爬虫基础使用
爬虫基础
@人间
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、爬虫是什么?
概念:爬虫是指请求网站并获取数据的自动化程序,又称网页蜘蛛或网络机器,最常用领域是搜索引擎,它的基本流程是明确需求-发送请求-获取数据-解析数据-存储数据。
学习内容:
爬虫的基本使用
1、 创建项目文件
2、 创建爬虫
3、 分析网页标签
4、 爬取需要信息
5、写入text
二、使用步骤
1.创建爬虫项目文件
代码如下(示例):
scrapy start project 项目名
例如: scrapy start xiaoshuo
2.创建爬虫
代码如下(示例):
scrapy genspider 爬虫名称 要爬取的网页
例如: scrapy genspider xiaoshuop book.douban.com
注意: 爬虫名称和项目名称不能一致,创建爬虫的时候需"cd"到项目 目录
总结
提示:单词字母需区分大小写
欢迎使用Scrapy爬虫
你好! 这是你第一次使用 Scrapy 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
查看命令
如果忘记代码命令,直接输入scrapy就会弹出对应的代码提示
在项目目录下的命令提示为:
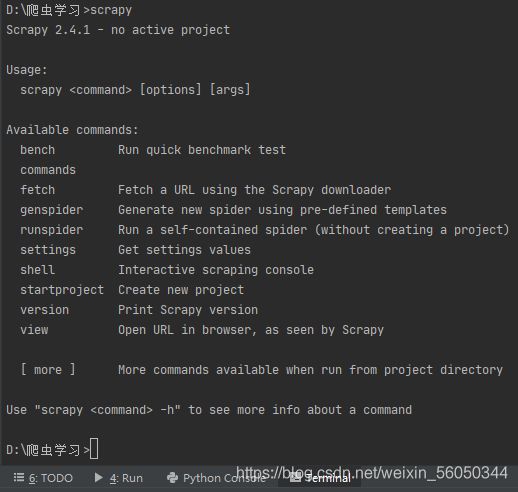
在爬虫目录下的命令提示为:
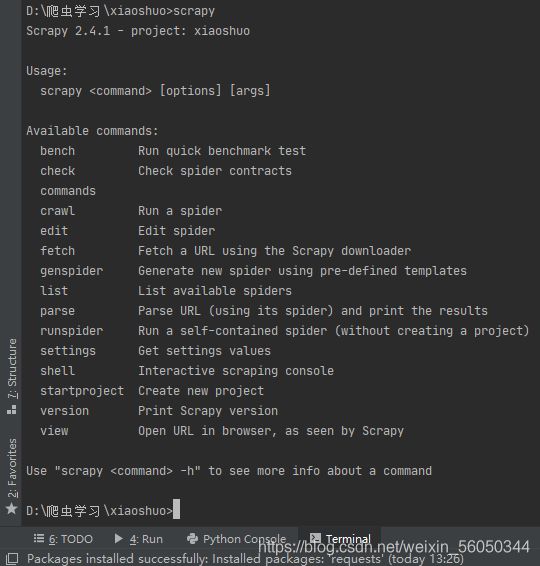
随后我们进入pycharm
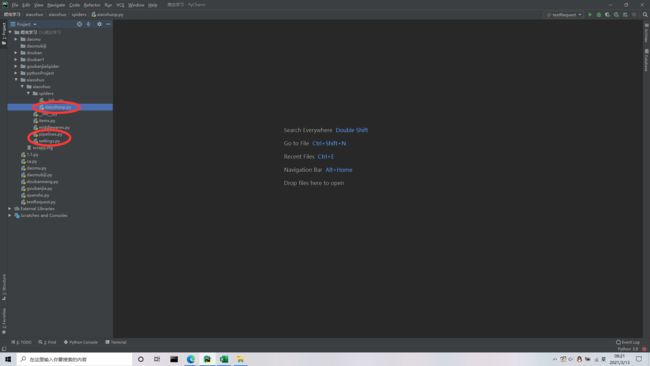
1.找到 xiaoshuo.py 文件,我们主要在这个文件里面书写爬取代码。
2.双击打开 xiaoshuo.py 并将文件将想爬取的网页的 url 地址复制粘贴到 ③ 里面。。
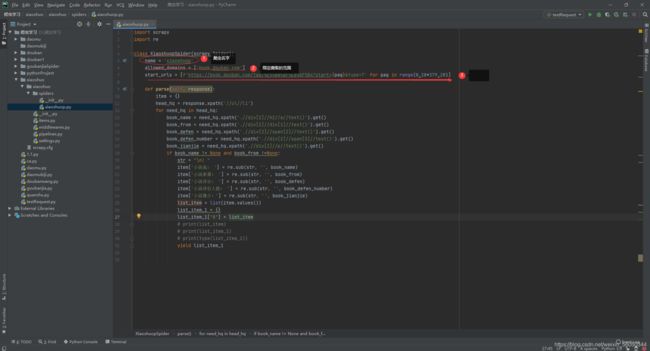
①爬虫名字。
②限定爬虫爬取的范围。
③爬取的网页 url 地址 ;这里是有多个页面 用了正则表达式。
3.打开settings.py 文件。
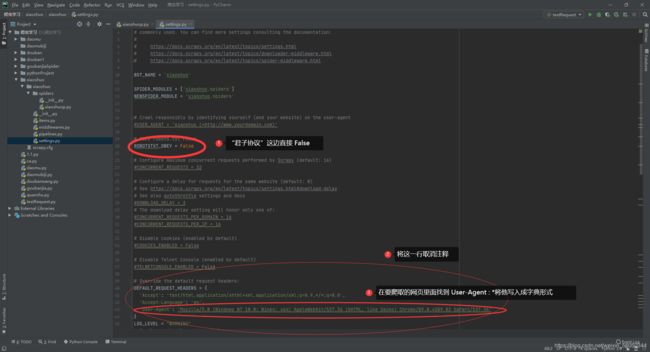
①"君子协议"这里直接Flase就行了
②将名为DEFAULT_REQUEST_HEADERS取消掉注释
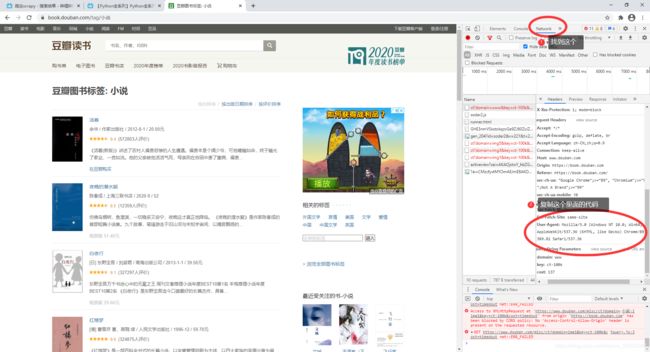
③去浏览器找到名为 NetWork 下面的 Headrs 再寻找 User-Agent 之后写入DEFAULT_REQUEST_HEADERS。
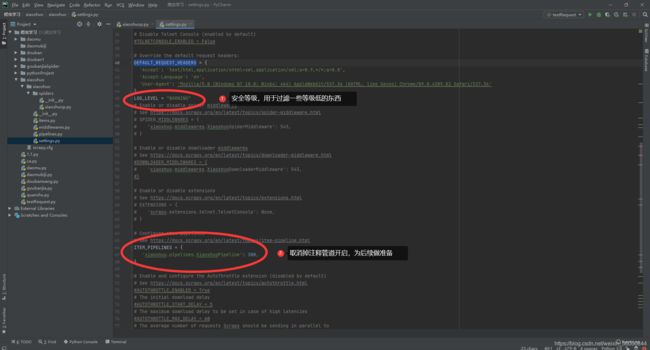
④写入安全等级过滤语句:LOG_LEVEL = “WARNING” 然后继续往下找到 ITEM_PIPELINES 并取消掉注释。
4.再次进入 xiaoshuo.py 文件,我们开始书写爬取代码。
①实列化 response 并用 .xpath 方法 和 itme{} 字典接收值,先选择大的内容,再用 for 循环遍历。
item = {}
head_hq = response.xpath('选择标签')
例如
item = {}
head_hq = response.xpath('//ul//li')
for need_hq in head_hq:
book_name = need_hq.xpath('.//div[2]//h2//a//text()').get()
book_from = need_hq.xpath('.//div[2]//div[1]//text()').get()
book_defen = need_hq.xpath('.//div[2]//span[2]//text()').get()
book_defen_number = need_hq.xpath('.//div[2]//span[3]//text()').get()
book_jianjie = need_hq.xpath('.//div[2]//p//text()').get()
if book_name != None and book_from !=None:
str = "\n| "
item['小说名: '] = re.sub(str, '', book_name)
item['小说来源: '] = re.sub(str, '', book_from)
item['小说评分: '] = re.sub(str, '', book_defen)
item['小说评价人数: '] = re.sub(str, '', book_defen_number)
item['小说简介:'] = re.sub(str, '', book_jianjie)
list_item = list(item.values())
list_item_1 = {}
list_item_1["0"] = list_item
# print(list_item)
# print(list_item_1)
# print(type(list_item_1))
yield list_item_1
注意:再传递值的值时候只能传入 字典 。
5.进入pipelines 文件,进行将爬取到的数据写入文档操作。
① 注意 list_item_1 变量名要和之前 yield {} 过来的变量名一样。
class XiaoshuoPipeline:
def process_item(self, list_item_1, spider):
return list_item_1
x = list_item_1["0"]
xx = "\t".join(x) + "\n"
③ 进行字符串 with open() 操作和 writ() 操作。
with open("3.text", "r+", encoding="utf-8") as wenjian:
print(xx)
wenjian.write(xx)
总结
提示:这里对文章进行总结: