数据分析案例-气象数据分析
目录
实验背景
待检验的假设:靠海对气候的影响
实验过程
实验步骤
温度数据分析
湿度数据分析
风向频率玫瑰图
实验总结
实验背景
气象数据是在网上很容易找到的一类数据。很多网站都提供以往的气压、气温、湿度和降雨量等气象数据。只需指定位置和日期,就能获取一个气象数据文件。这些测量数据是由气象站收集的。气象数据这类数据源涵盖的信息范围较广。数据分析的目的是把原始数据转化为信息,再把信息转化为知识,因此拿气象数据作为数据分析的对象来讲解数据分析全过程再合适不过。
待检验的假设:靠海对气候的影响
靠海对气候有什么影响?这个问题可以作为数据分析的一个不错的出发点。我不想把本章写成科学类读物,只是想借助这样一种方式,让数据分析爱好者能够把所学用于实践,解决 “海洋对一个地区的气候有何影响” 这个问题。
我们选取了意大利的 10 个城市。随后将分析它们的天气数据,其中 5 个城市在距海 100 公里范围内,其余 5 个距海 100~400 公里。
选作样本的城市列表如下:
- Ferrara(费拉拉)
- Torino(都灵)
- Mantova(曼托瓦)
- Milano(米兰)
- Ravenna(拉文纳)
- Asti(阿斯蒂)
- Bologna(博洛尼亚)
- Piacenza(皮亚琴察)
- Cesena(切塞纳)
- Faenza(法恩莎)
实验过程
导入相关包开始实验
import numpy as np
import pandas as pd
import datetime如果你想用本章的数据,需要加载写作本章时保存的 10 个 CSV 文件。
df_ferrara = pd.read_csv('ferrara_270615.csv')
df_milano = pd.read_csv('milano_270615.csv')
df_mantova = pd.read_csv('mantova_270615.csv')
df_ravenna = pd.read_csv('ravenna_270615.csv')
df_torino = pd.read_csv('torino_270615.csv')
df_asti = pd.read_csv('asti_270615.csv')
df_bologna = pd.read_csv('bologna_270615.csv')
df_piacenza = pd.read_csv('piacenza_270615.csv')
df_cesena = pd.read_csv('cesena_270615.csv')
df_faenza = pd.read_csv('faenza_270615.csv')我们把这些数据读入内存,完成了实验准备的部分。
实验步骤
从数据可视化入手分析收集到的数据是常见的做法。前面讲过,matplotlib 库提供一系列图表生成工具,能够以可视化形式表示数据。数据可视化在数据分析阶段非常有助于发现研究系统的一些特点。
导入以下必要的库:
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from dateutil import parser温度数据分析
举例来说,非常简单的分析方法是先分析一天中气温的变化趋势。我们以城市米兰为例。
# 取出我们要分析的温度和日期数据
y1 = df_milano['temp']
x1 = df_milano['day']
# 把日期数据转换成 datetime 的格式
day_milano = [parser.parse(x) for x in x1]
# 调用 subplot 函数, fig 是图像对象,ax 是坐标轴对象
fig, ax = plt.subplots()
# 调整x轴坐标刻度,使其旋转70度,方便查看
plt.xticks(rotation=70)
# 设定时间的格式
hours = mdates.DateFormatter('%H:%M')
# 设定X轴显示的格式
ax.xaxis.set_major_formatter(hours)
# 画出图像,day_milano是X轴数据,y1是Y轴数据,‘r’代表的是'red' 红色
ax.plot(day_milano ,y1, 'r')
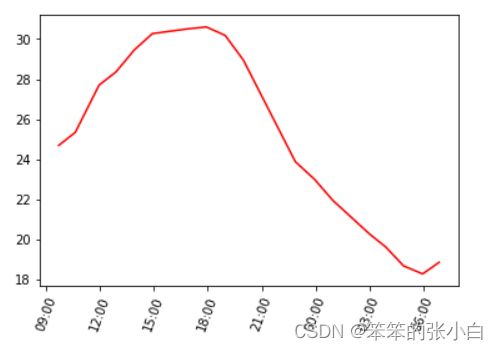
执行上述代码,将得到如图所示的图像。由图可见,气温走势接近正弦曲线,从早上开始气温逐渐升高,最高温出现在下午两点到六点之间,随后气温逐渐下降,在第二天早上六点时达到最低值。
我们进行数据分析的目的是尝试解释是否能够评估海洋是怎样影响气温的,以及是否能够影响气温趋势,因此我们同时来看几个不同城市的气温趋势。这是检验分析方向是否正确的唯一方式。因此,我们选择三个离海最近以及三个离海最远的城市。
# 读取温度和日期数据
y1 = df_ravenna['temp']
x1 = df_ravenna['day']
y2 = df_faenza['temp']
x2 = df_faenza['day']
y3 = df_cesena['temp']
x3 = df_cesena['day']
y4 = df_milano['temp']
x4 = df_milano['day']
y5 = df_asti['temp']
x5 = df_asti['day']
y6 = df_torino['temp']
x6 = df_torino['day']
# 把日期从 string 类型转化为标准的 datetime 类型
day_ravenna = [parser.parse(x) for x in x1]
day_faenza = [parser.parse(x) for x in x2]
day_cesena = [parser.parse(x) for x in x3]
day_milano = [parser.parse(x) for x in x4]
day_asti = [parser.parse(x) for x in x5]
day_torino = [parser.parse(x) for x in x6]
# 调用 subplots() 函数,重新定义 fig, ax 变量
fig, ax = plt.subplots()
plt.xticks(rotation=70)
hours = mdates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(hours)
#这里需要画出三根线,所以需要三组参数, 'g'代表'green'
ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')
ax.plot(day_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')

上述代码将生成如图 所示的图表。离海最近的三个城市的气温曲线使用红色,而离海最远的三个城市的曲线使用绿色。结果看起来不错。离海最近的三个城市的最高气温比离海最远的三个城市低不少,而最低气温看起来差别较小。
我们可以沿着这个方向做深入研究,收集 10 个城市的最高温和最低温,用线性图表示气温最值点和离海远近之间的关系。
# dist 是一个装城市距离海边距离的列表
dist = [df_ravenna['dist'][0],
df_cesena['dist'][0],
df_faenza['dist'][0],
df_ferrara['dist'][0],
df_bologna['dist'][0],
df_mantova['dist'][0],
df_piacenza['dist'][0],
df_milano['dist'][0],
df_asti['dist'][0],
df_torino['dist'][0]
]
# temp_max 是一个存放每个城市最高温度的列表
temp_max = [df_ravenna['temp'].max(),
df_cesena['temp'].max(),
df_faenza['temp'].max(),
df_ferrara['temp'].max(),
df_bologna['temp'].max(),
df_mantova['temp'].max(),
df_piacenza['temp'].max(),
df_milano['temp'].max(),
df_asti['temp'].max(),
df_torino['temp'].max()
]
# temp_min 是一个存放每个城市最低温度的列表
temp_min = [df_ravenna['temp'].min(),
df_cesena['temp'].min(),
df_faenza['temp'].min(),
df_ferrara['temp'].min(),
df_bologna['temp'].min(),
df_mantova['temp'].min(),
df_piacenza['temp'].min(),
df_milano['temp'].min(),
df_asti['temp'].min(),
df_torino['temp'].min()
]
先把最高温画出来。
fig, ax = plt.subplots()
ax.plot(dist,temp_max,'ro')
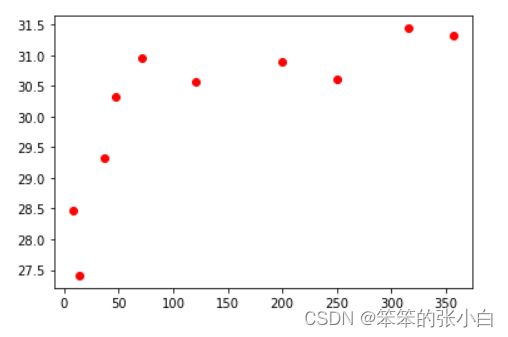
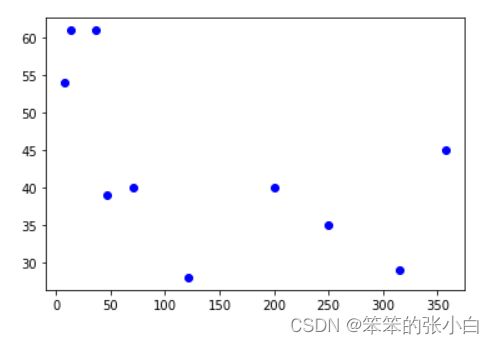
如图 所示,现在你可以证实,海洋对气象数据具有一定程度的影响这个假设是正确的(至少这一天如此)。进一步观察上图,你会发现海洋的影响衰减得很快,离海 60~70 公里开外,气温就已攀升到高位。
用线性回归算法得到两条直线,分别表示两种不同的气温趋势,这样做很有趣。我们可以使用 scikit-learn 库的 SVR 方法。
from sklearn.svm import SVR
# dist1是靠近海的城市集合,dist2是远离海洋的城市集合
dist1 = dist[0:5]
dist2 = dist[5:10]
# 改变列表的结构,dist1现在是5个列表的集合
# 之后我们会看到 nbumpy 中 reshape() 函数也有同样的作用
dist1 = [[x] for x in dist1]
dist2 = [[x] for x in dist2]
# temp_max1 是 dist1 中城市的对应最高温度
temp_max1 = temp_max[0:5]
# temp_max2 是 dist2 中城市的对应最高温度
temp_max2 = temp_max[5:10]
# 我们调用SVR函数,在参数中规定了使用线性的拟合函数
# 并且把 C 设为1000来尽量拟合数据(因为不需要精确预测不用担心过拟合)
svr_lin1 = SVR(kernel='linear', C=1e3)
svr_lin2 = SVR(kernel='linear', C=1e3)
# 加入数据,进行拟合
svr_lin1.fit(dist1, temp_max1)
svr_lin2.fit(dist2, temp_max2)
# 关于 reshape 函数请看代码后面的详细讨论
xp1 = np.arange(10,100,10).reshape((9,1))
xp2 = np.arange(50,400,50).reshape((7,1))
yp1 = svr_lin1.predict(xp1)
yp2 = svr_lin2.predict(xp2)
然后绘图
# 限制了 x 轴的取值范围
fig, ax = plt.subplots()
ax.set_xlim(0,400)
# 画出图像
ax.plot(xp1, yp1, c='b', label='Strong sea effect')
ax.plot(xp2, yp2, c='g', label='Light sea effect')
ax.plot(dist,temp_max,'ro')
这里 np.arange(10,100,10) 会返回 [10, 20, 30,..., 90],如果把列表看成是一个矩阵,那么这个矩阵是 1 9 的。这里 reshape((9,1)) 函数就会把该列表变为 9 1 的, [[10], [20], ..., [90]]。这么做的原因是因为 predict() 函数的只能接受一个 N 1 的列表,返回一个 1 N 的列表。
上述代码将生成如下图 所示的图像。
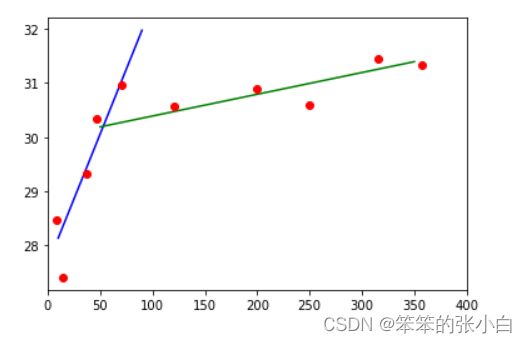
如上所见,离海 60 公里以内,气温上升速度很快,从 28 度陡升至 31 度,随后增速渐趋缓和(如果还继续增长的话),更长的距离才会有小幅上升。这两种趋势可分别用两条直线来表示,直线的表达式为:y=ax+by=ax+b 其中 a 为斜率,b 为截距。
你可能会考虑将这两条直线的交点作为受海洋影响和不受海洋影响的区域的分界点,或者至少是海洋影响较弱的分界点。
from scipy.optimize import fsolve
# 定义了第一条拟合直线
def line1(x):
a1 = svr_lin1.coef_[0][0]
b1 = svr_lin1.intercept_[0]
return a1*x + b1
# 定义了第二条拟合直线
def line2(x):
a2 = svr_lin2.coef_[0][0]
b2 = svr_lin2.intercept_[0]
return a2*x + b2
# 定义了找到两条直线的交点的 x 坐标的函数
def findIntersection(fun1,fun2,x0):
return fsolve(lambda x : fun1(x) - fun2(x),x0)
result = findIntersection(line1,line2,0.0)
print("[x,y] = [ %d , %d ]" % (result,line1(result)))
# x = [0,10,20, ..., 300]
x = np.linspace(0,300,31)
plt.plot(x,line1(x),x,line2(x),result,line1(result),'ro')
执行上述代码,将得到交点的坐标 [x,y]=[53,30][x,y]=[53,30] 并得到如图所示的图表。
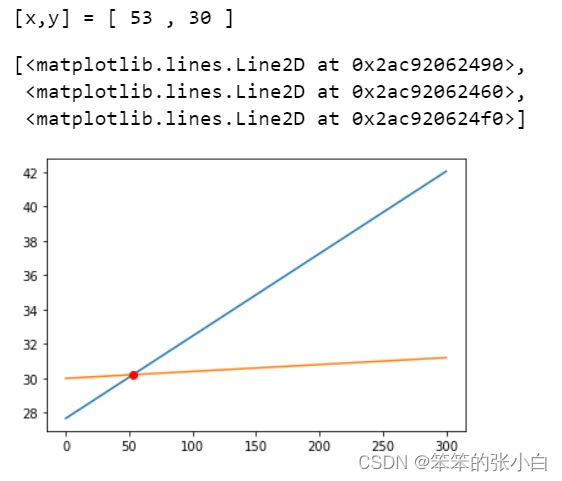
因此,你可以说海洋对气温产生影响的平均距离(该天的情况)为 53 公里。现在,我们可以转而分析最低气温。
# axis 函数规定了 x 轴和 y 轴的取值范围
plt.axis((0,400,15,25))
plt.plot(dist,temp_min,'bo')

在这个例子中,很明显夜间或早上 6 点左右的最低温与海洋无关。如果没记错的话,小时候老师教给大家的是海洋能够缓和低温,或者说夜间海洋释放白天吸收的热量。但是从我们得到情况来看并非如此。我们刚使用的是意大利夏天的气温数据,而验证该假设在冬天或其他地方是否也成立,将会非常有趣。
湿度数据分析
10 个 DataFrame 对象中还包含湿度这个气象数据。因此,你也可以考察当天三个近海城市和三个内陆城市的湿度趋势。
# 读取湿度数据
y1 = df_ravenna['humidity']
x1 = df_ravenna['day']
y2 = df_faenza['humidity']
x2 = df_faenza['day']
y3 = df_cesena['humidity']
x3 = df_cesena['day']
y4 = df_milano['humidity']
x4 = df_milano['day']
y5 = df_asti['humidity']
x5 = df_asti['day']
y6 = df_torino['humidity']
x6 = df_torino['day']
# 重新定义 fig 和 ax 变量
fig, ax = plt.subplots()
plt.xticks(rotation=70)
# 把时间从 string 类型转化为标准的 datetime 类型
day_ravenna = [parser.parse(x) for x in x1]
day_faenza = [parser.parse(x) for x in x2]
day_cesena = [parser.parse(x) for x in x3]
day_milano = [parser.parse(x) for x in x4]
day_asti = [parser.parse(x) for x in x5]
day_torino = [parser.parse(x) for x in x6]
# 规定时间的表示方式
hours = mdates.DateFormatter('%H:%M')
ax.xaxis.set_major_formatter(hours)
#表示在图上
ax.plot(day_ravenna,y1,'r',day_faenza,y2,'r',day_cesena,y3,'r')
ax.plot(day_milano,y4,'g',day_asti,y5,'g',day_torino,y6,'g')
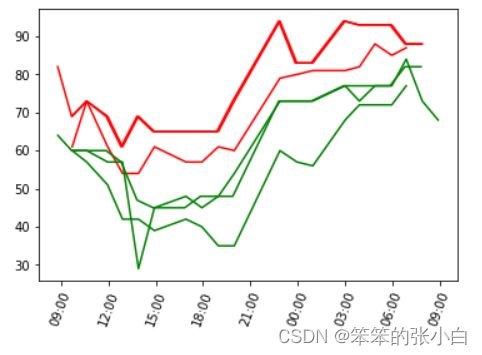 乍看上去好像近海城市的湿度要大于内陆城市,全天湿度差距在 20% 左右。我们再来看一下湿度的极值和离海远近之间的关系,是否跟我们的第一印象相符。
乍看上去好像近海城市的湿度要大于内陆城市,全天湿度差距在 20% 左右。我们再来看一下湿度的极值和离海远近之间的关系,是否跟我们的第一印象相符。
# 获取最大湿度数据
hum_max = [df_ravenna['humidity'].max(),
df_cesena['humidity'].max(),
df_faenza['humidity'].max(),
df_ferrara['humidity'].max(),
df_bologna['humidity'].max(),
df_mantova['humidity'].max(),
df_piacenza['humidity'].max(),
df_milano['humidity'].max(),
df_asti['humidity'].max(),
df_torino['humidity'].max()
]
plt.plot(dist,hum_max,'bo')
我们把 10 个城市的最大湿度与离海远近之间的关系做成图表

# 获取最小湿度
hum_min = [
df_ravenna['humidity'].min(),
df_cesena['humidity'].min(),
df_faenza['humidity'].min(),
df_ferrara['humidity'].min(),
df_bologna['humidity'].min(),
df_mantova['humidity'].min(),
df_piacenza['humidity'].min(),
df_milano['humidity'].min(),
df_asti['humidity'].min(),
df_torino['humidity'].min()
]
plt.plot(dist,hum_min,'bo')
再来把 10 个城市的最小湿度与离海远近之间的关系做成图表
由上两幅图可以确定,近海城市无论是最大还是最小湿度都要高于内陆城市。然而,在我看来,我们还不能说湿度和距离之间存在线性关系或者其他能用曲线表示的关系。我们采集的数据点数量(10)太少,不足以描述这类趋势。
风向频率玫瑰图
在我们采集的每个城市的气象数据中,下面两个与风有关:
- 风力(风向)
- 风速
分析存放每个城市气象数据的 DataFrame 就会发现,风速不仅跟一天的时间段相关联,还与一个介于 0~360 度的方向有关。
要表示呈 360 度分布的数据点,最好使用另一种可视化方法:极区图。
首先,创建一个直方图,也就是将 360 度分为八个面元,每个面元为 45 度,把所有的数据点分到这八个面元中。
df_ravenna[['wind_deg','wind_speed','day']]
hist, bins = np.histogram(df_ravenna['wind_deg'],8,[0,360])histogram() 函数返回结果中的数组 hist 为落在每个面元的数据点数量。[0 5 11 1 0 1 0 0]
返回结果中的数组 bins 定义了 360 度范围内各面元的边界。[0. 45. 90. 135. 180. 225. 270. 315. 360.]
要想正确定义极区图,离不开这两个数组。我们将创建一个函数来绘制极区图,其中部分代码在第 7 章已讲过。我们把这个函数定义为 showRoseWind(),它有三个参数:values 数组,指的是想为其作图的数据,也就是这里的 hist 数组;第二个参数 city_name 为字符串类型,指定图表标题所用的城市名称;最后一个参数 max_value 为整型,指定最大的蓝色值。
定义这样一个函数很有用,它既能避免多次重复编写相同的代码,还能增强代码的模块化程度,便于你把精力放到与函数内部操作相关的概念上。
def showRoseWind(values,city_name,max_value):
N = 8
# theta = [pi*1/4, pi*2/4, pi*3/4, ..., pi*2]
theta = np.arange(2 * np.pi / 16, 2 * np.pi, 2 * np.pi / 8)
radii = np.array(values)
# 绘制极区图的坐标系
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
# 列表中包含的是每一个扇区的 rgb 值,x越大,对应的color越接近蓝色
colors = [(1-x/max_value, 1-x/max_value, 0.75) for x in radii]
# 画出每个扇区
plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
# 设置极区图的标题
plt.title(city_name, x=0.2, fontsize=20)
你需要修改变量 colors 存储的颜色表。这里,扇形的颜色越接近蓝色,值越大。定义好函数之后,调用它即可:
showRoseWind(hist,'Ravenna',max(hist))
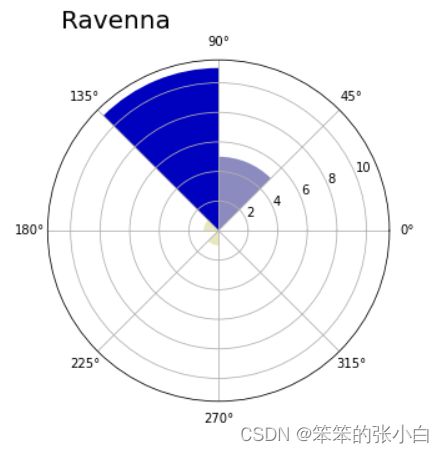
由图可见,整个 360 度的范围被分成八个区域(面元),每个区域弧长为 45 度,此外每个区域还有一列呈放射状排列的刻度值。在每个区域中,用半径长度可以改变的扇形表示一个数值,半径越长,扇形所表示的数值就越大。为了增强图表的可读性,我们使用与扇形半径相对应的颜色表。半径越长,扇形跨度越大,颜色越接近于深蓝色。
从刚得到的极区图可以得知风向在极坐标系中的分布方式。该图表示这一天大部分时间风都吹向西南和正西方向。定义好 showRoseWind() 函数之后,查看其他城市的风向情况也非常简单。
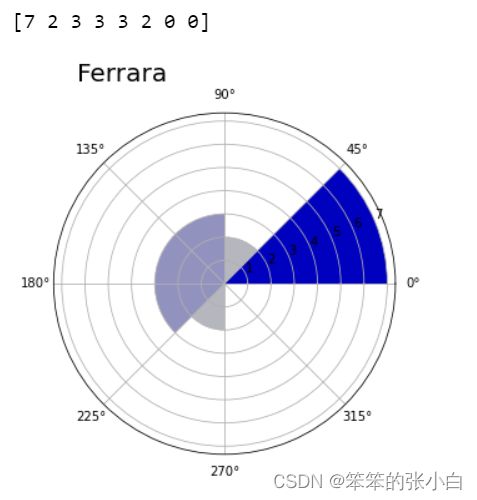
hist, bin = np.histogram(df_ferrara['wind_deg'],8,[0,360])
print(hist)
showRoseWind(hist,'Ferrara', max(hist))
实验总结
本实验主要目的是演示如何从原始数据获取信息。其中有些信息无法给出重要结论,而有些信息能够验证假设,增加我们对系统状态的认识,而找出这种信息也就意味着数据分析取得了成功。