数据科学在文本分析中的应用 :中英文 NLP(上)
在《后疫情时代,数据科学赋能旅游行业服务质量提升》这篇博文中,我们介绍了猫途鹰文本分析项目的背景和解决方案,并展示了最终的分析结果。接下来,对于中英文 NLP 感兴趣的读者,我们会为大家详细讲解数据采集、数据入库、数据清理和数据建模步骤中涉及的原理和代码实现。由于篇幅的限制,上篇会重点讲解数据采集、数据入库和数据清理这三个步骤,下篇则会讲解数据建模的完整流程。
数据采集
1. 抓取工具分析
网页内容抓取是从互联网上获取数据的方式之一。对于使用 Python 进行网页抓取的开发者,比较主流的工具有以下几种:
Beautiful Soup
Beautiful Soup 是几种工具中最容易上手的网页抓取库,它可以快速帮助开发者从 HTML 或 XML 格式的文件中获取数据。在这个过程中,Beautiful Soup 会一定程度上读取这类文件的数据结构,并在此基础上提供许多与查找和获取数据内容相关的方程。除此之外,Beautiful Soup 完善、易于理解的文档和活跃的社区使得开发者不仅可以快速上手,也能快速精通,并灵活运用于开发者自己的应用当中。
不过正因为这些工作特性,相较于其他库而言,Beautiful Soup也有比较明显的缺陷。首先,Beautiful Soup 需要依赖其他 Python库(如 Requests)才能向对象服务器发送请求,实现网页内容的抓取;也需要依赖其他 Python 解析器(如 html.parser)来解析抓取的内容。其次,由于Beautiful Soup需要提前读取和理解整个文件的数据框架以便之后内容的查找,从文件读取速度的角度来看,Beautiful Soup 相对较慢。在许多网页信息抓取的过程中,需要的信息可能只占一小部分,这样的读取步骤并不是必需的。
Scrapy
Scrapy 是非常受欢迎的开源网页抓取库之一,它最突出的特性是抓取速度快,又因为它基于 Twisted 异步网络框架,用户发送的请求是以无阻塞机制发送给服务器的,比阻塞机制更灵活,也更节省资源。因此,Scrapy 拥有了以下这些特性:
- 对于 HTML 类型网页,使用XPath或者CSS表述获取数据的支持
- 可运行于多种环境,不仅仅局限于 Python。Linux、Windows、Mac 等系统都可以使用 Scrapy 库。
- 扩展性强
- 速度和效率较高
- 需要的内存、CPU 资源较少
纵然 Scrapy 是功能强大的网页抓取库,也有相关的社区支持,但生涩难懂的文档使许多开发者望而却步,上手比较难。
Selenium
Selenium 的起源是为了测试网页应用程序而开发的,它获取网页内容的方式与其他库截然不同。Selenium 在结构设计上是通过自动化网页操作来获取网页返回的结果,和 Java 的兼容性很好,也可以轻松应对 AJAX 和 PJAX 请求。和 Beautiful Soup 相似,Selenium 的上手相对简单,但与其他库相比,它最大的优势是可以处理在网页抓取过程中出现的需要文本输入才能获取信息、或者是弹出页面等这种需要用户在浏览器中有介入动作的情况。这样的特性使得开发者对网页抓取的步骤更加灵活,Selenium 也因此成为了最流行的网页抓取库之一。
由于在获取景点评论的过程中需要应对搜索栏输入、弹出页面和翻页等情况,在本项目中,我们会使用 Selenium 进行网页文本数据的抓取。
2. 网页数据和结构的初步了解
各个网站在开发的过程中都有自己独特的结构和逻辑。同样是基于 HTML 的网页,即使 UI 相同,背后的层级关系都可能大相径庭。这意味着理清网页抓取的逻辑不仅要了解目标网页的特性,也要对未来同一个网址的更新换代、同类型其他平台的网页特性有所了解,通过比较相似的部分整理出一个相对灵活的抓取逻辑。
猫途鹰国际版网站的网页抓取步骤与中文版网站的步骤相似,这里我们以 www.tripadvisor.cn 为例,先观察一下从首页到景点评论的大致步骤。
步骤一:进入首页,在搜索栏中输入想要搜索的景点名称并回车
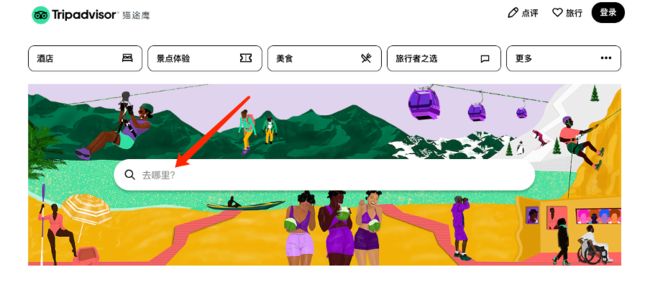
步骤二:页面更新,出现景点列表,选择目标景点
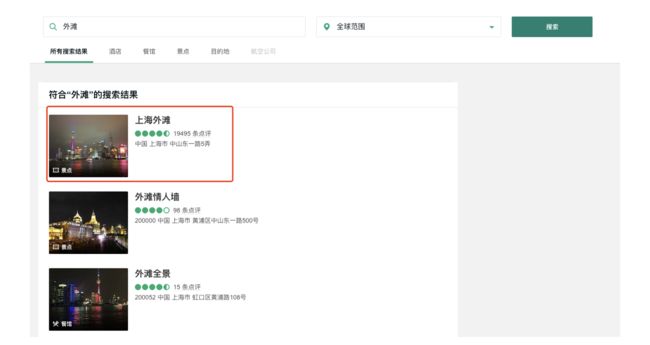
在搜索景点名称后,我们需要在图中所示的列表里锁定目标景点。这里可以有两层逻辑叠加帮助我们达到这个目的:
- 猫途鹰的搜索引擎本身会对景点名称和搜索输入进行比较,通过自己内部的逻辑将符合条件的景点排名靠前
- 我们可以在结果出现后使用省份、城市等信息筛选得到目标景点
步骤三:点击目标景点,弹出新页面,切换至该页面并寻找相关评论
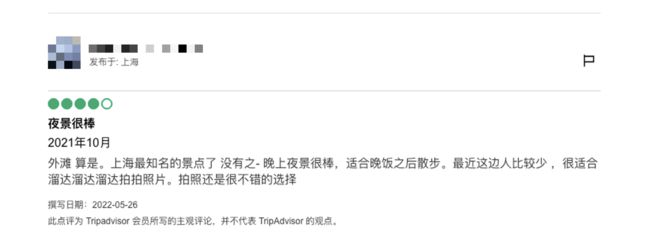
根据评论格式的特点,我们可以抓取的信息如下:
- 用户
- 用户所在地
- 评分
- 点评标题
- 到访日期
- 旅行类型
- 详细点评
- 撰写日期
步骤四:翻页获取更多评论
可以看到,在获取相关网页的过程中有许多需要浏览器去完成的动作,这也是我们选择 Selenium 的原因。因此,我们的网页抓取程序会在数据抓取之前,进行相同的步骤。
开发网页抓取程序时一个非常便利的定位所需内容在 HTML 代码中位置的方法是,在浏览器中将鼠标移至内容所在的区域,右键选择 “Inspect”,浏览器会弹出网页 HTML 元素并定位到和内容相关的代码。基于这种方法,我们可以使用 Selenium 进行自动化操作和数据抓取。
以上述评论为例,它在 HTML 结构中的位置如下:

在使用 Selenium 时,元素类别和 class 名称可以帮助我们定位到相关内容,进行进一步操作,抓取相关文本数据。我们可以使用这两种定位方法:CSS 或 XPATH,开发者可以根据自身需求进行选择。最终,我们执行的网页抓取程序大致可以分成两个步骤:
- 第一步:发送请求,使用 Selenium 操作浏览器找到指定景点的评论页面
- 第二步:进入评论页面,抓取评论数据
3. 获取评论数据
这部分的功能实现需要先安装和导入以下 Python 库:
from selenium import webdriver
import chromedriver_binary
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import datetime
import re
import pandas as pd
from utility import print_log_message, read_from_config其中,utility 是一个辅助模块,包含打印会话和发生时间的方程,以及从 ini 设置文件中读取程序信息的方程。utility 中的辅助方程可以反复出现在需要的模块中。
#utility.py
import time
import configparser
def print_log_message(app_name, procedure, message):
ts = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S", ts) + " **" + app_name + "** " + procedure + ":", message)
return
def read_from_config(file_name, section, var):
config = configparser.ConfigParser()
config.read(file_name)
var_value = config.get(section, var)
return var_value在开始网页抓取之前,我们需要先启动一个网页会话进程。
# Initiate web session
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--window-size=1920,1080')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome(ChromeDriverManager().install(),chrome_options=chrome_options)
wd.get(self.web_url)
wd.implicitly_wait(5)
review_results = {}考虑到运行环境不是 PC 或资源充足的实例,我们需要在代码中说明程序没有显示方面的需求。ChromeDriverManager() 可以帮助程序在没有 Chrome 驱动的环境中下载需要的驱动文件,并传递给 Selenium 的会话进程。
注意,许多网页内容与 Chrome 版本、资源和系统环境、时间有关。本项目中使用的网页并不受这类信息或环境的影响,但会受浏览器显示设置的限制,进而影响被抓取的内容。请大家在开发此类抓取程序时,注意核对网页显示信息与实际抓取数据是否吻合。
进入猫途鹰主页(https://www.tripadvisor.cn/)后,在搜索栏输入目标景点名称并回车,进入新页面后,在景点列表里根据搜索引擎排序、省份和城市,寻找并点击进入正确的景点页面。这里,我们以“外滩”为例:
location_name = '外滩'
city = '上海'
state = '上海'# Find search box
wd.find_element(By.CSS_SELECTOR, '.weiIG.Z0.Wh.fRhqZ>div>form>input').click()# Enter location name
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(f'{location_name}')
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(Keys.ENTER)# Find the right location with city + province info
element = wd.find_element(By.XPATH,
f'//*[@class="address-text" and contains(text(), "{city}") and contains(text(), "{state}")]')
element.click()在点击目标景点后,切换至跳转出的新页面。进入景点评论页面之后,我们就可以根据页面 HTML 的结构和评论在其代码层级中的位置将所需信息抓取下来。Selenium 在寻找某一个元素时,会在整个网页框架中寻找相关信息,并不能像其他一些网页抓取库一样锁定某一个部分并只在该部分中寻找想要的元素。因此,我们需要将一类信息统一抓取出来,然后剔除一些不需要的信息。这一过程需要反复核对真实网页上显示的信息,以防将不需要的内容抓取出来,影响数据质量。
抓取使用的代码如下:
comment_section = wd.find_element(By.XPATH, '//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]')# user id
user_elements = comment_section.find_elements(By.XPATH, '//div[@class="ffbzW _c"]/div/div/div/span[@class="WlYyy cPsXC dTqpp"]')
user_list = [x.text for x in user_elements]对于英文评论数据的抓取,除了网页框架有一些区别以外,关于地点的数据要更复杂一些,需要进一步的处理。我们在抓取的过程中,默认逗号为分隔符,逗号前的值为城市,逗号后的值为国家地区。
# location
loca_elements = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div/div/div/div/div[@class="WlYyy diXIH bQCoY"]')
loca_list = [x.text[5:] for x in loca_elements]# trip type
trips_element = comment_section.find_elements(By.XPATH, '//*[@class="eRduX"]')
trip_types = [self.separate_trip_type(x.text) for x in trips_element]注意,由于评价时间的定位相对困难,文本 class 类别会包含网页景点介绍的信息,我们需要把这部分不需要的数据剔除。
# comment date
comments_date_element = comment_section.find_elements(By.CSS_SELECTOR, '.WlYyy.diXIH.cspKb.bQCoY')# drop out the first element
comments_date_element.pop(0)
comments_date = [x.text[5:] for x in comments_date_element]由于用户评分并非文本,我们需要从 HTML 的结构中找到代表它的元素,以此来计算星级多少。在猫途鹰的网页 HTML 中,代表星级的元素是 “bubble”,我们需要在 HTML 结构中找到相关的代码,将代码中的星级数据提取出来。
# rating
rating_element = comment_section.find_elements(By.XPATH,
'//div[@class="dHjBB"]/div/span/div/div[@style="display: block;"]')
rating_list = []
for rating_code in rating_element:
code_string = rating_code.get_attribute('innerHTML')
s_ind = code_string.find(" bubble_")
rating_score = code_string[s_ind + len(" bubble_"):s_ind + len(" bubble_") + 1]
rating_list.append(rating_score)# comments title
comments_title_elements = comment_section.find_elements(By.XPATH,
'//*[@class="WlYyy cPsXC bLFSo cspKb dTqpp"]')
comments_title = [x.text for x in comments_title_elements]# comments content
comments_content_elements = wd.find_element(By.XPATH,
'//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]'
).find_elements(By.XPATH, '//*[@class="duhwe _T bOlcm dMbup "]')
comments_content = [x.text for x in comments_content_elements]在评论中查找图片和寻找星级的逻辑一样,先要在 HTML 结构中找到代表图片的部分,然后在代码中确认评论中是否包含图片信息。
# if review contains pictures
pic_sections = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div[@class="hotels-community-tab-common-Card__card--ihfZB hotels-community-tab-common-Card__section--4r93H comment-item"]')
pic_list = []
for r in pic_sections:
if 'background-image' in r.get_attribute('innerHTML'):
pic_list.append(1)
else:
pic_list.append(0)综上所述,我们可以将评论数据按照输入景点名和所需评论页数从猫途鹰网站抓取下来并进行整合,最终保存为一个 Pandas DataFrame。
整个过程可以实现自动化,打包成一个名为 data_processor 的 .py 格式文件。如需获取评论数据,我们只需运行以下方程,即可获得 Pandas DataFrame 格式的景点评论信息。
#引入之前定义的Python Class:
from data_processor import WebScrapper
scrapper = WebScrapper()#运行网页抓取方程抓取中文语料:
trip_review_data = scrapper.trip_advisor_zh_scrapper_runner(location, location_city, location_state, page_n=int(n_pages))其中 location 代表景点名称,location_city 和 location_state 代表景点所在的城市和省份,page_n 代表需要抓取的页数。
数据入库
在得到抓取的评论数据后,我们可以将数据存进数据库,以便数据分享,进行下一步的分析和建模。以 PieCloudDB Database 为例,我们可以使用 Python 的 Postgres SQL 驱动与 PieCloudDB 进行连接。
本项目实现数据入库的方式是,在获取了评论数据并整合为 Pandas DataFrame 后,我们将借助 SQLAlchemy 引擎将 Pandas 数据通过 psycopg2 上传至数据库。首先,我们需要定义连接数据库的引擎:
from sqlalchemy import create_engine
import psycopg2
engine = create_engine('postgresql+psycopg2://user_name:password@db_ip:port /database')其中 postgresql + psycopg2 是我们在连接数据库时需要使用的驱动,user_name 是数据库用户名,password 是对应的登陆密码,db_ip 为数据库 ip 或 endpoint,port 为数据库外部连接接口,database 是数据库名称。
将引擎传递给 Pandas 后,我们就可以轻松地将 Pandas DataFrame 上传至数据库,完成入库操作。
data.to_sql(table_name, engine, if_exists=‘replace’, index=False)data 是我们需要入库的 Pandas DataFrame 数据,table_name 是表名,engine 是我们之前定义的 SQLAlchemy 引擎, if_exists=‘replace’ 和 index=False 则是 Pandas to_sql() 方程的选项。这里选项的含义是,如果表已存在则用现有数据替代已有数据,并且在入库过程中,我们不需要考虑索引。
数据清洗
在这个步骤中,我们会根据原数据的特性对评论数据进行清理,为后续的建模做准备。抓取下来的评论数据包含以下三种类别的信息:
- 用户信息(如所在地等)
- 评论信息(如是否包含图片信息等)
- 评论语料
在正式进入这个步骤前,我们需要导入以下代码库,其中部分代码库会在数据建模步骤使用:
import numpy as np
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
import langid
import re
import emoji
from sklearn.preprocessing import MultiLabelBinarizer
import demoji
import random
from random import sample
import itertools
from collections import Counter
import matplotlib.pyplot as plt用户信息与评论信息的运用主要在 BI 部分体现,建模部分主要依靠评论语料数据。我们需要根据评论语言采取合适的清理、分词和建模方法。首先,我们从数据库中调取数据,通过以下代码可以实现。
中文评论数据:
df = pd.read_sql('SELECT * FROM "上海_上海_外滩_source_review"', engine)
df.shape![]()
英文评论数据:
df = pd.read_sql('SELECT * FROM "Shanghai_Shanghai_The Bund (Wai Tan)_source_review_EN"', engine)
df.shape![]()
我们在中文版网站抓取了171页评论,每页有10个评论,合计1710条评论;在国际版网站抓取了200页评论,合计2000条评论。
1. 数据类型处理
由于写入数据库的数据都是字符串类型,我们需要先对每一列数据的数据类型进行校对和转换。在中文评论数据中,需要转换的变量是评论时间和评分。
df['comment_date'] = pd.to_datetime(df['comment_date'])
df['rating'] = df['rating'].astype(str)
df['comment_year'] = df['comment_date'].dt.year
df['comment_month'] = df['comment_date'].dt.month2. 了解数据状况
在处理空值和转换数据之前,我们可以大致浏览一下数据,对空值状况有一个初步的了解。
df.isnull().sum()中文评论数据的空值大致情况如下:
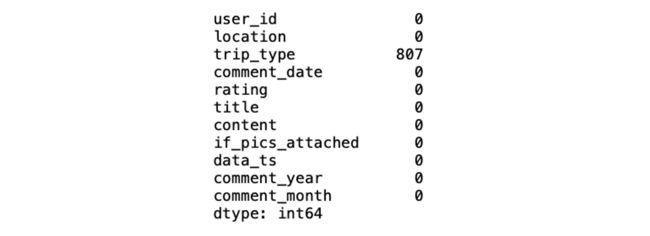
与中文评论数据不同的是,英文评论数据中需要处理的空白数据要多一些,主要集中在用户所在地和旅行类型两个变量当中。
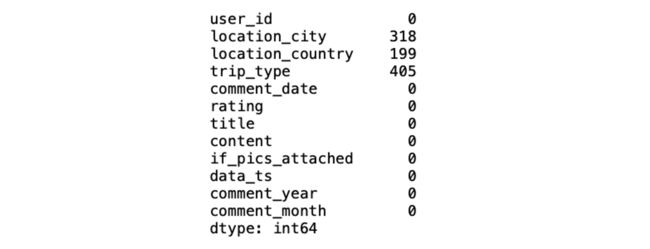
3. 处理旅行类型空值
对于存在空值的变量,我们可以通过对变量各类别的统计来大致了解其特性。以旅行类型(trip_type)为例,该变量有6种类型,其中一种是用户未表明的旅行类型,这类数据都以空值形式存在:
df.groupby(['trip_type']).size()
因为旅行类型是分类变量,在本项目的情况下,我们用类别“未知”或“NA”填充空值。
中文评论数据:
df['trip_type'] = df['trip_type'].fillna('未知')英文评论数据:
df['trip_type'] = df['trip_type'].fillna('NA')在中文评论的文本分析中,旅行类型分为以下六种,与英文是对应的关系:全家游、商务行、情侣游、独自旅行、结伴旅行、未知。为了方便之后的分析,我们需要建立一个查询表,将两种语言的旅行类型对应起来。
zh_trip_type = ['全家游', '商务行', '情侣游', '独自旅行', '结伴旅行', '未知']
en_trip_type = ['Family', 'Business', 'Couples', 'Solo', 'Friends', 'NA']
trip_type_df = pd.DataFrame({'zh_type':zh_trip_type, 'en_type':en_trip_type})然后将该表写进数据库,以便后续的可视化分析。
trip_type_df.to_sql("tripadvisor_TripType_lookup", engine, if_exists="replace", index=False)4. 处理英文评论数据中用户所在地信息
在英文评论数据中,由于用户所在地为用户自行填充的信息,地区数据非常混乱,并非按照某一个顺序或者逻辑来填充。城市和国家字段不仅需要处理空值,还需要校正。在抓取数据时,我们抓取地区信息的逻辑为:
- 如果地区信息用逗号隔开,前一个词为城市,后一个词为国家/省份
- 如果没有逗号,则默认该信息为国家信息
对于国际版网站的评论分析,我们选择细分用户所在地到国家层级。注意,由于很多用户有拼写错误或填写虚假地名的问题,我们的目标是尽可能地在力所能及的范围内修正信息,如校正大小写、缩写、对应城市信息等。这里,我们的具体解决方法是:
- 将缩写的国家/省份提取出来并单独处理(以美国为主,用户在填写地区信息时只填写州名)
- 查看除缩写以外的国家信息,如国家名称未出现在国家列表里,则认为是城市信息
- 国家字段中出现的城市名错填(如大型城市)和拼写错误问题,则手动修改处理
注意,本项目中使用的国家、地区名参考自 国家名称信息来源 和 美国各州及其缩写来源。
首先,我们从文件系统中读取国家信息:
country_file = open("countries.txt", "r")
country_data = country_file.read()
country_list = country_data.split("\n")
countries_lower = [x.lower() for x in country_list]
读取美国州名及其缩写信息:
state_code = pd.read_csv("state_code_lookup.csv")下列方程可以读取一个国家名字符串,并判断是否需要清理和修改:
def formating_country_info(s_input):
if s_input is None: #若字符串输入为空值,返回空值
return None
if s_input.strip().lower() in countries_lower: #若字符串输入在国家列表中,返回国家名
c_index = countries_lower.index(s_input.strip().lower())
return country_list[c_index]
else:
if len(s_input) == 2: #若输入为缩写,在美国州名、墨西哥省名和英国缩写中查找,若可以找到,返回对应国家名称
if s_input.strip().upper() in state_code["code"].to_list():
return "United States"
elif s_input.strip().upper() == "UK":
return "United Kingdom"
elif s_input.strip().upper() in ("RJ", "GO", "CE"):
return "Mexico"
elif s_input.strip().upper() in ("SP", "SG"):
return "Singapore"
else:
# could not detect country info
return None
else: #其他情况,需要手动修改国家名称
if s_input.strip().lower() == "caior":
return "Egypt"
else:
return None拥有了清理单个值的方程后,我们可以通过 .apply() 函数将该方程应用至 Pandas DataFrame 中代表国家信息的列中。
df["location_country"] = df["location_country"].apply(formating_country_info)然后,检查一下清理后的结果:
df["location_country"].isnull().sum()![]()
我们注意到空值的数量有所增加,除了修正部分数据以外,对于一些不存在的地名,以上方程会将其转换为空值。接下来,我们来处理城市信息,并将可能被分类为城市的国家信息补充至国家变量中。我们可以根据国家的名称筛选可能错位的信息,将这类信息作为国家信息的填充,剩下的默认为城市名称。
def check_if_country_info(city_list):
clean_list = []
country_fill_list = []
for city in city_list:
if city is None:
clean_list.append(None)
country_fill_list.append(None)
elif city.strip().lower() in countries_lower: #如城市变量中出现的是国家名,记录国家名称
c_index = countries_lower.index(city.strip().lower())
country_name = country_list[c_index]
if country_name == "Singapore": #如城市名为新加坡,保留城市名,如不是则将原先的城市名转换为空值
clean_list.append(country_name)
else:
clean_list.append(None)
country_fill_list.append(country_name)
else:
# format city string
city_name = city.strip().lower().capitalize()
clean_list.append(city_name)
country_fill_list.append(None)
return clean_list, country_fill_list运行上述方程,我们会得到两个数列,一个为清理后的城市数据,一个为填充国家信息的数据。
city_list, country_fillin = check_if_country_info(df["location_city"].to_list())在数据中新建一个列,存储填充国家信息的数列。
df["country_fill_temp"] = country_fillin替换英文评论数据中的城市信息,并将新建的列填充进国家信息的空值中,再将用来填充的列删除。
df["location_city"] = city_list
df["location_country"] = df["location_country"].fillna(df["country_fill_temp"])
df = df.drop(columns=["country_fill_temp"])至此,我们就讲解完成了本项目中数据采集、数据入库和数据清理步骤的原理和代码实现。虽然处理数据的过程艰辛且漫长,但因此能将大量原始数据转换成有用的数据是非常有价值的。如果大家对于更高阶的数据建模步骤感兴趣,想知道如何实现文本数据的 emoji 分析、分词关键词、文本情感分析、词性词频分析和主题模型文本分类,请持续关注 Data Science Lab 的后续博文。
参考资料:
- 戴斌 | 春节旅游市场高开 全年旅游经济稳增
- 西湖景区春节接待游客292.86万人次
- Scrapy Vs Selenium Vs Beautiful Soup for Web Scraping
- Extract Emojis from Python Strings and Chart Frequency using Spacy, Pandas, and Plotly
- Topic Modeling with LSA, PLSA, LDA & lda2Vec
本文中部分数据来自互联网,如若侵权,请联系删除