数据科学在文本分析中的应用 :中英文 NLP(下)
回顾上篇,我们详细介绍了如何实现猫途鹰网站的中英文评论数据采集、入库和清理。本篇中,我们会重点介绍数据建模的原理和代码实现,其中包括 emoji 分析、情感分析、分词、词性词频分析、关键词分析、词云和主题模型文本分类。
数据建模
在这个步骤中,我们将对语料数据进行针对性处理,使这类数据在分析中发挥它的价值。我们通过完成以下任务来获取关键词字数统计、文本情感正负向和评论主题模型:
- 判定语料是否为目标语言
- 分离并分析语料中的 emoji
- 根据语言类型(中文或英文)对语料进行清理
- 使用语言模型进行分词,并计算词频
- 使用语言模型进行情感分析
- 主题模型进行文本分类
1. 清理非目标语言
由于猫途鹰是全球性网站,许多评论会夹杂多种语言。在本项目中我们分析的重点是中文和英文评论,这意味着我们需要筛选掉非目标语言的评论。为了更全面的分析,大家也可以将一些使用人群较多的语言包含进来(如法语、西班牙语等),但每一种语言都需要相对应的分析和模型,不可混为一谈。
这里,我们选择的语言检测器为 LangID,是一个独立语言识别库。它既可以在 Python 中运行,也可以在 Linux 环境中运行,是灵活度较高的语言检测器之一。以中文评论为例,我们按句为单位探测语句的语言,若该语句不是中文,我们将其移出文本。但由于无法将别种语言按照中文的逻辑来分词,对于在同一句子中混用别种语言的词语,我们依旧按中文处理。英文评论的处理也是同样的逻辑。
def filter_text_lan(s,lan):
if lan == 'zh':
s_lst = re.split('。',s.replace('.','。'))
else:
s_lst = s.split('. ')
s_new = ''
for sentence in s_lst:
s_lan = langid.classify(sentence)
if s_lan[0] == lan:
append_s = sentence+'. '
s_new += append_s
return s_new为了更全面的文本分析,我们将标题与评论内容进行合并,中间以句号隔开,并对 Pandas DataFrame 中代表合并文本内容的列运行 filter_text_lan() 方程。
中文评论:
df['comment_text'] = df['title'] + '。' + df['content']
df['text_zh_filtered'] = df['comment_text'].apply(lambda x: filter_text_lan(x,"zh"))英文评论:
df['comment_text'] = df['title'] + '. ' + df['content']
df['text_en_filtered'] = df['comment_text'].apply(lambda x: filter_text_lan(x,"en"))2. 处理 emoji 并清理语料中不需要的内容
Emoji 作为深受全球喜爱的表情符号,在本项目的语料中也频繁出现。为了后续分词等建模步骤,我们必须先将 emoji 从文本中分离出来,结果传送至数据库中。
使用以下方程将 emoji 从文本中提取出来,并去重。
def extract_emojies(s):
emoji_list = []
for c in s:
if c in emoji.EMOJI_DATA:
emoji_list.append(c)
return list(dict.fromkeys(emoji_list))以中文为例:
emojis_series = df['text_zh_filtered'].apply(extract_emojies)这样我们就得到了语料中所有的 emoji。接下来我们的目标是,将 emoji 的出现与具体某一个评论联系起来,并针对 emoji 统计词频。
mlb = MultiLabelBinarizer()
emojis_series_transformed = pd.DataFrame(mlb.fit_transform(emojis_series),
columns=mlb.classes_,
index=emojis_series.index)然后将其与语料数据合并:
df_transformed = df.join(emojis_series_transformed)这里,更新后的数据会将所有出现的 emoji 作为列,如果评论中出现了对应的 emoji,则记录数值为1,反之为0。数据在经过处理后的结构大致如下:
df_transformed.columns中文评论数据:

英文评论数据:

在获取 emoji 信息之后,我们可以使用 demoji 库将 emoji 从评论语料中删除。
def remove_emoji(s):
s = demoji.replace(s,'')
return s.strip()在中文评论语料中,由于网页框架的差异,过长的文本会被折叠,并且 Selenium 在抓取评论内容时无法获取被折叠的内容,会将“阅读更多”的文本一同抓取下来。国际版网站与中文版网站框架的区别是,虽然在视觉上显示的评论格式大致相同,但在网页框架中评论文本并不会被折叠。为了应对中文语料的特殊情况,我们对上述方程进行了一定的变形:
def remove_zh_chars(s):
if "阅读更多" in s:
s = s.replace("\n阅读更多。", '')
s = demoji.replace(s,'')
return s.strip()我们在评论变量上运行该程序:
英文评论:
df_transformed['text_en_cleaned'] = df_transformed['text_en_filtered'].apply(remove_emoji)中文评论:
df_transformed['text_zh_cleaned'] = df_transformed['text_zh_filtered'].apply(remove_zh_chars)3. 情感分析(中文文本)
主流的中文文本情感分析模型有两种:使用经典机器学习贝叶斯算法的 SnowNLP 和使用 RNN 的 Cemotion。SnowNLP 和 Cemotion 返回值都在0-1之间。SnowNLP 返回值越接近0则越负向,越接近1则越正向;而 Cemotion 返回的是文本是正向的概率。
在本项目中,我们将测试这两种模型,根据结果择优选择。人工标注往往需要耗费大量时间,因此我们决定随机选取20条评论,人工标注正负向。
random.seed(1024)
sample_text = sample(list(df_transformed['text_zh_cleaned']),k=20)在打印了样本评论后,将对应的情感倾向人工打标。正向为1,负向为0。
marked_sentiment = [1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]两种算法的结果都介于0和1之间,我们需要制定判断正负向的标准:都以0.5为界,结果大于0.5为正向(返回数值1),小于等于0.5为负向(返回数值0)。
像之前处理文本数据一样,这里我们先编写处理单个字符串的方程,使用 map 将该方程应用在取样的20条文本上。
# SnowNLP
def get_snownlp_senti(s):
snownlp_obj = SnowNLP(s)
s_score = snownlp_obj.sentiments
if s_score > 0.5:
return 1
else:
return 0
# Cemotion
c = Cemotion()
def get_cemotion_senti(s,model=c):
score = model.predict(s)
if score > 0.5:
return 1
else:
return 0
snownlp_result = list(map(get_snownlp_senti, sample_text))
cemotion_result = list(map(get_cemotion_senti, sample_text))将结果进行比较,查看准确率。

可以看到,SnowNLP 与 Cemotion 准确率大致相同。由于评论大多都是好评,Cemotion 的所有预测结果都为正向。在人工标注的过程中,我们会对评论进行比较,把相对而言较为负向的评论标为负向,所以 Cemotion 站在完全客观的角度将这些评论标为正向也可以理解。
SnowNLP 标出了以下文字为负向情绪:
![]()
这条评论整体是偏正向的,SnowNLP 的算法则认为其是负向。
在测试过程中,我们发现 SnowNLP 在计算速度上更快,但精确度有限;Cemotion 虽然速度慢,但精准度更高。因此,结合我们的数据量,在本项目中我们将保留 Cemotion 的结果。注意,两种算法都包含了分词等功能,只需输入文本信息即可获得情感倾向结果。
中文评论情感倾向计算方程:
def get_sentiment_score(data, text_col="text_zh_cleaned"):
data_cp = data.copy()
text_series = data_cp[text_col]
## SnowNLP
#snownlp_result = list(map(get_snownlp_senti, text_series.to_list()))
#data_cp['snownlp_senti'] = snownlp_result
## Cemotion
cemotion_result = list(map(get_cemotion_senti, text_series.to_list()))
data_cp['cemotion_senti'] = cemotion_result
return data_cp我们将语料数据传递给 get_sentiment_score() 对每条评论的情感倾向进行计算。注意,这里方程返回的是继承了原数据的新 Pandas DataFrame,英文则是将该信息加入了原 Pandas DataFrame 中;这么做的原因是在以后使用类似的功能时,可以保留 SnowNLP 的结果。中文评论后续使用的 Pandas DataFrame 名为 df_senti,英文为 df_transformed。

最后,在1710条中文评论中,负向情感倾向的评论有117条(占比7.19%),正向情感的有1593条(占比92.81%)。
4. 情感分析(英文文本)
对于英文评论的情感分析,也是类似的操作,但我们选择了更适合英文语料的工具 TextBlob(NLTK 的包装器模式)。TextBlob 以0为界,负值为负向,正值为正向。
def get_en_senti(s_text):
score = TextBlob(s_text).sentiment[0]
if score > 0:
return 1
else:
return 0将该方程在语料变量上运行:
df_transformed['blob_senti'] = df_transformed['text_en_cleaned'].apply(get_en_senti) 在得到阶段性成果后,我们将结果写进数据库,便于后续的可视化分析使用。注意,在 Jupyter 环境中 emoji 的显示没有问题,但在数据库环境中并非如此。稳妥起见,我们需要将 emoji 转换为字符串,再将相应结果写进数据库。
中文评论数据:
# 挑选需要的变量
cols_to_db = ['user_id', 'location', 'trip_type', 'comment_date', 'comment_year', 'comment_month',
'rating', 'if_pics_attached', 'data_ts','text_zh_cleaned','cemotion_senti',
'☔', '⛈', '', '', '', '',
'', '', '', '','', '', '', '', '', '', '', '', '']# 将emoji转化为英文字符串
cols_to_db_transformed = list(map(emoji.demojize,cols_to_db))# 选取需要的数据,并更新变量名称
df_to_db = df_senti[cols_to_db]
df_to_db.columns = cols_to_db_transformed# 将数据写进数据库
df_to_db.to_sql("上海_上海_外滩_cleaned_senti_ZH", engine, if_exists="replace", index=False)英文评论数据:
cols_to_db = ['user_id', 'location_city', 'location_country', 'trip_type', 'comment_date',
'comment_year', 'comment_month',
'rating', 'if_pics_attached', 'data_ts','text_en_cleaned', 'blob_senti',
'☺', '♥', '❤', '⭐', '', '', '','', '', '', '']
cols_to_db_transformed = list(map(emoji.demojize,cols_to_db))
df_to_db = df_transformed[cols_to_db]
df_to_db.columns = cols_to_db_transformed
df_to_db.to_sql("Shanghai_Shanghai_The Bund (Wai Tan)_cleaned_senti_EN", engine, if_exists="replace", index=False)5. 基于情感倾向的 emoji 分析
我们以情感情绪为组,统计 emoji 出现的频率。“emoji_count_cols” 为打印 Pandas DataFrame 变量后从中提取的 emoji 和情感倾向变量。
中文评论:
# 摘取需要的变量
emoji_count_cols = ['☔', '⛈', '', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '', '','cemotion_senti']# 提取情绪倾向
emoji_only_df = df_senti[emoji_count_cols]# 将emoji转换为英文字符串
emoji_only_df.columns = list(map(emoji.demojize,emoji_count_cols))
emoji_counts = (emoji_only_df
.groupby('cemotion_senti').sum().transpose()
.reset_index()
.rename_axis(None, axis=1)
.rename(columns={'index':'emoji',0:'senti_0_count',1:'senti_1_count'})
.sort_values(by=['senti_0_count','senti_1_count'],ascending=False)
)
emoji_counts
英文评论:
emoji_count_cols = ['☺', '♥', '❤', '⭐', '', '', '','', '', '', '','blob_senti']
emoji_only_df = df_transformed[emoji_count_cols]
emoji_only_df.columns = list(map(emoji.demojize,emoji_count_cols))
emoji_counts = (emoji_only_df
.groupby('blob_senti').sum().transpose()
.reset_index()
.rename_axis(None, axis=1)
.rename(columns={'index':'emoji',0:'senti_0_count',1:'senti_1_count'})
.sort_values(by=['senti_0_count','senti_1_count'],ascending=False)
)
emoji_counts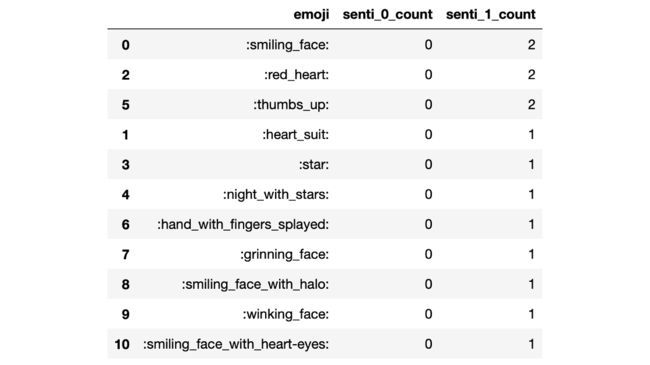
将 emoji 的词频结果写进数据库,以便后续分析。
中文 emoji 综合表:
emoji_counts.to_sql("上海_上海_外滩_emoji_count_ZH", engine, if_exists="replace", index=False)英文 emoji 综合表:
emoji_counts.to_sql("Shanghai_Shanghai_The Bund (Wai Tan)_emoji_count_EN", engine, if_exists="replace", index=False)6. 分词(中文文本)
在本项目中,我们建模的主要目标是情感分析与主题分析。对于模型而言,文字并非有效的输入,需要将文本信息数字化,并将数字化结果传递给模型,从而输出结果。在达成建模目标之前,我们需要对文本进行分词,并对词性进行标注。注意,各种语言有不同的分词方式,中文分词需要根据单词和前后语句判断,而英文分词多数以空白格为界。我们需要根据语言种类来选择不同的分词方式,具体步骤总结如下:
- 删除空白格和标点符号
- 使用语言对应的算法将文本字符串分词
- 检查分词结果,删除停止词
中文评论部分使用的 Python 库为 jieba,是最受欢迎的中文分词组件之一,包含使用 Viterbi 算法新词学习的能力。它拥有多种分词模式,其中 paddle 模式利用了 PaddlePaddle 深度学习框架,训练序列标注(双向 GRU)网络模型实现分词。
为了判断哪类分词方式更适合,我们选取数据中的前5条评论作为样本进行测试:
# 选取评论
test_list = df_transformed.loc[:5,'text_zh_cleaned']# 开启paddle模式
paddle.enable_static()
jieba.enable_paddle()# 打印分词结果
for s in test_list:
print(s)
seg_list = jieba.cut(s,use_paddle=True) # 使用paddle模式
print("Paddle Mode: " + '/ '.join(list(seg_list)))
seg_list = jieba.cut(s, cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut(s, cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut_for_search(s) # 搜索引擎模式
print("Search Mode: " + "/ ".join(seg_list))其中第4条评论的打印结果为:
十点左右开始人比较少。感觉不论作为游客还是居民,在这里散步都是非常享受的。 黄浦江边的风很舒服,江对面灯光之下就是繁华的上海,很浪漫。
Paddle Mode: 十点/ 左右/ 开始/ 人/ 比较/ 少/ 。/ 感觉/ 不/ 论/ 作为/ 游客/ 还是/ 居民/ ,/ 在这里/ 散步/ 都是/ 非常/ 享受/ 的/ 。 / 黄浦/ 江边/ 的/ 风/ 很舒服/ ,江/ 对面/ 灯光/ 之/ 下/ 就是/ 繁华/ 的/ 上海/ ,/ 很/ 浪漫/ 。
Full Mode: 十点/ 左右/ 开始/ 人/ 比较/ 较少/ 。/ 感觉/ 不论/ 作为/ 游客/ 还是/ 居民/ ,/ 在/ 这里/ 散步/ 都/ 是非/ 非常/ 享受/ 的/ 。/ / / 黄浦/ 黄浦江/ 浦江/ 江边/ 的/ 风/ 很/ 舒服/ ,/ 江/ 对面/ 灯光/ 之下/ 就是/ 繁华/ 的/ 上海/ ,/ 很/ 浪漫/ 。
Default Mode: 十点/ 左右/ 开始/ 人/ 比较/ 少/ 。/ 感觉/ 不论/ 作为/ 游客/ 还是/ 居民/ ,/ 在/ 这里/ 散步/ 都/ 是/ 非常/ 享受/ 的/ 。/ / 黄浦江/ 边/ 的/ 风/ 很/ 舒服/ ,/ 江/ 对面/ 灯光/ 之下/ 就是/ 繁华/ 的/ 上海/ ,/ 很/ 浪漫/ 。
Search Mode: 十点/ 左右/ 开始/ 人/ 比较/ 少/ 。/ 感觉/ 不论/ 作为/ 游客/ 还是/ 居民/ ,/ 在/ 这里/ 散步/ 都/ 是/ 非常/ 享受/ 的/ 。/ / 黄浦/ 浦江/ 黄浦江/ 边/ 的/ 风/ 很/ 舒服/ ,/ 江/ 对面/ 灯光/ 之下/ 就是/ 繁华/ 的/ 上海/ ,/ 很/ 浪漫/ 。第5条评论的打印结果为:
外滩夜景yyds。超级美的浦江夜景三件套~今天恋爱了 晚上吃过晚饭,去江边走一走,散散心,消消食,真的感觉超级幸福~外滩估计是每个人来上海必打卡的项目之一了。
Paddle Mode: 外滩/ 夜景/ yyds。/ 超级/ 美/ 的/ 浦江/ 夜景/ 三件套/ ~/ 今天/ 恋爱/ 了/ / 晚上/ 吃/ 过/ 晚饭/ ,/ 去/ 江边/ 走一走/ ,散散心,消消食,/ 真/ 的/ 感觉/ 超级幸福~/ 外滩/ 估计/ 是/ 每个人/ 来/ 上海/ 必/ 打卡/ 的/ 项目/ 之/ 一/ 了/ 。
Full Mode: 外滩/ 夜景/ yyds/ 。/ 超级/ 美的/ 浦江/ 夜景/ 三件/ 三件套/ 件套/ ~/ 今天/ 恋爱/ 了/ / / / 晚上/ 吃/ 过晚/ 晚饭/ ,/ 去/ 江边/ 走/ 一/ 走/ ,/ 散散/ 散散心/ 散心/ ,/ 消消/ 消食/ ,/ 真的/ 感觉/ 超级/ 幸福/ ~/ 外滩/ 估计/ 是/ 每个/ 个人/ 来/ 上海/ 必/ 打卡/ 的/ 项目/ 之一/ 了/ 。
Default Mode: 外滩/ 夜景/ yyds/ 。/ 超级/ 美的/ 浦江/ 夜景/ 三件套/ ~/ 今天/ 恋爱/ 了/ / 晚上/ 吃/ 过/ 晚饭/ ,/ 去/ 江边/ 走/ 一/ 走/ ,/ 散散心/ ,/ 消/ 消食/ ,/ 真的/ 感觉/ 超级/ 幸福/ ~/ 外滩/ 估计/ 是/ 每个/ 人来/ 上海/ 必/ 打卡/ 的/ 项目/ 之一/ 了/ 。
Search Mode: 外滩/ 夜景/ yyds/ 。/ 超级/ 美的/ 浦江/ 夜景/ 三件/ 件套/ 三件套/ ~/ 今天/ 恋爱/ 了/ / 晚上/ 吃/ 过/ 晚饭/ ,/ 去/ 江边/ 走/ 一/ 走/ ,/ 散散/ 散心/ 散散心/ ,/ 消/ 消食/ ,/ 真的/ 感觉/ 超级/ 幸福/ ~/ 外滩/ 估计/ 是/ 每个/ 人来/ 上海/ 必/ 打卡/ 的/ 项目/ 之一/ 了/ 。我们选取的这两条评论中都提及了一些活动,但方式不同。第4条评论的原句是“感觉不论作为游客还是居民,在这里散步都是非常享受的”,直接使用了“散步”这个动词;而在第5条评论的原句“去江边走一走,散散心”中,“散心”这个动词并不是单独提及的。在Paddle和精准模式中,算法通常会把类似“散散心”这种动词识别为一个词,一定程度上会影响我们对关键词的辨别。但在识别专有名词时,paddle 模式会保留一些例如“和平饭店”、“万达瑞华酒店”这类专有名词,而其他模式(特别是搜索模式)则会将长句进一步拆分。
综合考量过后,我们决定使用精准模式来分词。除此之外,我们会把没有研究意义的停止词从分词结果中删除。中文 NLP 有多种停止词表可供选择,在这里我们使用的是哈尔滨工业大学开发的停止词表。
# 读取停止词
with open('hit_stopwords.txt','r') as f:
stopwords = [line.strip() for line in f]
# 将上海、外滩这类在语料中频繁出现但是并不需要的词加入停止词表
stopwords = stopwords+['上海','外滩']
def text_tokenizer_zh(s):
# 删除空白格
s = s.strip()
# 删除标点符号
s = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()~]+", "", s)
seg_list = jieba.posseg.cut(s)
cut_list = [(x.word,x.flag) for x in seg_list if x.word not in stopwords]
return cut_list运行上述方程:
zh_text_tokenized = df_senti['text_zh_cleaned'].apply(text_tokenizer_zh)
df_senti['text_zh_tokenized'] = zh_text_tokenized7. 分词(英文文本)
英文 NLP 中最领先的平台之一便是 NLTK(Natural Language Toolkit)。NLTK 拥有50个语料库和词汇资料,开发了多种如分词、情感分析、标记、语义推理等语言处理功能。因此在处理英文评论时,我们选择 NLTK 来处理英文语料。在分词的过程中,各个词会同步进行词性标注。
在使用 NLTK 前,我们需要下载以下数据和算法:
# 下载NLTK算法资源
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')有了相关的算法和数据后,我们就可以使用 NLTK 库中的 pos_tag 方程进行英文分词。同样的,我们会从分词结果中删除停止词,这里使用的停止词资源是 NLTK 自带的英文停止词表。
# 从NLTK中读取英文停止词资源
stop_words = stopwords.words('english')
stop_words+=["shanghai",'bund']
wl = WordNetLemmatizer()
def text_tokenizer_en(s):
# remove blank space
s = s.strip()
tags = pos_tag(word_tokenize(s))
tokenized_list = []
for word, tag in tags:
tag_lemma = tag[0].lower()
wntag = tag_lemma if tag_lemma in ['a', 'r', 'n', 'v'] else None
if word.lower() not in stop_words and word.isalpha():
if wntag is None:
lemma_word = wl.lemmatize(word.lower())
else:
lemma_word = wl.lemmatize(word.lower(),wntag)
tokenized_list.append((lemma_word,tag))
return tokenized_list在英文语料数据上运行该方程:
en_text_tokenized = df_transformed['text_en_cleaned'].apply(text_tokenizer_en)
df_transformed['text_en_tokenized'] = en_text_tokenized8. 词性词频分析
在中文分词的基础上,我们还做了词性的标注,以名词为例,jieba 会将名词进一步细分为普通名词、地名、人名和其他专名。我们按照以下方式将 jieba 分词后的词语归类为名词、动词和形容词三类:
- 名词(n):n,nr,ns,nt,nz
- 动词(v):v,vn
- 形容词(a):a
和中文评论类似,我们按照以下方式将nltk分词后的英文单词做了如下归类:
- 名词(n):NN,NNS,NNP,NNPS,FW
- 动词(v):VB,VBD,VBG,VBN
- 形容词(a):JJ,JJR,JJS
如下所示,分词过后,每一段评论都转化为一个元组列表(list of tuples),每个元组格式为(词,词性)。
中文分词结果展示:

英文分词结果展示:
![]()
以下方程可以将上述格式的分词数据通过词性进行筛选,并计算每个词对应的词频,中英文分词数据通用。这里我们使用的小技巧是组合使用 Python 中的 itertools 库和 collection 库,将表单 list 中的表单元素合为单个表单,并运用 collection 中的 counter 计算各个元素的频率。
pos_map_zh = {'n':['n', 'nr', 'ns', 'nt', 'nz'], 'v':['v','vn'], 'a':['a']}
pos_map_en = {'n':['NN','NNS','NNP','NNPS','FW'], 'v':['VB','VBD','VBG','VBN'],
'a':['JJ','JJR','JJS']}
def get_word_count(token_series, pos_flg, lan):
# 将表单list中的表单元素合为单个表单
word_list = list(itertools.chain.from_iterable(token_series))
if lan.upper() == 'ZH':
pos_lst = pos_map_zh[pos_flg]
else:
pos_lst = pos_map_en[pos_flg]
word_list_filtered = [x[0] for x in word_list if x[1] in pos_lst]
# 计算各个元素的频率
counts = Counter(word_list_filtered)
data_items = counts.items()
data_list = list(data_items)
# 将结果转换为DataFrame输出
word_count_df = pd.DataFrame(data_list)
word_count_df.rename(columns = {0:'word', 1:'frequency'}, inplace = True)
word_count_df['pos'] = pos_flg
return word_count_df输入一个字符串,该方程就会根据输入的词性进行筛选,并计算出相应的词频。以英文为例,我们希望在语料字符串中筛选出名词并进行词频计算,结果展示如下:

有了 get_word_count(),我们就可以根据从多个维度对词语进行词频统计,分别是:情绪倾向、词性、评论年份、评论月份。
def word_count_grouped(data, token_col, lan):
data_copy = data.copy()
# 使用评论语言情绪倾向相对应的变量名
if lan.upper() == 'ZH':
senti_col = 'cemotion_senti'
pos_map = pos_map_zh
else:
senti_col = 'blob_senti'
pos_map = pos_map_en
# 计算情绪倾向,评论年份和月份变量各自去重后的值
senti_values = data[senti_col].unique()
year_values = data['comment_date'].dt.year.unique()
month_values = data['comment_date'].dt.month.unique()
result_count_df = pd.DataFrame()
# 根据特定的情绪倾向,评论年份和月份值,计算这类评论的词频
for pos_flg in pos_map.keys():
for senti in senti_values:
for y in year_values:
for m in month_values:
data_filtered = data[(data[senti_col]==senti)&(data['comment_year']==y)&(data['comment_month']==m)]
if data_filtered.shape[0] > 0:
count_df = get_word_count(data_filtered[token_col], pos_flg, lan)
count_df[senti_col] = senti
count_df['comment_year'] = y
count_df['comment_month'] = m
result_count_df = pd.concat([result_count_df, count_df])
return result_count_df.reset_index(drop=True)在中文分词结果上运行,并将结果写进数据库:
word_count_df = word_count_grouped(df_senti,'text_zh_tokenized','zh')
word_count_df.to_sql("上海_上海_外滩_word_count_ZH", engine, if_exists="replace", index=False)中文词频结果展示:

在英文分词结果上运行:
word_count_df = word_count_grouped(df_transformed,'text_en_tokenized','EN')
word_count_df.to_sql("Shanghai_Shanghai_The Bund (Wai Tan)_word_count_EN", engine, if_exists="replace", index=False)英文词频结果展示:

9. 关键词分析
Jieba 中包含两种更高阶的用来计算关键词的算法:TF-IDF 和 TextRank。其中 TF-IDF 作为词袋模型(Bag of Word)也经常被用来作为将文字内容数字化的算法之一。由于这两种算法自带清理模块,我们直接使用了原文本而并非去除了停用词的语料。
s_concat_list = ''.join(df_senti['text_zh_cleaned'].to_list())基于TF-IDF的关键词:

基于TextRank的关键词:

两种算法的结果在排序上略有不同。
10.词云展示
为了进一步了解游客们对上海外滩的讨论内容,我们将中英文语料中的名词、动词和形容词分别制作了词频词云,并将词云结果保存。这里我们使用的库是 WordCloud。由于 WordCloud 无法辨别中文,词云会出现乱码的情况。我们需要手动上传中文字体 .tff 文件并传递给 WordCloud,这里我们使用的是开源的阿里巴巴普惠体。
def get_word_cloud_pos(count_df,font_pth, lan):
pos_values = count_df['pos'].unique()
fig = plt.figure(figsize=(30,25))
for i,pos_tag in enumerate(pos_values):
word_count_sum = count_df[count_df['pos']==pos_tag].groupby(['word'])[['frequency']].sum().reset_index()
word_count_dict = word_count_sum.set_index('word').to_dict()['frequency']
wc = WordCloud(width=1000, height=800,background_color = 'white',font_path = font_pth).generate_from_frequencies(word_count_dict)
ax = fig.add_subplot(1,len(pos_values),i+1)
ax.imshow(wc)
ax.title.set_text("Word Count for POS: "+pos_tag)
ax.axis('off')
plt.savefig('word_cloud_'+lan+'.png')
return运行该方程获得中文词云:
get_word_cloud_pos(word_count_df,'ALIBABA-PUHUITI-REGULAR.TTF','ZH')
运行该方程获得英文词云:
get_word_cloud_pos(word_count_df,'ALIBABA-PUHUITI-REGULAR.TTF','EN')
可以看到,无论是中文还是英文的语料,占比较高的词在意义上非常相近,两种语言的词云结果很类似。
11.主题模型文本分类
为了丰富文本分析的层次,我们还使用主题模型(Topic Modelling)对语料进行无监督学习,根据语义将类似的文本划为一组,对评论进行分类。主题模型主要有两类:pLSA(Probabilistic Latent Semantic Analysis)和 LDA(Latent Dirichlet Allocation),LDA 是基于 pLSA 算法的延伸,使得模型可以适应新的文本。
注意,由于我们事先并不知道文本分为几个种类,主题模型是一个无监督学习任务,我们需要根据结果调整文本类别的数量。这里,我们使用了 Python 的 Genism 工具库来识别中英文文本的语意主题。
def get_topics(data, topics_n, token_col):
# 建立分词表
l_words_list = [[word[0] for word in doc] for doc in data[token_col]]
# 建立语料库
word_dict = corpora.Dictionary(l_words_list)
corpus = [word_dict.doc2bow(text) for text in l_words_list]
# 建立模型
lda_model = models.LdaMulticore(corpus=corpus,
id2word=word_dict,
num_topics=topics_n)
# 打印文本分类结果
topic_list_lda = lda_model.print_topics()
# topic_list_lsi = lsi.print_topics(16)
print("以LDA为分类器的"+str(topics_n)+"主题的单词分布为:\n")
for topic in topic_list_lda:
print(topic)我们可以尝试多个文本类别数量,看结果是否有价值,这部分非常依赖分析者自身的判断,需要探讨文本类别数量的合理性。
中文文本类别数量中比较有意义是2类主题,LDA 结果如下:

可以看出,结果并没有太大区别。事实上,在建模过程中,很多模型的表现并不会像人们预期的一样好。不过由此也可以看出,基本上中文评论并没有突出的类别,游客基本以游览景观和建筑为主,并且游览时间大多为晚上。
英文文本类别数量中比较有意义的是3类主题,LDA 结果如下:

无论是情感分析还是文本分类,本质上都是通过将文本转化为数字,通常再进行监督学习。数字化文本的方法大致有三类,它们分别是本项目中使用的以词频为基础的词袋模型(Bag of Word)、独热编码(One Hot Encoding)和文本向量化(Word2Vec);词袋模型中最富盛名的是 TF-IDF。这类任务都可以通过人工标注将分类结果传递给模型(如深度学习等),再通过训练结果选择合适的模型。这样的由用户自行训练的模型会更贴近项目需求,虽然开发周期长,但结果更精准。但在大数据时代,人工标注需要耗费大量的时间和资金,这就诞生了许多诸如 Cemotion 这样预先经历过大量文本训练的模型,供各类文本分析任务使用,大大降低了时间成本和使用门槛。
至此,我们就完成了对中英文 NLP 建模部分的介绍。文本分析与建模基本都围绕着词频和分类这两块内容展开,核心是通过“数字”来呈现大批量文本中的可用信息。而随着算法的发展,以神经网络为主的例如 transformer 这类语言模型成为了大热的话题,模型的用途从最初批量处理和分析文本数据,到现如今的虚拟客服、ChatGPT 等代替人工的应用,数据科学正在逐步融入人们的日常生活。如果大家对神经网络在语言上的应用感兴趣,请持续关注 Data Science Lab 的后续博文。
参考资料:
- 戴斌 | 春节旅游市场高开 全年旅游经济稳增
- 西湖景区春节接待游客292.86万人次
- Scrapy Vs Selenium Vs Beautiful Soup for Web Scraping
- Extract Emojis from Python Strings and Chart Frequency using Spacy, Pandas, and Plotly
- Topic Modeling with LSA, PLSA, LDA & lda2Vec
本文中部分数据来自互联网,如若侵权,请联系删除