提取气象word文档中的各站点降水表格汇总成excel表格并标出暴雨以上量级
初次写稿,颇多瑕疵,有问题的请多多指教
- 所遇问题
- 所需要的库
- 代码解析
-
- 前期思路
- 一、遍历得到的word文档绝对路径
- 二、定义一个初始字典。
- 三、读取word文档内容,将站点数据赋值给字典。
- 四、用循环把所有读取的word生成的df一个个合并。
- 五、最后输出部分,要作对暴雨量级以上的数据作处理。
- 脚本汇总
- 参考
所遇问题
不知大家是否有过,面对一大堆.doc的文档,然后叫你从中提取里面的数据汇总成excel发给上司,面对这样的文件你会怎么做?
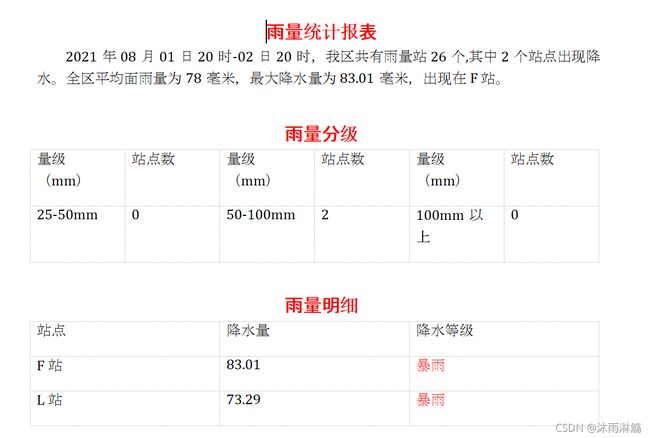
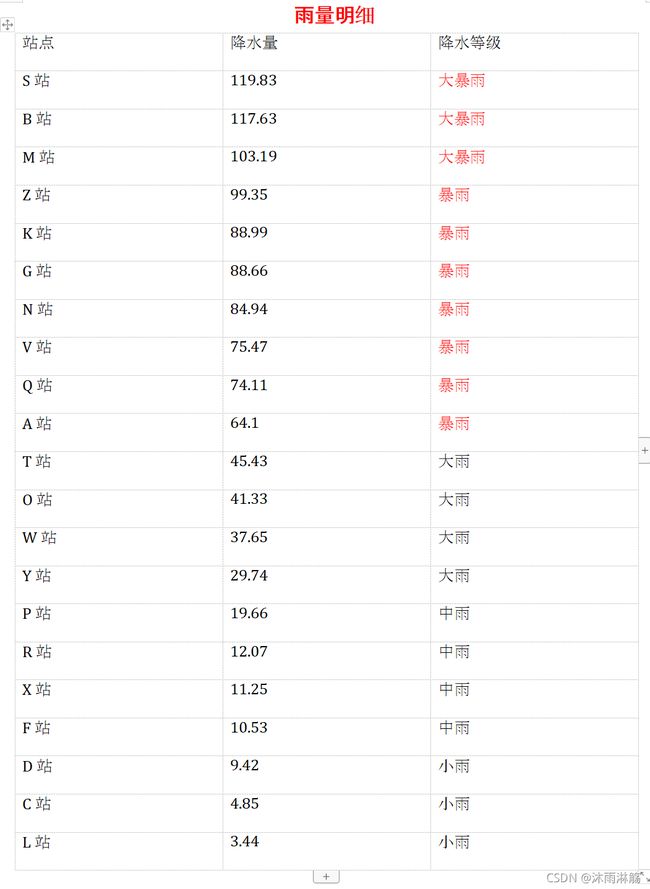
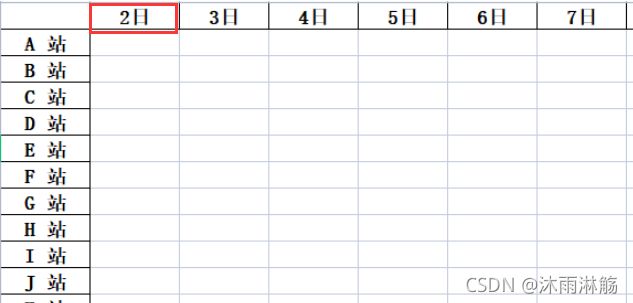
然后叫你把降水明细各个站点的降水量写入一个excel表格中,像这样:

并且把降水等级在暴雨以上的标红。如果是你该怎么做?一个个复制录入?还是有其他的技巧——((٩(//̀Д/́/)۶))
本人对office不精通,所以只能尝试着摸索用python的方式来呈现。
所需要的库
- python-docx用于打开word文档读取其中表格 ,具体安装可以参考:
vitrovitro大大的《python-docx处理word文档功能详细说明》; - pandas本文中主要用于构建一个dataframe表格,以excel输出;
- os用于遍历文件夹所有word文档,并通过docx打开读取;
- string用于对应我生成的以字母名命的站点;
代码解析
前期思路
- 遍历得到所有word文档,并添加到一个列表中:
- 定义一个字典使全部站点对应的值(降水量)都为0。;
- 打开并读取word文档所有内容,找到并截取指定位置的数据,根据对应站点赋值给字典;
- 生成第一个dataframe的表格,通过循环将得到的dataframe表格合并,最后将最终的dataframe表格输出成excel;
一、遍历得到的word文档绝对路径
if __name__ == '__main__':
path = 'F:/biancheng/duty/python/(教程)任务十五(大):提取word表格生成excel教程/'
fileType = '.docx'
file_name =[]
filename = []
for file in os.listdir(path):
#判断'.docx'在不在读取到文件名的字符串中
if fileType in file:
file_name.append(file)
filename = [path +item for item in file_name]
得到这个文件夹所有.docx格式的word文档绝对路径。
二、定义一个初始字典。
dic = {}
site = [i+' 站' for i in string.ascii_uppercase]
for i in site:
dic[i] = 0
三、读取word文档内容,将站点数据赋值给字典。
doc = Document(path)
para = doc.paragraphs
#读取几日的时间标题头,即第一段的什么时间出现的降水现象概况。
for i in para:
t = i.text.replace(' ','')
if t[0] == '2':
break
strtime = str(int(t[15:17]))+'日'#[8::10]
#表格读取
tb1 = doc.tables[1]
tb_rows = tb1.rows
row_data = []
#先将表格一行的所有内容当作一个元素交给列表。
for i in range(len(tb_rows)):
row_cells = tb_rows[i].cells
for cell in row_cells:
row_data.append(cell.text)

#re_i作为排除第一行,也就是表头的'站点'、'降水量'等字符串,直接赋值会出bug。
re_i = 0
for i in range(len(row_data)):
if (i+1)%3 == 0:
re_i += 1
if re_i == 1:
continue
else:
#从上图看到'F 站'处于py的第3个位置,数据在第4个位置。
#这个时候i处于5,站点的赋值就是:
dic[row_data[i-2]] = float(row_data[i-1])
#将字典用dataframe的形式表示出来。
df = pd.DataFrame.from_dict(dic,orient='index',columns = [strtime])

四、用循环把所有读取的word生成的df一个个合并。
#定义一个df列表,把所有df装进去。
df = []
a = 0
for filepath in filename:
df.append(re_frame(filepath))
#开始合并处理,首先第一个肯定什么都合不了,定为cf。
if a == 0:
cf = df[a]
a = a + 1
else:
#第二个就并在第一个df的右边,直到循环结束。
cf = cf.join(df[a],how='right')
a = a + 1
五、最后输出部分,要作对暴雨量级以上的数据作处理。
首先定义一个颜色的函数,大于50的标红,其他的为黑:
def colors(val):
color = 'red' if val>50 else 'black'
return 'color:%s'%color
最后输出:
cf.style.applymap(colors).to_excel(path + '实况统计报表.xlsx')
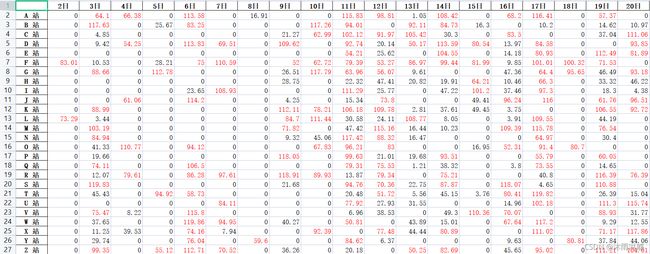
脚本汇总
from docx import Document
import os
import pandas as pd
import string
def re_frame(path):
#定义一个承装某某站点对应降水量多少的字典:dic。
#降水的数值默认为0
#site站点列表:添加为某某站点,这个站点的排序是输出到excel的排序,这里以a-z站为名。
dic = {}
site = [i+' 站' for i in string.ascii_uppercase]
for i in site:
dic[i] = 0
#生成dataframe
doc = Document(path)
para = doc.paragraphs
#时间标题头
for i in para:
t = i.text.replace(' ','')
if t[0] == '2':
break
strtime = str(int(t[15:17]))+'日'#[8::10]
#表格读取
tb1 = doc.tables[1]
tb_rows = tb1.rows
row_data = []
for i in range(len(tb_rows)):
row_cells = tb_rows[i].cells
for cell in row_cells:
row_data.append(cell.text)
re_i = 0
for i in range(len(row_data)):
if (i+1)%3 == 0:
re_i += 1
if re_i == 1:
continue
else:
dic[row_data[i-2]] = float(row_data[i-1])
df = pd.DataFrame.from_dict(dic,orient='index',columns = [strtime])
return df
def colors(val):
color = 'red' if val>50 else 'black'
return 'color:%s'%color
if __name__ == '__main__':
path = 'F:/biancheng/duty/python/(教程)任务十五(大):提取word表格生成excel教程/'
fileType = '.docx'
file_name =[]
filename = []
for file in os.listdir(path):
#判断'.docx'在不在读取到文件名的字符串中
if fileType in file:
file_name.append(file)
filename = [path +item for item in file_name]
df = []
a = 0
for filepath in filename:
#print(filepath)
df.append(re_frame(filepath))
if a == 0:
cf = df[a]
print(cf)
a = a + 1
continue
else:
cf = cf.join(df[a],how='right')
a = a + 1
print(cf)
cf.style.applymap(colors).to_excel(path + '实况统计报表.xlsx')
参考
【1】https://blog.csdn.net/deyuku8148/article/details/102447623
【2】https://blog.csdn.net/d1240673769/article/details/118958204
还有其他部分参考的找不到了
……
下一份 预告——
word生excel的后续之如何批量生成这么多的word
搞那个比这篇老复杂了,满满是泪₍₍ (̨̡ ‾᷄ᗣ‾᷅ )̧̢ ₎₎