数据分析实战——星巴克门店数量可视化分析
星巴克门店分布可视化分析
项目介绍:使用python对星巴克门店分布进行可视化分析
数据背景:数据源来自与Kaggle: Starbucks Locations Worldwide | Kaggle,囊括了截至2017/2月份全球星巴克门店的基础信息,包括品牌名称、门牌地址、所在国家、经纬度等一系列详细的信息。
数据介绍:
| 字段名称 | 解释说明 |
|---|---|
| Brand | 品牌名称 |
| Store Number | 门店编号 |
| Store name | 门店名称 |
| Ownership Type | 门店所有权类型 |
| Street Address | State/Province |
| City | 门店所在的城市 |
| State/Province | 门店所在的省份 |
| Country | 门店所在的国家 |
| Postcode | 门店所在地址的邮政编码 |
| Phone Number | 门店的联系电话 |
| Timezone | 门店所在地的时区 |
| Longitude | 门店地址的经度 |
| Latitude | 门店地址的纬度 |
| centered 文本居中 | right-aligned 文本居右 |
任务概述
- 星巴克旗下有多少个品牌
- 统计全球有多少个国家开设了星巴克门店,显示排名前五和后十的国家
- 显示拥有星巴克门店数量前十的城市
- 按照星巴克在中国的分布情况,统计排名前十的城市
- 用饼图显示星巴克的经营方式有几种
导入必要的数据包
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
读取数据并查看
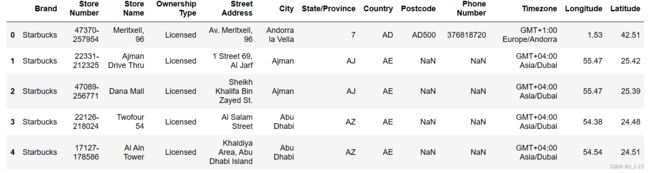
data = pd.read_csv(r'./Desktop/directory.csv.csv')
data.head()
查看缺失值
data.isnull().sum()
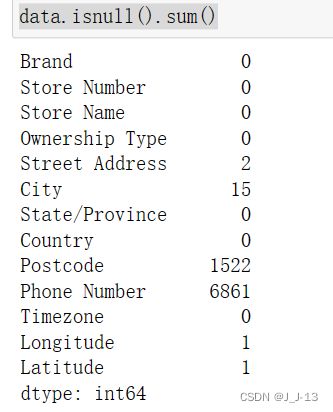
利用isnull()函数对数据进行缺失值统计,可以发现每一列数据的缺失情况,在此数据中city、postcode、phone number字段存在较多缺失值,但本次任务处理的指标与其相关不大,故不对其进行处理
统计星巴克旗下有多少品牌
num = len(data['Brand'].unique())
print('星巴克旗下有%d个品牌'%num)
data['Brand'].value_counts()

利用unique()函数对”Brand‘字段进去去重处理,得到星巴克旗下的品牌数量,再利用value_counts函数对每一个品牌的门店数量进行统计,发现星巴克旗下一共有4个品牌,其中Starbucks门店数量最多,达到了25249家。
打印出全世界一共有多少个国家开设了星巴克门店,显示门店数量排名前5和后10的国家。
country_num = len(data['Country'].unique())
print('全国一共有%d个国家开设了星巴克门店'%country_num)

接着利用groupby函数对’country‘进行分组聚合,统计门店数量前五的国家,降序排列
dff = data.groupby(["Country"]).size().reset_index()
dff.columns = ['country','number']
dff.sort_values(by = ['number'],ascending = False).head()

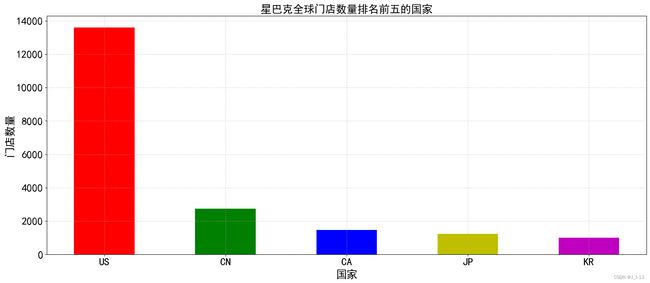
果不其然,星巴克的门店数量在美国最多,达到了13608家,是第二名中国的近6倍之多。我们将其可视化为图表显得更为清晰明了。
plt.figure(figsize=(20,8))
plt.bar(top_5.index,top_5,width=0.5,color=['r','g','b','y','m'])
plt.xlabel('国家',fontsize = 20)
plt.ylabel('门店数量',fontsize = 20)
plt.xticks(fontsize = 20)
plt.yticks(fontsize = 20)
plt.grid(linestyle = '--',alpha = 0.5)
plt.title('星巴克全球门店数量排名前五的国家',fontsize = 20)
plt.show()
- 全球门店数量最少的十个国家
我们在探究了全球门店数量最多的几个国家之后,也来看看星巴克在哪一些国家的门店数量最少
plt.figure(figsize=(20,8))
plt.bar(tail_10.index,tail_10,color = 'brown')
plt.xlabel('国家',fontsize = 20)
plt.ylabel('门店数量',fontsize = 20)
plt.xticks(fontsize = 20)
plt.yticks(fontsize = 20)
plt.title('星巴克全球门店数量最少十个国家',fontsize = 20)
plt.show()

据上图可见,在AD、LU、MC这三个国家的门店数量最少,在AD国家仅仅只有一家门店
显示拥有星巴克门店数量排名前10的城市
在查看了拥有门店数量最多的国家后,我们在再来探究星巴克在全球门店数量最多的10个城市并可视化展示
len(data['City'].unique())
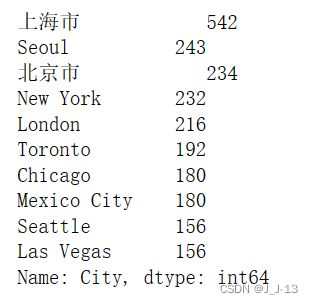
city_count = data['City'].value_counts().head(10)
city_count
plt.figure(figsize=(20,8))
plt.bar(city_count.index,city_count)
plt.xlabel('城市',fontsize = 15)
plt.ylabel('门店数量',fontsize = 15)
plt.xticks(fontsize = 15)
plt.yticks(fontsize = 15)
plt.title('星巴克全球门店数量排名前十的城市',fontsize = 20)
plt.show()

我们发现,竟然全球门店数量最多的城市是在上海,有542家,不愧是魔都,第二名和第三名是首尔和我们的首都北京,二者数量都差不多。第10名西雅图,是星巴克总部所在地,除了这个原因,也许西雅图程序员也贡献了不少营业额
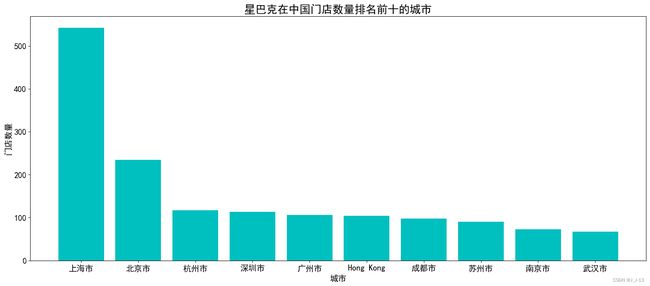
按照星巴克门店在中国的分布情况,统计排名前10的城市
df = data[data['Country'] =='CN'] #先把中国的门店数据提取出来
df2 = df.groupby(["City"]).size().reset_index()# 利用groupby分组聚合
df2.columns = ['city','number']
df2.sort_values(by = ['number'],ascending = False).head(10)# 按各城市门店数量降序排列 取前十

毫不意外,发现星巴克在中国门店数量最多的几个城市都是国内gdp高度发达的城市,主要聚集在珠三角,长三角和北京,在这些发达城市才能支撑得起星巴克的高消费,接下来我们可视化展示一下:
plt.figure(figsize=(20,8))
plt.bar(china_city.index,china_city,color = 'c')
plt.xlabel('城市',fontsize = 15)
plt.ylabel('门店数量',fontsize = 15)
plt.xticks(fontsize = 15)
plt.yticks(fontsize = 15)
plt.title('星巴克在中国门店数量排名前十的城市',fontsize=20)
plt.show()
用饼状图显示星巴克门店的经营方式有几种
#绘制饼图
plt.figure()
plt.pie(work_style,labels=data['Ownership Type'].value_counts().index,autopct='%1.2f%%')
plt.axis('equal')
plt.legend()
plt.title('星巴克的经营方式')
plt.show()
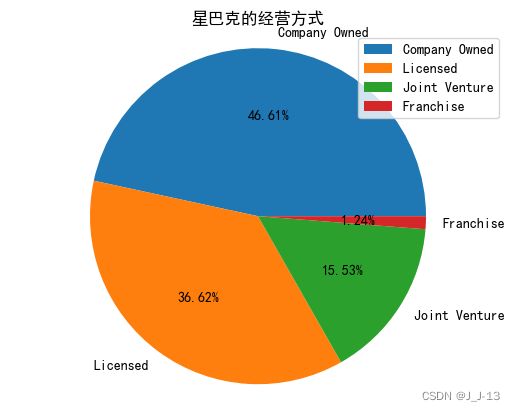
星巴克的经营方式主要为四种,其中company owned公司自主经营占了46.6%,将近一半,其次就是Licensed许可经营,占了36.6%,剩余少部分的就是Joint venture和franchise。
总结
本文按照星巴克门店的数量对国家和中国的城市进行排序,主要利用了pandas中DataFrame的groupby方法进行分组聚合,value_counts函数进行值的统计,使用DataFrame.reset_index()方法重新指定索引、sort()方法进行排序以及matplotlib库进行柱状图,饼图的绘制。