Redis高可用系列——Hash类型介绍及底层原理详解
文章目录
- 前言
- Hash
-
- 概述
- 应用场景
- 底层原理
-
- ziplist与listpack
-
- ziplist结构
- listpack结构
- zipList的连锁更新问题
- listpack是如何解决的
- hashTable
- ziplist和hashTable的转换
-
- ziplist的废弃
- hashTable变得越来越长怎么办
-
- rehash 步骤
- 渐进式 rehash
- 总结
- 系列文章目录
前言
Redis是一种高性能的键值型数据库,它支持多种数据结构,其中一种是hash类型。hash类型可以存储一个键值对的集合,类似于Java中的HashMap或Python中的字典。hash类型的优点是可以快速地访问、修改或删除集合中的任意元素,而不需要遍历整个集合。接下来,我们将介绍hash类型及底层原理
Hash
概述
hash 是一个键值对集合,它可以存储多个字段和值,类似于编程语言中的 map 对象。一个 hash 类型的键最多可以存储 2^32 - 1 个字段。
Hash类型的底层实现有三种:
ziplist:压缩列表,当 hash达到一定的阈值时,会自动转换为hashtable结构listpack:紧凑列表,在Redis7.0之后,listpack正式取代ziplist。同样的,当 hash达到一定的阈值时,会自动转换为hashtable结构hashtable:哈希表,类似map
应用场景
hash 类型的应用场景主要是存储对象,比如:
- 用户信息,利用 hset 和 hget 命令实现对象属性的增删改查。
- 购物车,利用 hincrby 命令实现商品数量的增减。
- 配置信息,利用 hmset 和 hmget 命令实现批量设置和获取配置项。
底层原理
Redis在存储hash结构的数据,为了达到内存和性能的平衡,也针对少量存储和大量存储分别设计了两种结构,分别为:
- ziplist(redis7.0之前使用)和listpack(redis7.0之后使用)
- hashTable
从ziplist/listpack编码转换为hashTable编码是通过判断元素数量或单个元素Key或Value的长度决定的:
hash-max-ziplist-entries:表示当 hash中的元素数量小于或等于该值时,使用 **ziplist **编码,否则使用 hashtable编码。**ziplist **是一种压缩列表,它可以节省内存空间,但是访问速度较慢。hashtable是一种哈希表,它可以提高访问速度,但是占用内存空间较多。默认值为 512。hash-max-ziplist-value:表示当 hash中的每个元素的key和value的长度都小于或等于该值时,使用 ziplist编码,否则使用 hashtable编码。默认值为 64。
ziplist与listpack
ziplist/listpack都是hash结构用来存储少量数据的结构。从Redis7.0后,hash默认使用listpack结构。因为 ziplist有一个致命的缺陷,就是连锁更新,当一个节点的长度发生变化时,可能会导致后续所有节点的长度字段都要重新编码,这会造成极差的性能
ziplist结构
ziplist是一种紧凑的链表结构,它将所有的字段和值顺序地存储在一块连续的内存中。

Redis中ziplist源码
typedef struct {
/* 当使用字符串时,slen表示为字符串长度 */
unsigned char *sval;
unsigned int slen;
/* 当使用整形时,sval为NULL,lval为ziplistEntry的value */
long long lval;
} ziplistEntry;
listpack结构

zipList的连锁更新问题
ziplist的每个entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个byte:
- 如果前一节点的长度小于254个byte,则采用1个byte来保存这个长度值
- 如果前一节点的长度大于等于254个byte,则采用5个byte来保存这个长度值,第一个byte为0xfe,后四个byte才是真实长度数据
假设,现有有N个连续、长度为250~253个byte的entry,因此entry的previous_entry_length属性占用1个btye

当第一节长度大于等于254个bytes,导致第二节previous_entry_length变为5个bytes,第二节的长度由250变为254。而第二节长度的增加必然会影响第三节的previous_entry_length。ziplist这种特殊套娃的情况下产生的连续多次空间扩展操作成为连锁更新。新增、删除都可能导致连锁更新的产生。
listpack是如何解决的

- 由于ziplist需要倒着遍历,所以需要用previous_entry_length记录前一个entry的长度。而listpack可以通过total_bytes和end计算出来。所以previous_entry_length不需要了。
- listpack 的设计彻底消灭了 ziplist 存在的级联更新行为,元素与元素之间完全独立,不会因为一个元素的长度变长就导致后续的元素内容会受到影响。
- 与ziplist做对比的话,牺牲了内存使用率,避免了连锁更新的情况。从代码复杂度上看,listpack相对ziplist简单很多,再把增删改统一做处理,从listpack的代码实现上看,极简且高效。
hashTable
hashTable是一种散列表结构,它将字段和值分别存储在两个数组中,并通过哈希函数计算字段在数组中的索引
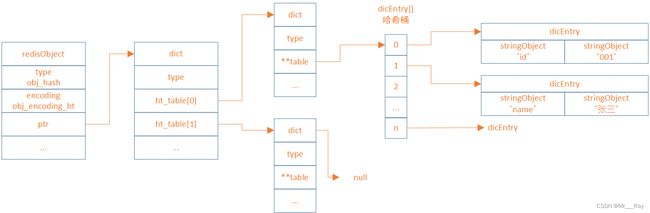
Redis中hashTable源码
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* 当进行rehash时,rehashidx为-1 */
int16_t pauserehash; /* 如果rehash暂停,pauserehash则大于0,(小于0表示代码错误)*/
signed char ht_size_exp[2]; /* 哈希桶的个数(size = 1<ziplist和hashTable的转换

127.0.0.1:6379> hset h1 id 123456789012345678901234567890123456789012345678901234567890abcd
(integer) 1
127.0.0.1:6379> object encoding h1
"ziplist"
127.0.0.1:6379> hset h2 id 123456789012345678901234567890123456789012345678901234567890abcde
(integer) 1
127.0.0.1:6379> object encoding h2
"hashtable"
ziplist的废弃
显然是ziplist在field个数太大、key太长、value太长三者有其一的时候会有以下问题:
- ziplist每次插入都有开辟空间,连续的
- 查询的时候,需要从头开始计算,查询速度变慢
hashTable变得越来越长怎么办
扩容,hashTabel是怎么扩容的?使用的是渐进式扩容rehash。rehash会重新计算哈希值,且将哈希桶的容量扩大。
rehash 步骤
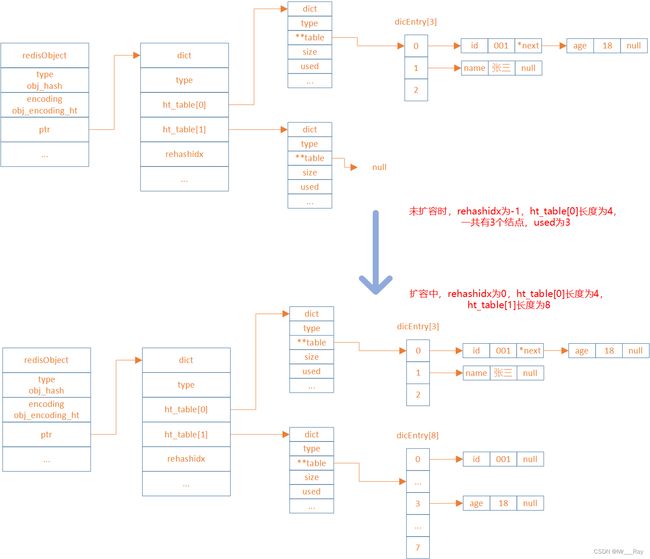
扩展哈希和收缩哈希都是通过执行rehash来完成,这其中就涉及到了空间的分配和释放,主要经过以下五步:
- 为字典dict的ht[1]哈希表分配空间,其大小取决于当前哈希表已保存节点数(即:
ht[0].used):- 如果是扩展操作则ht[1]的大小为2的n次方中第一个大于等于
ht[0].used * 2属性的值(比如used=3,此时ht[0].used * 2=6,故2的3次方为8就是第一个大于used * 2的值(2 的 2 次方 6))。 - 如果是收缩操作则ht[1]大小为 2 的 n 次方中第一个大于等于
ht[0].used的值
- 如果是扩展操作则ht[1]的大小为2的n次方中第一个大于等于
- 将字典中的属性
rehashidx的值设置为0,表示正在执行rehash操作 - 将ht[0]中所有的键值对依次重新计算哈希值,并放到ht[1]数组对应位置,每完成一个键值对的
rehash之后rehashidx的值需要自增1 - 当ht[0]中所有的键值对都迁移到ht[1]之后,释放ht[0],并将ht[1]修改为ht[0],然后再创建一个新的ht[1]数组,为下一次rehash做准备
- 将字典中的属性
rehashidx设置为-1,表示此次rehash操作结束,等待下一次rehash
渐进式 rehash
Redis中的这种重新哈希的操作因为不是一次性全部rehash,而是分多次来慢慢的将ht[0]中的键值对rehash到ht[1],故而这种操作也称之为渐进式rehash。渐进式rehash可以避免集中式rehash带来的庞大计算量,是一种分而治之的思想。
在渐进式rehash过程中,因为还可能会有新的键值对存进来,此时Redis的做法是新添加的键值对统一放入ht[1]中,这样就确保了ht[0]键值对的数量只会减少。
当正在执行rehash操作时,如果服务器收到来自客户端的命令请求操作,则**会先查询ht[0],查找不到结果再到****ht[1]**中查询
总结
Redis hash类型是一种可以存储键值对的集合的数据结构,它有以下特点:
- 可以快速地访问、修改或删除集合中的任意元素
- 可以节省内存空间,因为它会根据键值对的数量和长度来选择合适的底层数据结构
- 可以动态地扩容或缩容,因为它会根据键值对的数量来重新分配数组空间
Redis hash类型的底层实现有两种数据结构,分别是listpack和hashtable。listpack将所有的键值对顺序地存储在一块连续的内存空间中,节省了内存空间,但牺牲了一些读写性能。hashtable是一种散列表,它将键值对分散地存储在一个数组中,每个数组元素是一个链表,用来解决哈希冲突。hashtable占用更多的内存空间,但提高了读写性能。
系列文章目录
Redis内存优化——String类型介绍及底层原理详解
Redis内存优化——Hash类型介绍及底层原理详解
Redis内存优化——List类型介绍及底层原理详解
Redis内存优化——Set类型介绍及底层原理详解
Redis内存优化——ZSet类型介绍及底层原理详解
Redis内存优化——Stream类型介绍及底层原理详解
Redis内存优化——Hyperloglog、GEO、Bitmap、Bitfield类型详解
Redis的三种持久化策略及选取建议