C++11 lambda表达式
前言
lambda表达式是C++11或者更新版本的一个语法糖,本身不是C++开发的。但是因其便利,很值得我们学习和使用。lambda有很多叫法,有lambda表达式、lambda函数、匿名函数,本文中为了方便表述统一用lambda表达式进行叙述。

文章目录
- 前言
- 一. 引子
- 二. lambda表达式的语法
- 三. lambda表达式的使用
- 四. lambda表达式和线程的结合
- 五. lambda表达式的原理
- 结束语
一. 引子
在C++中,为了实现泛型编程,在一个类中,我们难免遇到比较,排序的需求。而对于自定义类,编译器并不知道如何比较,所以需要我们自己提供比较方法。仿函数,就是一个很好的方法。
使用场景如下:
我们定义一个商品类,成员属性有商品名,商品价格,商品评级。
我们使用vector存储商品,用sort排序,并且排序规则依赖我们提供的仿函数
#include运行结果如下:

这样就完成需求了。
但是使用仿函数有一些缺点
- 每一次不同规则的比较,都需要实现一个仿函数类,
代码较为的冗余。 - 不同的人对于仿函数的命名不同,查看时较为繁琐和不易理解。而且当仿函数数量变多时,
仿函数的命名也是一个问题。
lambda表达式应运而生。
二. lambda表达式的语法
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type
{
statement
}
lambda表达式也就lambda函数,部分结构同普通函数
接下来我们进行一些讲解:
- [capture-list] :
捕捉列表,该列表总是出现lambda表达式的开始位置,编译器根据[]来判断接下来的代码是否为lambda表达式。捕捉列表能够捕捉上下文中的变量供lambda表达式使用。 - (parameters) :
参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略。 - mutable:修饰符。中文翻译为可变的。默认情况下,lambda表达式是一个const函数,mutable可以取消其常量性。如果使用了mutable,即使不需要参数传递,()也不能省略
- ->returntype :
返回值类型。用追踪返回值类型形式声明函数的返回值类型,没有返回值时此部分可以省略。返回值类型明确时,即函数体有确定的返回值类型,也可以省略,由编译器自行推导。 - {statement} :
函数体。我们在该部分编写lambda表达式的功能,除了可以使用其参数列表的参数,如果捕捉列表有捕捉参数,同样可以使用捕捉列表的参数
注意:在lambda表达式中,参数列表,mutable和返回值类型都是可选部分,捕捉列表和函数体可以为空,但不能省略。C++11最简单的lambda表达式为[]{}。但该lambda表达式没有意义。
三. lambda表达式的使用
基本用法
我们先编写一个简单的加法的lambda表达式
int main()
{
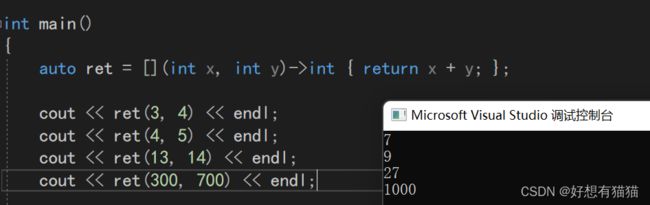
auto ret = [](int x, int y)->int { return x + y; };
cout << ret(3, 4) << endl;
cout << ret(4, 5) << endl;
cout << ret(13, 14) << endl;
cout << ret(300, 700) << endl;
return 0;
}
lambda表达式的返回值其实是一个类,这个我们在原理部分讲解。
ret接收lambda表达式的返回值,也就是类,然后传参使用lambda表达式功能
同时,因为我们在函数体内部明确了返回值类型,所以我们可以省略返回值

但是建议还是加上返回值,可读性更好一些
再比如,我们在引子中使用的仿函数,也可以使用lambda表达式进行替换。
代码如下:
void test2()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
//降序
auto priceDescending = [](Goods&g1, Goods&g2)->bool {return g1._price > g2._price; };
//升序
auto priceAscending = [](Goods&g1, Goods&g2)->bool {return g1._price < g2._price; };
cout << "初始顺序:" << endl;
for (auto& e : v)
{
cout << "商品名:" << e._name << " 价格:" << e._price << setprecision(2) << " 评级:" << e._evaluate << endl;
}
cout << "升序顺序:" << endl;
//升序排序
sort(v.begin(), v.end(), priceAscending);
for (auto& e : v)
{
cout << "商品名:" << e._name << " 价格:" << e._price << setprecision(2) << " 评级:" << e._evaluate << endl;
}
cout << "降序顺序:" << endl;
//降序排序
sort(v.begin(), v.end(), priceDescending);
for (auto& e : v)
{
cout << "商品名:" << e._name << " 价格:" << e._price << setprecision(2) << " 评级:" << e._evaluate << endl;
}
}
运行结果如下:

也可以直接将lambda表达式写在sort的仿函数位置
//升序排序
//sort(v.begin(), v.end(), priceAscending);
sort(v.begin(), v.end(), [](Goods&g1, Goods&g2)->bool {return g1._price < g2._price; });
//降序排序
//sort(v.begin(), v.end(), priceDescending);
sort(v.begin(), v.end(), [](Goods&g1, Goods&g2)->bool {return g1._price > g2._price; });
效果是一样的
捕捉列表
接下来,我们介绍一下捕捉列表的使用
我们编写一个交换的lambda表达式讲解
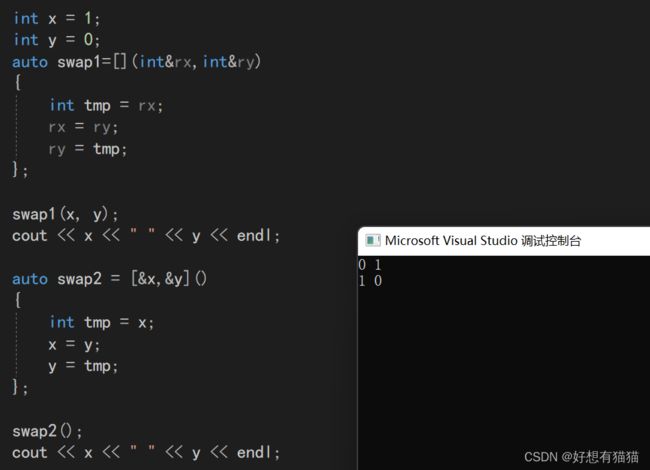
void test3()
{
int x = 1;
int y = 0;
auto swap1=[](int&rx,int&ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
};
swap1(x,y);
cout << x << " " << y << endl;
}
很简单。
我们也可以使用捕捉列表完成上述需求。
正如我们在第二部分lambda表达式的语法中所讲:捕捉列表能够捕捉上下文中的变量供lambda表达式使用。我们就可以捕捉x和y直接使用。
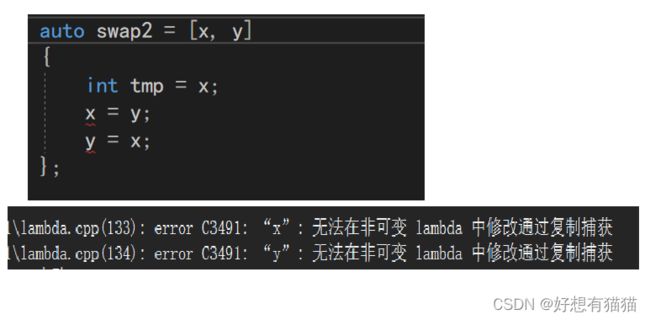
但是,此时是无法修改的。这是因为,默认情况下,lambda表达式是一个const函数,传值捕捉默认是有常性的。
这时可以使用mutable取消这一常性。
注意:当没有参数时,()可以省略,但是如果使用matable,即使没有参数,()也不能省略

但是这样其实是没有完成需求的。捕捉列表也分为传值捕捉和引用捕捉,上述是传值捕捉,并不会修改外面的x和y。
引用捕捉如下:
auto swap2 = [&x,&y]()
{
int tmp = x;
x = y;
y = tmp;
};
全捕捉
如果有很多参数,捕捉列表还提供全捕捉,同样分为引用捕捉和传值捕捉
//全部引用捕捉
auto func1 = [&](){};
//全部传值捕捉
auto func2 = [=](){};
混合捕捉
如果方式不同,捕捉列表也提供混合捕捉
//混合捕捉:x引用捕捉,y传值捕捉
auto func3 = [&x, y](){};
//混合捕捉:其他参数引用捕捉,x传值捕捉
auto func4 = [&,x](){};
//混合捕捉:其他参数传值捕捉,x引用捕捉
auto func5 = [=, &x](){};
四. lambda表达式和线程的结合
lambda表达式还可以和线程组合使用
如下是线程类

我们主要关注红框框的构造函数。
首先,线程的使用是需要可调用对象的,Fn&& fn就是接收可调用对象的。
而函数,仿函数,lambda表达式都是可调用对象。
如果使用函数,线程可以如下操作:

同样也可以使用lambda表达式
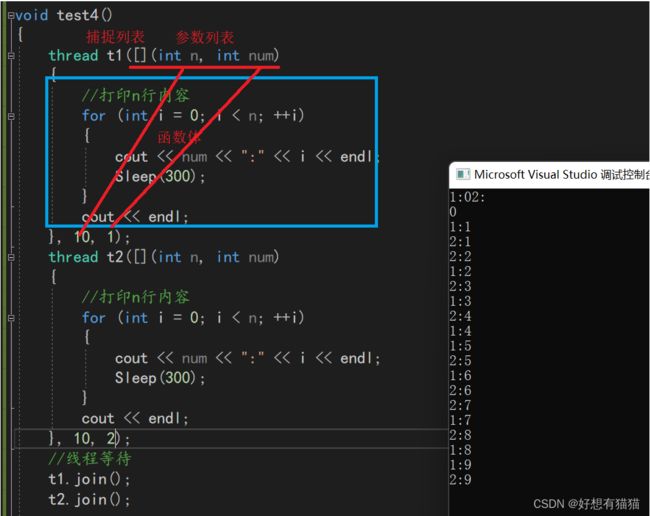
但是这样代码较为冗余,我们可以使用类似线程池的方法
void test5()
{
int m = 0, n = 0;
//m个线程,每个线程打印n次
cin >> m >> n;
//将thread保存在vector中
vector<thread>vthed(m);
for (int i = 0; i < m; ++i)
{
//移动赋值
//可执行对象使用lambda表达式
vthed[i] = thread([](int n, int num)
{
//打印n行内容
for (int j =0 ; j < n; ++j)
{
cout << num << ":" << j << endl;
Sleep(300);
}
cout << endl;
}, n, i);
}
for (int i = 0; i < m; ++i)
{
vthed[i].join();
}
}

线程是不允许有拷贝构造的,但是有移动赋值,以上代码就是使用了移动赋值。
五. lambda表达式的原理
接下来,我们就来研究底层lambda表达式是如何实现的。
其实,在编译器的角度,lambda表达式会被转换成一个仿函数。
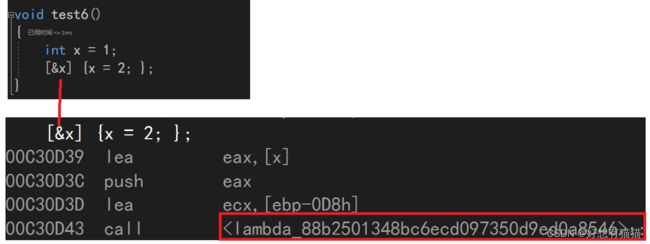
该仿函数的命名是lambda_uuid。
uuid是由一组32个的16进制数字组成的。通过一套算法生成绝不重复的uuid。用来进行唯一标识。
所以lambda表达式之间是不同的,因为uudi不同,不能进行赋值。
lambda表达式的大小
lambda表达式的大小分为三种情况
无捕捉
如果lambda表达式没有捕捉参数。
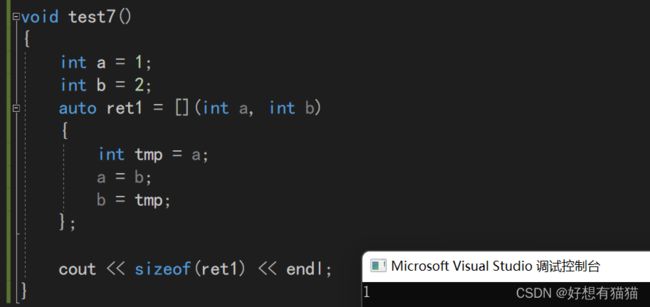
那lambda表达式就和仿函数一样,没有参数,所以大小为1
全捕捉
全捕捉并不会为所有捕捉的参数都开辟空间,而是哪些变量使用了,才为哪些变量开辟空间。
传值捕捉
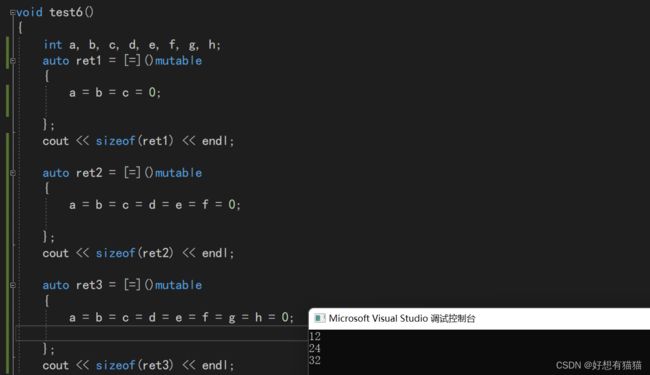
引用捕捉
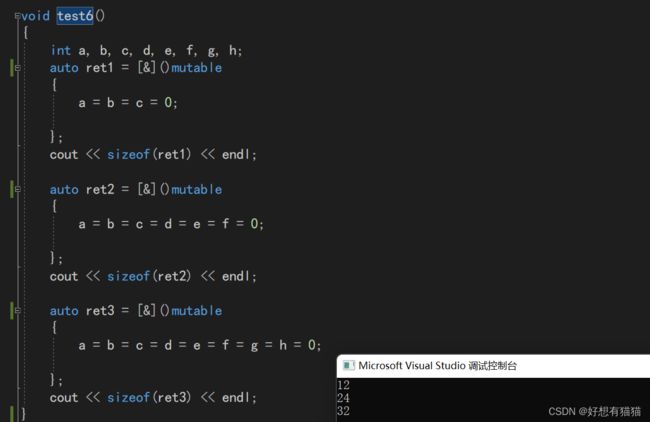
混合捕捉
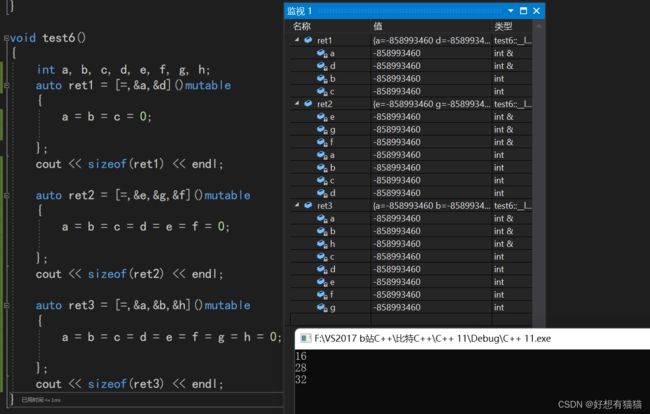
混合捕捉的规则有所不同:函数体使用了的+单独捕捉的,都会开空间。
全引用捕捉,个别传值捕捉
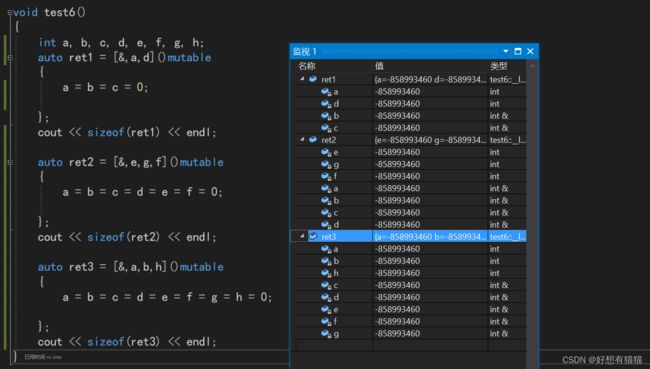
全传值捕捉,个别引用捕捉
结束语
感谢你的阅读
如果觉得本篇文章对你有所帮助的话,不妨点个赞支持一下博主,拜托啦,这对我真的很重要。
