深度学习模型压缩与优化加速
1. 简介
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、系统优化加速、异构计算等方法突破瓶颈,即分别在算法模型、计算图或算子优化以及硬件加速等层面采取必要的手段:
- 模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,具体可划分为如下几种方法(量化、剪枝与NAS是主流方向):
- 线性或非线性量化:1/2bits, INT4, INT8, FP16和BF16等;
- 结构或非结构剪枝:Sparse Pruning, Channel pruning和Layer drop等;
- 网络结构搜索 (NAS: Network Architecture Search):ENAS、Evolved Transformer、NAS FCOS、NetAdapt等离散搜索,DARTS、AdaBert、Proxyless NAS、FBNet等可微分搜索,SPOS、FairNAS、BigNAS、HAT、DynaBert与AutoFormer等One-shot搜索;
- 其他:权重矩阵的低秩分解、知识蒸馏与网络结构精简设计(Mobile-net, SE-net, Shuffle-net, PeleeNet, VoVNet, MobileBert, Lite-Transformer, SAN-M)等;
- 系统优化是指在特定系统平台上,通过Runtime层面性能优化,以提升AI模型的计算效率,具体包括:
- Op-level的算子优化:FFT Conv2d (7×7, 9×9), Winograd Conv2d (3×3, 5×5) 等;
- Layer-level的快速算法:Sparse-block net [1] 等;
- Graph-level的图优化:BN fold、Constant fold、Op fusion和计算图等价变换等;
- 优化工具与库(手工库、自动编译):TensorRT (Nvidia), MNN (Alibaba), TVM (Tensor Virtual Machine), Tensor Comprehension (Facebook) 和OpenVINO (Intel) 等;
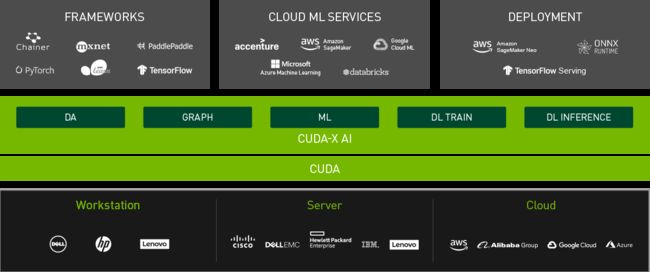
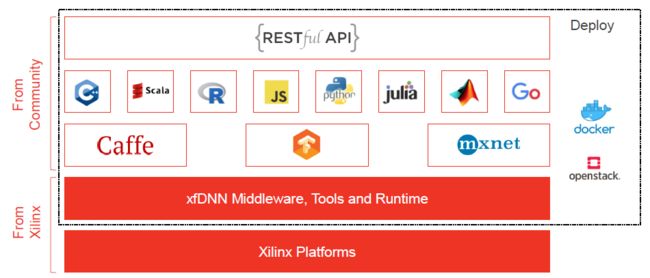
- 异构计算方法借助协处理硬件引擎(通常是PCIE加速卡、ASIC加速芯片或加速器IP),完成深度学习模型在数据中心或边缘计算领域的实际部署,包括GPU、FPGA或DSA (Domain Specific Architecture) ASIC等。异构加速硬件可以选择定制方案,通常能效、性能会更高,目前市面上流行的AI芯片或加速器可参考 [2]。显然,硬件性能提升带来的加速效果非常直观,例如2080ti与1080ti的比较(以复杂的PyramidBox人脸检测算法为例,由于2080ti引入了Tensor Core加速单元,FP16计算约提速36%);另外,针对数据中心部署应用,通常会选择通用方案以构建计算平台(标准化、规模化支持业务逻辑计算),需要考虑是否有完善的生态支持,例如NVIDIA的CUDA,或者Xilinx的xDNN:
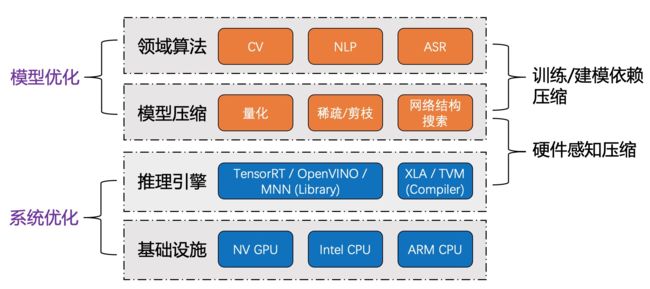
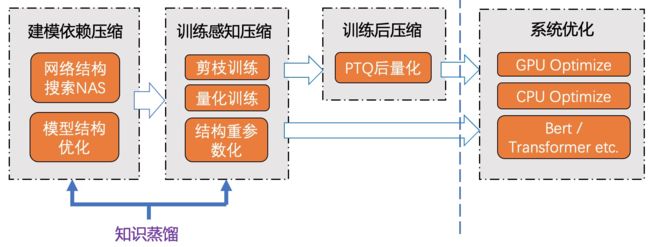
- 此外,从模型优化与系统优化的角度分析,领域算法建模与模型压缩通常紧密相关;推理优化手段的选择,通常也与基础设施或硬件平台相关联;而要想达到极致的模型压缩与推理优化效果,更需要硬件感知的反馈(Hardware-aware Compression):
2. 基于Roofline Model评估理论性能
基于计算平台的峰值算力与最高带宽约束,以及AI模型的理论计算强度(前向推理的计算量与内存交换量的比值),Roofline model为AI模型区分了两个性能评估区间,即Memory-bound区间与Compute-bound区间:
- Memory-bound:表示模型的计算强度相对较低,理论性能受限于存储访问。此时平台带宽越高,AI模型的访存开销越低。MobileNet、DenseNet属于典型的Memory-bound型模型;
- Compute-bound:表示模型的计算强度超过了平台限制(Imax),能够100%利用平台算力。此时,平台算力越高,AI模型推理耗时越低。VGG属于典型的Compute-bound型模型;

3. 高性能推理引擎——TensorRT/TVM/MNN基础
TensorRT是NVIDIA推出的面向GPU应用部署的深度学习优化加速工具,即是推理优化引擎、亦是运行时执行引擎。TensorRT采用的原理如下图所示,可分别在图优化、算子优化、Memory优化与INT8 Calibration等层面提供推理优化支持,具体可参考[3] [4]:
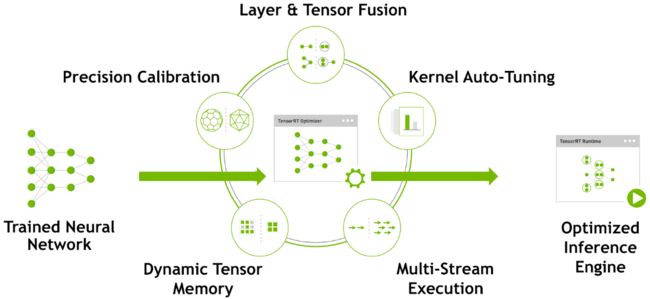
TensorRT能够优化重构由不同深度学习框架训练的深度学习模型:
- 全图自动优化:首先,对于Caffe、TensorFlow、MXNet或PyTorch训练的模型,若包含的操作都是TensorRT支持的,则可以直接通过TensorRT生成推理优化引擎;并且,对于PyTorch模型,亦可采用Trtorch执行推理优化;此外,亦可借助ONNX中间格式,通过(TF, PyTorch) -> ONNX -> TensorRT方式,执行优化转换 [27];等等;
- 全图手工优化:对于MXnet, PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接实现推理优化;
- 手工/自动分图:若训练的网络模型包含TensorRT不支持的Op:
手工分图:将深度网络手工划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部分可采用其他框架实现,如MXnet或PyTorch,并建议使用C++ API实现,以确保更高效的Runtime执行;
Custom Plugin:不支持的Op可通过Plugin API实现自定义,并添加进TensorRT计算图,以支持算子的Auto-tuning,从而丰富TensorRT的Op-set完备性,例如Faster Transformer的自定义扩展 [26];Faster Transformer是较为完善的系统工程,能够实现标准Bert/Transformer的高性能计算;
TFTRT自动分图:TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点;FP32 TF TRT优化流程如下:
from tensorflow.contrib import tensorrt as trt
def transfer_trt_graph(pb_graph_def, outputs, precision_mode, max_batch_size):
trt_graph_def = trt.create_inference_graph(
input_graph_def = pb_graph_def,
outputs = outputs,
max_batch_size = max_batch_size,
max_workspace_size_bytes = 1 << 25,
precision_mode = precision_mode,
minimum_segment_size = 2)
return trt_graph_def
trt_gdef = transfer_trt_graph(graph_def, output_name_list,'FP32', batch_size)
input_node, output_node = tf.import_graph_def(trt_gdef, return_elements=[input_name, output_name])
with tf.Session(config=config) as sess:
out = sess.run(output_node, feed_dict={input_node: batch_data})复制
PyTorch自动分图:基于Torchscript执行自动分图,避免custom plugin或手工分图的低效率支持,提升模型优化的支持效率;并降低用户使用TensorRT的门槛,自动完成计算图转换与优化tuning;对于不支持的Op或Sub-graph,采用Libtorch作为Runtime兜底(参考NVIDIA官方提供的优化加速工具Torch-TensorRT,可作为PyTorch编程范式的扩展):
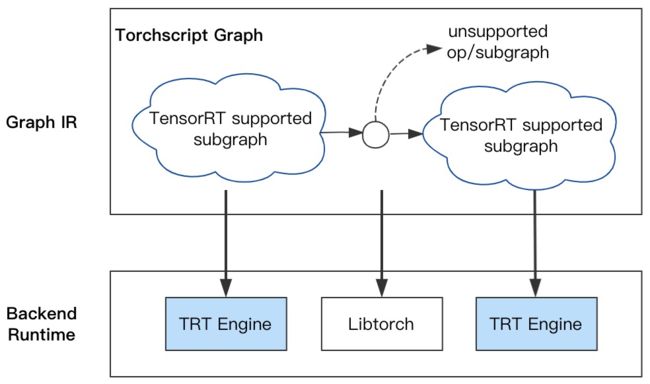
- INT8 Calibration:TensorRT的INT8量化需要校准(Calibration)数据集,能够反映真实应用场景,样本数量少则3~5个即可满足校准需求;且要求GPU的计算功能集sm >= 6.1;
在1080ti平台上,基于TensorRT4.0.1,Resnet101-v2的优化加速效果如下:
| Network |
Precision |
Framework / GPU: 1080ti (P) |
Avg. Time (Batch=8, unit: ms) |
Top1 Val. Acc. (ImageNet-1k) |
|---|---|---|---|---|
| Resnet101 |
FP32 |
TensorFlow |
36.7 |
0.7612 |
| Resnet101 |
FP32 |
MXnet |
25.8 |
0.7612 |
| Resnet101 |
FP32 |
TRT4.0.1 |
19.3 |
0.7612 |
| Resnet101 |
INT8 |
TRT4.0.1 |
9 |
0.7574 |
在1080ti/2080ti平台上,基于TensorRT5.1.5,Resnet101-v1d的FP16加速效果如下(由于2080ti包含Tensor Core,因此FP16加速效果较为明显):
| 网络 |
平台 |
数值精度 |
Batch=8 |
Batch=4 |
Batch=2 |
Batch=1 |
|---|---|---|---|---|---|---|
| Resnet101-v1d |
1080ti |
FP32 |
19.4ms |
12.4ms |
8.4ms |
7.4ms |
| FP16 |
28.2ms |
16.9ms |
10.9ms |
8.1ms |
||
| INT8 |
8.1ms |
6.7ms |
4.6ms |
4ms |
||
| 2080ti |
FP32 |
16.6ms |
10.8ms |
8.0ms |
7.2ms |
|
| FP16 |
14.6ms |
9.6ms |
5.5ms |
4.3ms |
||
| INT8 |
7.2ms |
3.8ms |
3.0ms |
2.6ms |
相比于自动编译优化(以TVM为例):TensorRT的Kernel auto-tuning主要在一些手工优化的Op-set上执行Auto-tuning;而TVM则是基于Relay IR、计算表达与Schedule定义的搜索空间,通过EA、XGBoost或Grid search等搜索策略,执行自动编译优化、生成lower Graph IR(包含计算密集算子的优化op、以及基本的图优化),最终通过后端编译器(LLVM、nvcc等)生成指定硬件平台的优化执行代码。TVM的优化流程如下图所示:

具体而言,TVM提供了AutoTVM与AutoScheduler两种自动优化方式。AutoScheduler又称之为TVM Ansor,能够基于Cost model性能预估和进化算法执行自动寻优,搜索获得最佳的Schedule设置(tiling、op fusion、buffer与inline等)。以Intel CPU应用部署为例,基于TVM Ansor tuning,通过设置SIMD指令(如AVX512、VNNI)和多线程加速,能取得、甚至超过OpenVINO的加速效果。
有关TVM的details具体参考官网:Getting Started With TVM — tvm 0.8.dev0 documentation
有关TVM Ansor的具体介绍,可参考:深度学习编译系列之 ANSOR 技术分享 – 知乎
针对移动端应用部署:TVM自动编译优化也能取得理想的优化加速效果,但是由于移动端需要适配多种OS、与多种设备,因此TVM的tuning成本限制了其在移动端的应用推广。MNN是阿里淘系技术部推出的面向移动端推理部署的轻量型计算引擎,能够为多种深度学习模型的计算实现提供高效率的算子支持(包括FP32、FP16与INT8算子),并通过半自动方式提供优化tuning支持。并且,用户通过自定义的量化表或稀疏表,可以为MNN传递模型量化参数或稀疏率等信息,以支持计算图的量化优化或稀疏化。以量化训练(QAT: Quantization-aware Training)与MNN量化转换为例,可以构建从ASR模型的大规模预训练、到量化训练微调、再到MNN量化优化的工具链路:
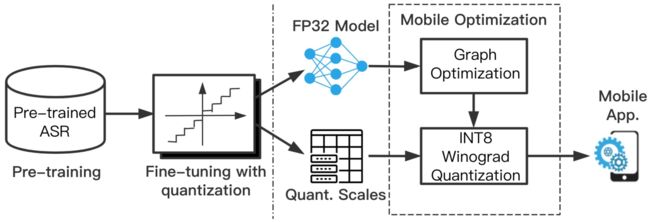
4. 网络剪枝
深度学习模型因其稀疏性或过拟合倾向,可以被裁剪为结构精简的网络模型,具体包括结构性剪枝与非结构性剪枝:
- 非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持,如Deep Compression [5], Sparse-Winograd [6] 算法等;
- 结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行:
- 如局部方式的、通过Layer by Layer方式的、最小化输出FM重建误差的Channel Pruning [7], ThiNet [8], Discrimination-aware Channel Pruning [9];
- 全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming [10];
- 全局方式的、按Taylor准则对Filter作重要性排序的Neuron Pruning [11];
- 全局方式的、可动态重新更新Pruned filters参数的剪枝方法 [12];
- 基于GAN思想的GAL方法 [24],可裁剪包括Channel, Branch或Block等在内的异质结构;
- 借助Geometric Median确定卷积滤波器冗余性的剪枝策略 [28];
- 基于搜索策略的自动剪枝:基于Reinforcement Learning (RL),实现每一层剪枝率的连续、精细控制,并可结合资源约束完成自动模型压缩 (AMC) [31];以及NetAdapt,在满足平台资源约束的条件下,精简化预训练模型结构,同时确保识别精度最大化;
以Channel Pruning为例,结构剪枝的规整操作如下图所示,可兼容现有的、成熟的深度学习框架和推理优化框架:
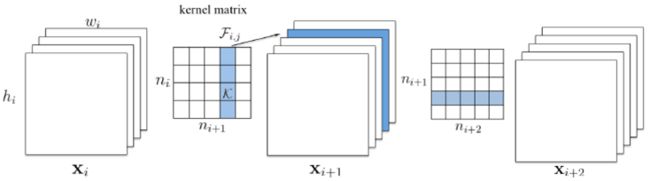
5. 模型量化
模型量化是指权重或激活输出可以被聚类到一些离散、低精度(Reduced precision)的数值点上,通常依赖于特定算法库或硬件平台的支持:
- 二值化网络:XNORnet [13], ABCnet with Multiple Binary Bases [14], Bin-net with High-Order Residual Quantization [15], Bi-Real Net [16];
- 三值化网络:Ternary weight networks [17], Trained Ternary Quantization [18];
- W1-A8 或 W2-A8量化: Learning Symmetric Quantization [19];
- INT8量化:TensorFlow-lite [20], TensorRT [21], Quantization Interval Learning [25];
- INT4量化:NVIDIA Iterative Online Calibration [29], LSQ [30];
- 其他(非线性):Intel INQ [22], log-net, CNNPack [23] 等;
- PTQ策略(Post-Training Quantization):针对预训练模型,通过适当调整kernel参数分布、或补偿量化误差,可有效提升量化效果;另外也可以通过权重不变的训练(基于Calibration-set),按优化方式实现量化参数的Refine,如AdaRound、AdaQuant [32]与BRECQ;
- 关于量化的比较系统性的概念论述,参考论文:Quantizing deep convolutional networks for efficient inference: A whitepaper;
若模型压缩之后,推理精度存在较大损失,可通过Fine-tuning予以恢复,并在训练过程中结合适当的Tricks,例如针对ImageNet分类模型的剪枝后微调,可结合Label Smoothing、Mix-up、Knowledge Distillation、Focal Loss等。 此外,模型压缩、优化加速策略可以联合使用,进而可获得更为极致的压缩比与加速比。例如结合Network Slimming与TensorRT INT8优化,在1080ti Pascal平台上,Resnet101-v1d在压缩比为1.4倍时(Size=170MB->121MB,FLOPS=16.14G->11.01G),经TensorRT int8量化之后,推理耗时仅为7.4ms(Batch size=8)