数据库分区;pgAdmin操作pgsql分区;修改pgsql数据库名字
目录
分区
什么是分区
分区的优势
pgAdmin操作pgsql分区
创建父表
创建分区
数据入库分区
扩展(按天创建分区脚本)
修改数据库名字
链接
分区
什么是分区
指将一个大的表或索引分成多个小的、独立的部分,每个部分称为一个分区,以便更好地管理和处理数据。分区是逻辑上的,不同的分区可以物理上存储在不同的磁盘上,也可以存储在同一个磁盘的不同位置。数据库分区可以通过数据库管理系统自动完成,无需手动分割数据表或索引。
举个例子:我一个大数据量的表,每天几千万的数据,为了方便管理、统计和查询,我可以按天建立分区并且把数据落入对应时间的分区,下边创建分区案例中会有具体实现。
总的来说是根据分区策略,将数据数据分散到不同的子表中,并通过父表建立关联关系,从而实现数据物理上的分区。
分区的优势
数据库分区是一种高效管理海量数据的技术手段,它可以提升数据库的性能、可用性和可维护性,极大地方便了数据库的开发和维护工作。
分区表之后可以将不同的表放置在不同的物理空间上,从而达到冷数据放在廉价的物理机器上,热点数据放置在性能强劲的机器上。
性能上通过分区表的父表查数据相对于普通的数据全量表查询效率要低。直接分区表中查询数据比在全量表中查询数据效率要高。
相比于单个创建表而不分区,我觉得分区聚合统计会比较方便一点。
pgAdmin操作pgsql分区
创建父表
找到create table

输入名字、开启分区(会提示你指定分区表key,先不管)
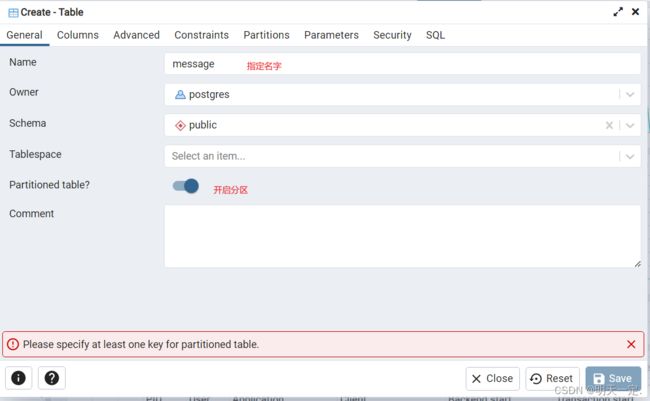
写表属性,必须包含一个分区逻辑字段,我这里以时间分区(date),(注意不能出现主键索引,否者会报错)
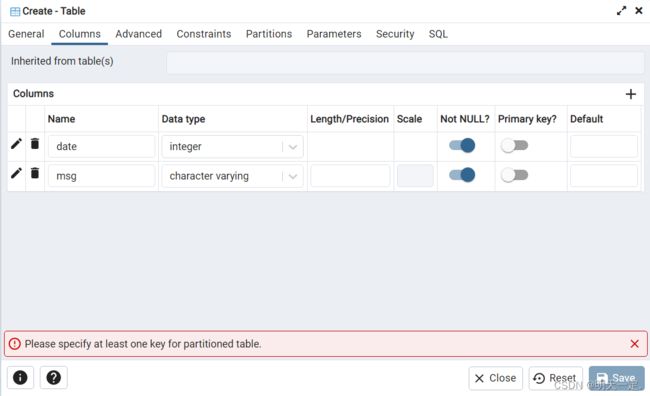
找到partitions,可以看到有三种partition type这里我是用list
- 范围(Range )分区: 表被划分为由键列或列集定义的“范围”,分配给不同分区的值的范围之间没有重叠。 例如:可以按日期范围或特定业务对象的标识符范围,来进行分区。
- 列表(List)分区: 通过显式列出哪些键值出现在每个分区中来对表进行分区。
- 哈希(Hash)分区: (自PG11才提供HASH策略)通过为每个分区指定模数和余数来对表进行分区。 每个分区将保存行,分区键的哈希值除以指定的模数将产生指定的余数。
keyType类型有两种:列和表达式,我选择列
collation排序规则(用于指定表格列中的字符串数据排序方式)我没选
operator class操作符类我没选
下边的partitions框就是创建具体分区的,我们先不创建,先创建父表
可以预览一下sql,毕竟不能只会用pgadmin可视化操作,保存结束

创建分区
找到刚才创建的父表,打开属性,找到分区(partitions),因为我们使用的list的类型,所以指定in字段即可
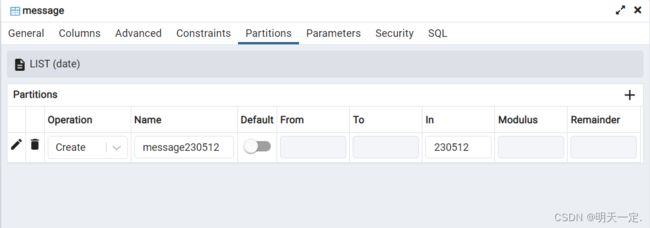
保存后就可以看到已经出现了分区
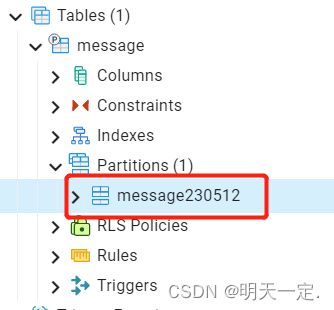
数据入库分区
很简单的案例
插入的时候一定要指定你的分区列,比如我上边创建分区是in=230512,那么我想插入或查询这个分区的时候一定要携带分区列=230512的条件,剩下的交给数据库给你逻辑插入或者查询。
扩展(按天创建分区脚本)
其实在我们创建分区的时候点击最右边的sql栏位,就已经给出我们sql了

然后再结合pgagent写定时任务,方法如下
declare
currentDate varchar;
BEGIN
SELECT INTO currentDate to_char(current_date+interval '1 d', 'yymmdd');
execute 'CREATE TABLE public.message'||currentDate||' PARTITION OF public.message FOR VALUES IN ('||currentDate||')';
return currentDate;
END;
不会pgagent的可以在我文章中搜索查看
修改数据库名字
在都完成之后,leader突然说我数据库名字起的不是很好,我直接右击修改数据库名字然后得到一个报错
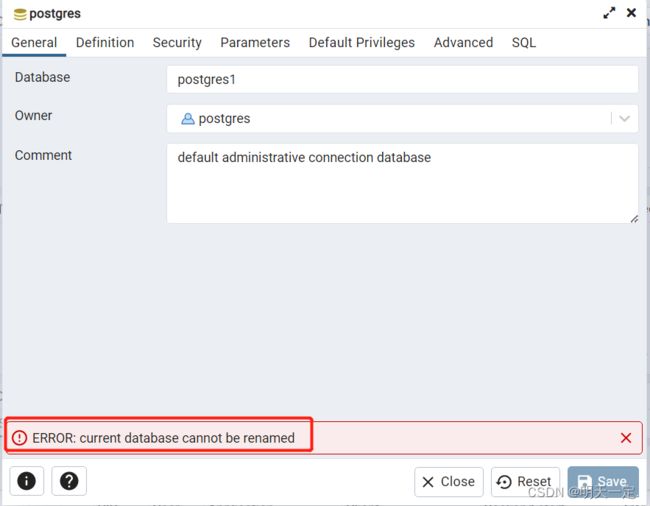
这是为什么,明明给出了修改的选项,却不让修改,这不是欺负老实人吗。
其实想想很简单,如果这个数据库被别人用着,有连接存在,你改了别人怎么办。
所以我们直接用命令行进入pgsql,找到数据库中的活动连接的pid
SELECT
pid,
usename,
application_name
FROM
pg_stat_activity
WHERE
datname = 'name';
紧接着,我们直接把他们的连接T掉(正式环境可不敢这么玩,谨慎使用),把pid全部踢掉
SELECT pg_terminate_backend(pid);
最后执行修改数据库名的语句
ALTER DATABASE test_db RENAME TO test_new_db;
链接
PostgreSQL 教程 (sjkjc.com)