MOSS模型量化版部署过程
文章目录
- 项目背景
- 配置环境与准备
- 部署推理
-
- 命令行部署
-
- 报错1
- 报错2:
- 使用免费试用的阿里云GPU部署
- 在AutoDL平台上部署
项目背景
2023年4月21日,复旦大学自然语言处理实验室正式开放MOSS模型,是国内首个插件增强的开源对话大语言模型。MOSS 相关代码、数据、模型参数已在 GitHub 和 Hugging Face 等平台开放,
项目地址:https://github.com/OpenLMLab/MOSS。
MOSS 对硬件要求还是较高,如果想本地部署的话,仍但需要非常大的开销。如果使用A100 或 A800 可以单卡运行,而使用NVIDIA 3090 只能并行多卡运行,GPU 显存至少需要 30GB。但如果想在消费级显卡上进行部署,就只能部署量化后的版本,如下图所示:
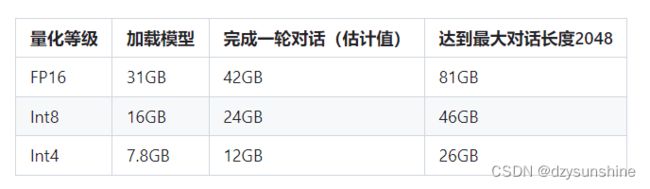
具体对应的模型版本如下:
moss-moon-003-sft-int4: 4bit量化版本的moss-moon-003-sft模型,约占用12GB显存即可进行推理。
moss-moon-003-sft-int8: 8bit量化版本的moss-moon-003-sft模型,约占用24GB显存即可进行推理。
moss-moon-003-sft-plugin-int4: 4bit量化版本的moss-moon-003-sft-plugin模型,约占用12GB显存即可进行推理。
moss-moon-003-sft-plugin-int8: 8bit量化版本的moss-moon-003-sft-plugin模型,约占用24GB显存即可进行推理。
由于本次实验所使用的配置如下:
CPU&内存:28核(vCPU)112 GB
操作系统:Ubuntu_64
GPU:NVIDIA Tesla P100
显存:16G
故选择 moss-moon-003-sft-int4 模型进行部署实验。
配置环境与准备
1、登录服务器,下载本仓库内容至服务器,进入MOSS目录
git clone https://github.com/OpenLMLab/MOSS.git
cd MOSS
2、创建python3.8版本的conda环境,并进入
conda create --name moss python=3.8
conda activate moss
3、根据 requirements.txt 安装环境依赖
pip install -r requirements.txt
4、安装使用量化模型所需的包(4/8-bit)
pip install triton
5、安装gradio,以便可以使用基于Gradio的网页demo
pip install gradio
pip install mdtex2html
其中,mdtex2html 是因为运行时有报错缺少此包,故这里可以提前装好。
6、下载模型文件,这里直接从huggingface上下载到服务器
# 安装 huggingface_hub
pip install huggingface_hub
# 进入模型文件的指定位置
cd /data/sim_chatgpt/
然后使用下面代码,将模型文件安装到指定位置
from huggingface_hub import snapshot_download
snapshot_download(repo_id="fnlp/moss-moon-003-sft-int4", cache_dir="./moss-moon-003-sft-int4")
下载完成后,得到model_path为:/data/sim_chatgpt/moss-moon-003-sft-int4/models–fnlp–moss-moon-003-sft-int4/snapshots/4e33058483a36ade9067f7f25f3127cb95386b01
部署推理
这里有两种方式,一种是命令行,在服务器上直接运行;一种是网页版,可以通过链接在浏览器访问。
命令行部署
这里我们要运行 moss_cli_demo.py 文件,在运行前需要修改model_path,如下:
parser.add_argument("--model_name", default="/data/sim_chatgpt/moss-moon-003-sft-int4/models--fnlp--moss-moon-003-sft-int4/snapshots/4e33058483a36ade9067f7f25f3127cb95386b01"
报错1
ValueError:
/data/sim_chatgpt/moss-moon-003-sft-int4/models–fnlp–moss-moon-003-sft-int4/snapshots/4e33058483a36ade9067f7f25f3127cb95386b01
is not a folder containing a.index.jsonfile.
解决办法
将下面代码进行替换(注释掉)
# model = load_checkpoint_and_dispatch(
# raw_model, model_path, device_map="auto", no_split_module_classes=["MossBlock"], dtype=torch.float16
# )
model = MossForCausalLM.from_pretrained(model_path, trust_remote_code=True).half().cuda()
报错2:
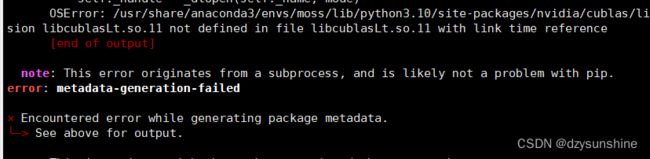
运行时报错,如下图所示:

python: /project/lib/Analysis/Utility.cpp:136: bool mlir::supportMMA(mlir::Value, int): Assertion `(version == 1 || version == 2) && “Unexpected MMA layout version found”’ failed.
遇到问题:https://github.com/OpenLMLab/MOSS/issues/149
issue中有人提到:
- 算力小于70的显卡都不支持Float8 and Float16,P100 P40算力版本都是60+所以暂时只能使用Float32,但是显存又不够。NVDIA V100 NVIDIA TITAN V及其以上显卡可以支持。
- triton官网说对fp16量化模型支持不完善, p100/40等老显卡都会报如上的错. 需要等他们写入更多老显卡支持。
另外有人实测V100 32GB可以跑int4量化模型.
解决方法如下
将triton换成auto-gptq,这样就绕过了triton验证.
git clone https://github.com/PanQiWei/AutoGPTQ
conda create -n moss python==3.10
cd MOSS
python setup_env.py --install_auto_gptq
另外,需要注意需要修改两个地方:
1、修改model
2、修改model_path
运行
python moss_cli_demo.py
但我并没有尝试成功,一个原因在于,github链接中没有setup_env.py,只有setup.py,另一个原因是即使按照github链接中提供的安装方式,无法安装成功。
由于以上问题并没有得到解决,故决定换一台GPU进行尝试(不在一棵树上吊死)。
尝试使用可以免费试用的阿里云GPU(用的V100,支持资源包抵扣)服务器来部署。
使用免费试用的阿里云GPU部署
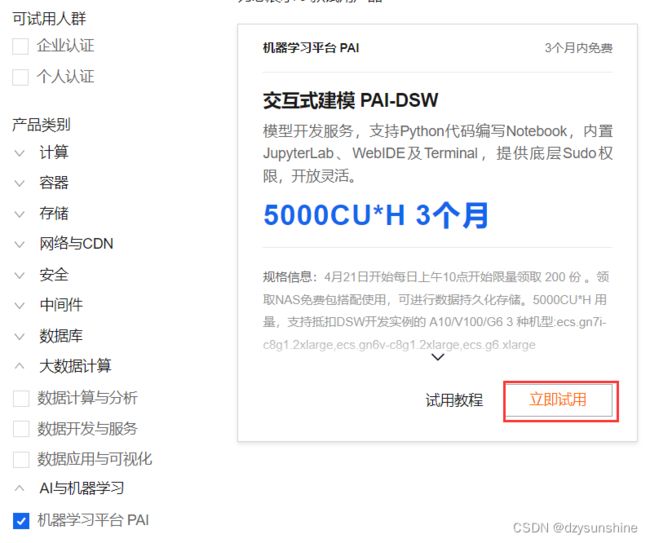
1、打开网址:https://free.aliyun.com/,并进行登录;
2、左侧产品类别中选中机器学习平台API后,选择 5000CU*H 3个月,并点击免费试用:
3、点击后,选择个人认证,继续认证成功即可:

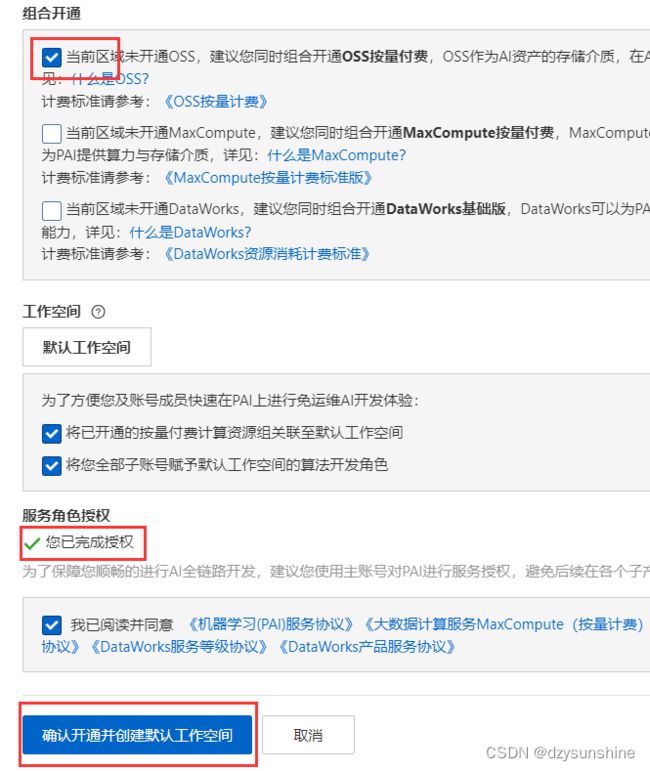
4、开通机器学习PAI并创建默认工作空间


5、创建DSW实例,并选择V100,选择官方镜像
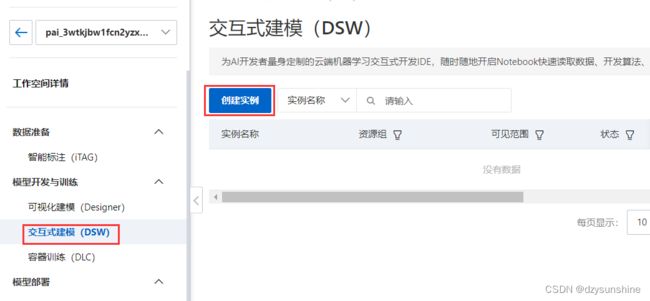

选择官方镜像:
pytorch:1.12-gpu-py39-cu113-ubuntu20.04

6、等待启动

但无奈一直启动失败…(后面考虑换个时间再试试)

后过了两三个小时后,可以重启成功了(所以不要放弃,哈哈),点击打开进入。

选中Terminal
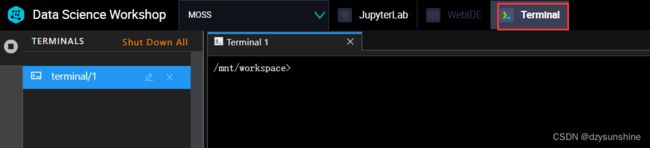
先用git clone命令下载MOSS项目
git clone https://github.com/OpenLMLab/MOSS.git
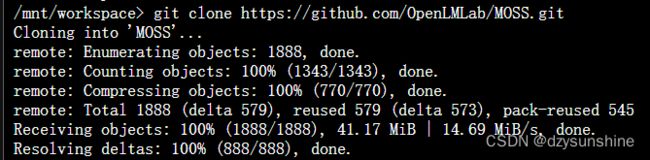
进入MOSS目录,并安装所需要的包
cd MOSS
pip install -r requirements.txt

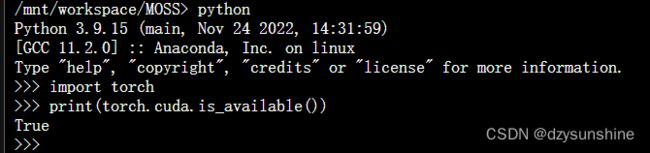
先试下torch是否可用(因为配置机器的时候选的是1.12的torch)

torch报错,可以用pyotrch官网命令重新安装下torch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
再来看下torch是否可用
将默认加载的模型设置为moss-moon-003-sft-int8
vi moss_cli_demo.py
# 修改第第16行 default = 'fnlp/moss-moon-003-sft-int8'
运行moss_cli_demo.py文件
python moss_cli_demo.py
由于我们没有提前下载好要加载的模型,运行代码后会自动下载指定的模型。
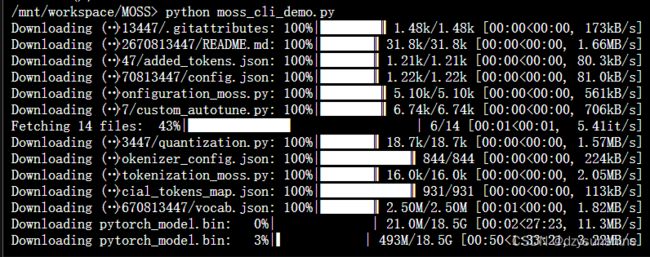
下载模型速度还是很快的,大概半小时左右。
但运行的时候,没办法运行成功(也没有报错,加载数据后就没后续了),大概率是显存不够的原因,这里的显存只有16G,故又讲model_name改回原来的 ‘fnlp/moss-moon-003-sft-int4’,
执行python moss_cli_demo.py命令。

就可以和MOSS进行对话了
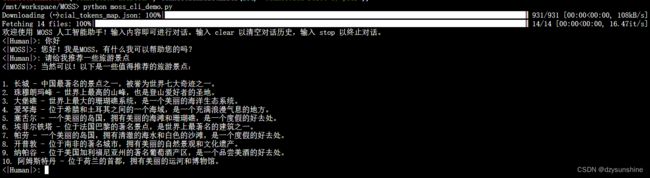
推理的速度还是比较慢的,感觉用了1分钟左右才输出答案。
GPU使用率及显存占用情况如下:

可以看出基本上占了14个G左右了,随着对话的增多,显存还会继续增加。
在AutoDL平台上部署
地址:https://www.autodl.com/home
租一台32G显存的V100
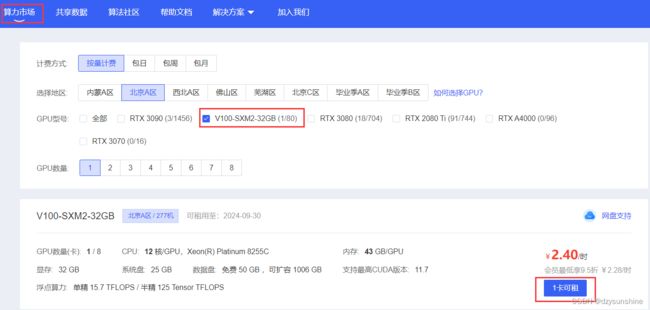
版本配置如下:

选好后,点击立即创建。


使用提供的ssh账号和密码进行登录。
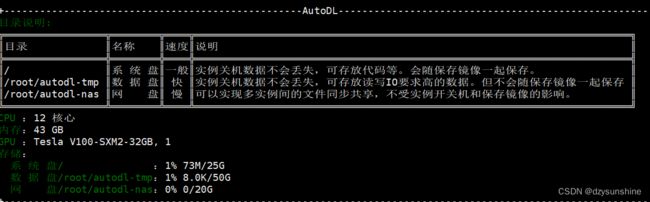
进入conda环境
source activate
安装git-lfs:https://www.cnblogs.com/allmignt/p/12353756.html
下载本仓库内容至本地/远程服务器
git clone https://github.com/OpenLMLab/MOSS.git
进入MOSS,安装所需的包
cd MOSS
pip install -r requirements.txt
因为模型文件比较大,故需要将模型文件下载到数据盘中,以免造成数据盘内存溢出。
# 进入数据盘
cd /root/autodl-tmp/
git clone https://huggingface.co/fnlp/moss-moon-003-sft-int8.git
修改模型文件加载路径
model_path = '/root/autodl-tmp/moss-moon-003-sft-int8'
运行 python moss_cli_demo.py即可。
