索引index
@Test
public void createIndex() {
//1. 配置
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
//2. 客户端
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.249.4"), 9300));
//3. 使用api创建索引
client.admin().indices().prepareCreate("hello_index").get();
//4. 关闭client
client.close();
}
索引即相当于数据库
创建mapping映射
//创建映射
@Test
public void setMappings() throws IOException, ExecutionException, InterruptedException {
// 添加映射
/**
* 格式:
* "mappings" : {
}
}
"article" : {
"dynamic" : "false",
"properties" : {
"id" : { "type" : "string" },
"content" : { "type" : "string" },
"author" : { "type" : "string" }
}
}
}
*/
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "integer").field("store", "yes")
.endObject()
.startObject("title")
.field("type", "string").field("store", "yes").field("analyzer",
"ik_smart")
.endObject()
.startObject("content")
.field("type", "string").field("store", "yes").field("analyzer",
"ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
// 创建索引
client.admin().indices().preparePutMapping("hello_index")
.setType("article").setSource(builder).get();
//释放资源
client.close();
}
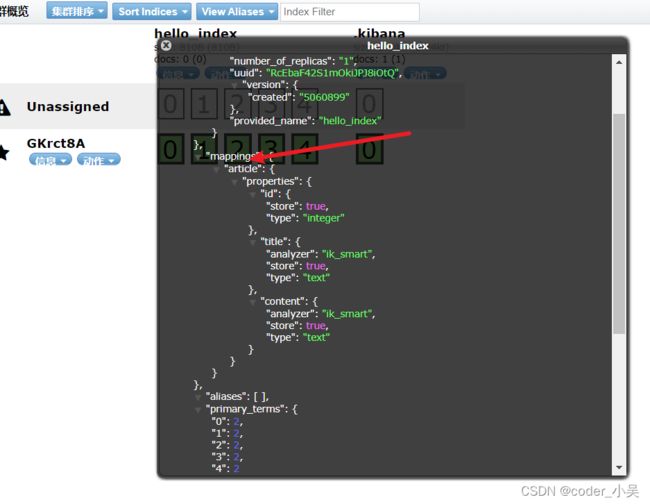
mapping映射如下所示
建立文档document
建立文档(通过XContentBuilder)
/**
* 通过XContentBuilder构建Document对象
* @throws Exception
*/
@Test
public void testAddDocument() throws Exception {
//创建一个client对象
//创建一个文档对象
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("id", 2l)
.field("title", "北方入秋速度明显加快 多地降温幅度最多可达10度 22222")
.field("content", "阿联酋一架客机在纽约机场被隔离 10名乘客病倒")
.endObject();
//把文档对象添加到索引库
client.prepareIndex()
//设置索引名称
.setIndex("hello_index")
//设置type
.setType("article")
//设置文档的id,如果不设置的话自动的生成一个id
.setId("2")
//设置文档信息
.setSource(builder)
//执行操作
.get();
//关闭客户端
client.close();
}
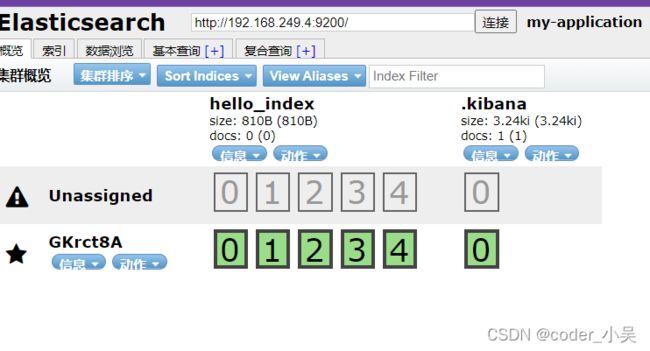
查看数据浏览板块里面的hello_index索引,如下图所示

建立文档(使用Jackson转换实体)
- 创建Article实体类
package com.study;
public class Article {
private Integer id;
private String title;
private String content;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
- 添加jackson依赖
com.fasterxml.jackson.core
jackson-core
2.8.1
com.fasterxml.jackson.core
jackson-databind
2.8.1
com.fasterxml.jackson.core
jackson-annotations
2.8.1
- 构造相关方法
@Test
public void testAddDocument2() throws Exception {
//创建一个Article对象
Article article = new Article();
//设置对象的属性
article.setId(3l);
article.setTitle("MH370坠毁在柬埔寨密林?中国一公司调十颗卫星去拍摄");
article.setContent("警惕荒唐的死亡游戏!俄15岁少年输掉游戏后用电锯自杀");
//把article对象转换成json格式的字符串。
ObjectMapper objectMapper = new ObjectMapper();
String jsonDocument = objectMapper.writeValueAsString(article);
System.out.println(jsonDocument);
//使用client对象把文档写入索引库
client.prepareIndex("hello_index","article", "3")
.setSource(jsonDocument, XContentType.JSON)
.get();
//关闭客户端
client.close();
}
查看数据浏览中的hello_index相关索引库的信息
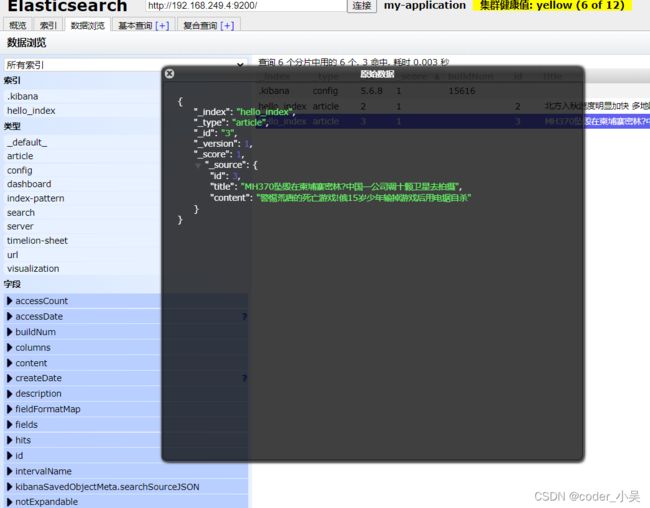
对hello_index索引库添加多条Document对象,方便接下来的操作
@Test
public void testAddDocument3() throws Exception {
for (int i = 4; i < 100; i++) {
//创建一个Article对象
Article article = new Article();
//设置对象的属性
article.setId(i);
article.setTitle("女护士路遇昏迷男子跪地抢救:救人是职责更是本能" + i);
article.setContent("江西变质营养餐事件已致24人就医 多名官员被调查" + i);
//把article对象转换成json格式的字符串。
ObjectMapper objectMapper = new ObjectMapper();
String jsonDocument = objectMapper.writeValueAsString(article);
//使用client对象把文档写入索引库
client.prepareIndex("hello_index","article", i + "")
.setSource(jsonDocument, XContentType.JSON)
.get();
}
//关闭客户端
client.close();
}
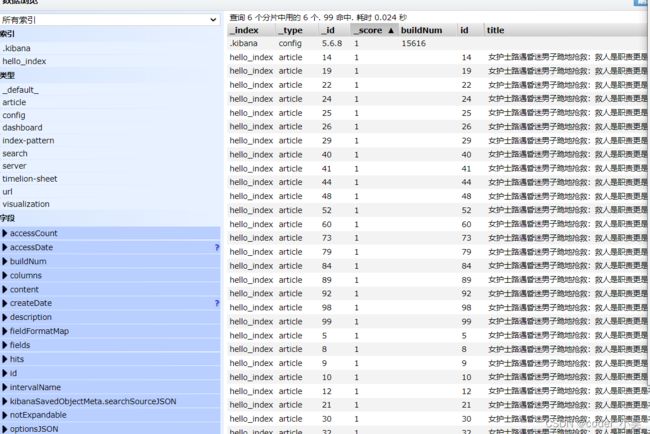
查询文档操作
抽取共用方法
构建共用方法,方便后续操作调用使用
public void search(QueryBuilder queryBuilder) {
//执行查询得到
SearchResponse searchResponse = client.prepareSearch("hello_index")
.setTypes("article")
.setQuery(queryBuilder)
.get();
//处理结果
SearchHits searchHits = searchResponse.getHits();
System.out.println("总行数" + searchHits.getTotalHits());
Iterator it = searchHits.iterator();
while (it.hasNext()){
SearchHit searchHit = it.next();
//打印迭代器里面 source-document的json输出
System.out.println(searchHit.getSourceAsString());
}
}
termQuery
@Test
public void testQueryTearm(){
//构建quertBuilder
QueryBuilder queryBuilder = QueryBuilders.termQuery("title","女护士");
search(queryBuilder);
}
testQueryByQueryString
//创建一个QueryBuilder对象
//参数1:要搜索的字段
//参数2:要搜索的关键词
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("美丽的女护士").defaultField("title");
search(queryBuilder);
testQueryByMatchQuery
@Test
public void testQueryByMatchQuery() throws Exception {
//创建一个QueryBuilder对象
//参数1:要搜索的字段
//参数2:要搜索的关键词
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "美丽的女护士");
search(queryBuilder);
}
使用文档ID查询文档
@Test
public void testSearchById() throws Exception {
//创建一个client对象
//创建一个查询对象
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1", "2");
search(queryBuilder);
}
查询文档分页操作
@Test
public void testQueryMatchAllQuery() throws Exception {
//创建一个QueryBuilder对象
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
//执行查询
//执行查询得到
SearchResponse searchResponse = client.prepareSearch("hello_index")
.setTypes("article")
.setQuery(queryBuilder)
//下标起始位置
.setFrom(0)
//一页条数
.setSize(5)
.get();
//处理结果
SearchHits searchHits = searchResponse.getHits();
System.out.println("总行数" + searchHits.getTotalHits());
Iterator it = searchHits.iterator();
while (it.hasNext()){
SearchHit searchHit = it.next();
//打印迭代器里面 source-document的json输出
System.out.println(searchHit.getSourceAsString());
}
}
查询结果高亮操作
代码实现
@Test
public void highlightSearchTest() throws Exception {
QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("北京市民",
"title", "content");
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title").field("content");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
//执行查询
SearchResponse searchResponse = client.prepareSearch("hello_index")
.setTypes("article")
.setQuery(queryBuilder)
//设置高亮信息
.highlighter(highlightBuilder)
.get();
//取查询结果
SearchHits searchHits = searchResponse.getHits();
//取查询结果的总记录数
System.out.println("查询结果总记录数:" + searchHits.getTotalHits());
//查询结果列表
Iterator iterator = searchHits.iterator();
while(iterator.hasNext()) {
SearchHit searchHit = iterator.next();
//取文档的属性
System.out.println("-----------文档的属性");
Map document = searchHit.getSource();
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println("************高亮结果");
Map highlightFields =
searchHit.getHighlightFields();
// //取title高亮显示的结果
if (highlightFields.size() <=0) continue;
for (Map.Entry entry :
highlightFields.entrySet()) {
System.out.println(entry.getKey() + ":\t" +
Arrays.toString(entry.getValue().getFragments()));
}
}
//关闭client
client.close();
}
Spring Data ElasticSearch
简介
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data ElasticsearchPOJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层。
官方网站:http://projects.spring.io/spring-data-elasticsearch/
入门案例
- 导入依赖
org.springframework.boot
spring-boot-starter-parent
2.1.16.RELEASE
1.8
org.springframework.boot
spring-boot-starter-data-elasticsearch
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
- 配置启动器
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class,args);
}
}
- 配置yml文件
spring:
data:
elasticsearch:
cluster-name: my-application
cluster-nodes: 192.168.249.4:9300
- 编写实体类
@Document(indexName = "wx_blog", type = "article")
public class Article {
@Id
@Field(type = FieldType.Long, store = true)
private long id;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")
private String content;
}
- 编写Dao
方法命名规则查询的基本语法findBy + 属性 + 关键词 + 连接符

public interface ArticleRepository extends ElasticsearchRepository {
}
- 创建测试类
package com.study;
import com.study.dao.ArticleRepository;
import com.study.entity.Article;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runner.notification.RunListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
import java.util.Optional;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElaticSearchTest {
@Autowired
private ArticleRepository articleRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void createIndex(){
elasticsearchTemplate.createIndex(Article.class);
}
@Test
public void addDocument() throws Exception {
for (int i = 10; i <= 20; i++) {
//创建一个Article对象
Article article = new Article();
article.setId(i);
article.setTitle("女护士路遇昏迷男子跪地抢救:救人是职责更是本能" + i);
article.setContent("这是一个美丽的女护士妹妹" + i);
//把文档写入索引库
articleRepository.save(article);
}
}
@Test
public void deleteDocumentById() throws Exception {
articleRepository.deleteById(1l);
//全部删除
// articleRepository.deleteAll();
}
@Test
public void findAll() throws Exception {
Iterable articles = articleRepository.findAll();
articles.forEach(a-> System.out.println(a));
}
@Test
public void testFindById() throws Exception {
Optional optional = articleRepository.findById(10l);
Article article = optional.get();
System.out.println(article);
}
@Test
public void testFindByTitle() throws Exception {
List list = articleRepository.findByTitle("女护士");
list.stream().forEach(a-> System.out.println(a));
}
@Test
public void testFindByTitleOrContent() throws Exception {
Pageable pageable = PageRequest.of(1, 5);
articleRepository.findByTitleOrContent("title", "女护士", pageable)
.forEach(a-> System.out.println(a));
}
@Test
public void testNativeSearchQuery() throws Exception {
//创建一个查询对象
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("女护士").defaultField("title"))
.withPageable(PageRequest.of(0, 15))
.build();
//执行查询
List articleList = elasticsearchTemplate.queryForList(query, Article.class);
articleList.forEach(a-> System.out.println(a));
}
}
聚合查询
实体类
@Document(indexName = "car_index", type = "car")
public class Car {
@Id
@Field(type = FieldType.Long, store = true)
private Long id;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart")
private String name;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart", fielddata
= true)
private String color;
@Field(type = FieldType.Text, store = true, analyzer = "ik_smart", fielddata
= true)
private String brand;
@Field(type = FieldType.Double, store = true)
private Double price;
public Car(Long id, String name, String brand, String color, Double price) {
this.id = id;
this.name = name;
this.color = color;
this.brand = brand;
this.price = price;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
}
Dao
public interface CarDao extends ElasticsearchRepository {
}
初始化索引库
@Autowired
private CarDao carDao;
@Test
public void initIndex() {
carDao.save(new Car(1l, "比亚迪A1", "红色", "比亚迪", 50000d));
carDao.save(new Car(2l, "比亚迪A2", "白色", "比亚迪", 70000d));
carDao.save(new Car(3l, "比亚迪A3", "白色", "比亚迪", 80000d));
carDao.save(new Car(4l, "比亚迪A4", "红色", "比亚迪", 60000d));
carDao.save(new Car(5l, "比亚迪A5", "红色", "比亚迪", 90000d));
carDao.save(new Car(6l, "宝马A1", "红色", "宝马", 10000d));
carDao.save(new Car(7l, "宝马A2", "黑色", "宝马", 20000d));
carDao.save(new Car(8l, "宝马A3", "黑色", "宝马", 30000d));
carDao.save(new Car(9l, "宝马A4", "红色", "宝马", 40000d));
carDao.save(new Car(10l, "宝马A5", "红色", "宝马", 50000d));
carDao.save(new Car(11l, "奔驰A1", "红色", "奔驰", 10000d));
carDao.save(new Car(12l, "奔驰A2", "黑色", "奔驰", 20000d));
carDao.save(new Car(13l, "奔驰A3", "黑色", "奔驰", 30000d));
carDao.save(new Car(14l, "奔驰A4", "红色", "奔驰", 40000d));
carDao.save(new Car(15l, "奔驰A5", "红色", "奔驰", 50000d));
}
代码实现
划分桶
@Test
public void testQuerySelfAggs(){
//查询条件的构建器
NativeSearchQueryBuilder queryBuilder = new
NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery());
//排除所有的字段查询,
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{},null));
//添加聚合条件
queryBuilder.addAggregation(AggregationBuilders.terms("group_by_color").field("color"));
//执行查询,把查询结果直接转为聚合page
AggregatedPage aggPage = (AggregatedPage)
carDao.search(queryBuilder.build());
//从所有的聚合中获取对应名称的聚合
StringTerms agg = (StringTerms) aggPage.getAggregation("group_by_color");
//从聚合的结果中获取所有的桶信息
List buckets = agg.getBuckets();
for (StringTerms.Bucket bucket : buckets) {
String brand = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println("color = " + brand+" 总数:"+docCount);
}
}
桶内度量
@Test
public void testQuerySelfSubAggs(){
//查询条件的构建器
NativeSearchQueryBuilder queryBuilder = new
NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery());
//排除所有的字段查询,
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{},null));
//添加聚合条件
queryBuilder.addAggregation(AggregationBuilders.terms("group_by_color").field("color")
.subAggregation(AggregationBuilders.avg("avg_price").field("price")));
//执行查询,把查询结果直接转为聚合page
AggregatedPage aggPage = (AggregatedPage)
carDao.search(queryBuilder.build());
//从所有的聚合中获取对应名称的聚合
StringTerms agg = (StringTerms) aggPage.getAggregation("group_by_color");
//从聚合的结果中获取所有的桶信息
List buckets = agg.getBuckets();
for (StringTerms.Bucket bucket : buckets) {
String brand = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
//取得内部聚合
InternalAvg avg = (InternalAvg)
bucket.getAggregations().asMap().get("avg_price");
System.out.println("brand = " + brand+" 总数:"+docCount+" 平均价格:"+avg.getValue());
}
}