ARM平台搭建Hadoop 3.3.0 集群
2020年6月的苹果WWDC大会上,苹果正式公布了基于ARM架构的自研Mac芯片计划,使用ARM芯片的Mac不久就将与大家见面;而早在2019年Q1,华为已经发布了用于数据中心的ARM架构处理器鲲鹏920,并在华为云上上线相应的资源,性价比大幅领先同级X86产品;AWS也在随后发布了自研的基于ARM架构的Graviton2芯片并同时提供了相应的虚拟机资源。可以看到,在通用处理器市场,由于性价比方面的巨大优势,已经有越来越多的厂商开始转向ARM架构。
有了硬件之后,有多少软件能够平稳的运行在这些硬件平台上,就成了用户们最关心的问题。开源软件作为影响整个行业的风向标,领域中最主流的开源软件能否在硬件平台上跑起来、跑得好对硬件平台在该领域的生态发展起到决定性的作用。因此国内(华为、麒麟等)外(ARM、Linaro等)各公司的开发者在从底层的基础库、加速库到IAAS、PAAS平台,再到大数据、数据库等业务软件的各主流开源社区进行大力投入,目前也以及取得了一些关键成果。
大数据作为目前最主要的业务领域之一,对数据中心硬件的软件生态发展有着重要意义,因此也吸引了众多开发者的重点关注。Hadoop作为开源大数据领域的最核心项目,也成为了各公司重点投入的方向。经过半年的开发和推动,2020年7月14日,Hadoop发布了3.3.0版本,除了众多新功能之外,在其release note中(https://hadoop.apache.org/docs/r3.3.0/index.html)最显著位置还声明了该版本是Hadoop发布的首个官方支持ARM架构的版本。
本文将记录实际安装步骤以及过程中发现的问题,安装完成后将运行几个常见的任务,验证功能性。
1. 下载
Hadoop 3.3.0版本发布后,在项目的下载页面(https://hadoop.apache.org/releases.html)增加了相应的连接,用户可以非常方便的进行下载:

我们的机器为ARM架构的鲲鹏920 CPU,因此下载binary-aarch64软件包:
P.S. util-linux需要升级到最新版本才lscpu功能才能够正常解析CPU具体信息,否则以编码形式呈现

下载:

解压:
tar -xzvf hadoop-3.3.0-aarch64.tar.gz
cd hadoop-3.3.0/2. 配置Hadoop Core和HDFS
Hadoop支持多种部署方式,我们这里使用伪分布式(Pseudo-Distributed)模式进行部署,以便完整的验证HDFS、YARN、Mapreduce三个部分的功能。
首先修改Hadoop-core和HDFS的配置文件:
etc/hadoop/core-site.xml:
fs.defaultFS
hdfs://localhost:9000
etc/hadoop/hdfs-site.xml:
dfs.replication
1
虽然是伪集群式部署模式,各组件间的交互仍然是会使用SSH调用的,为了能够正常相互访问,需要配置本机自己的免密SSH访问:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys通过下面命令检查是否配置成功:
ssh localhost首先导入JAVA_HOME环境变量,具体路径需要根据自己系统的实际情况进行配置,同时通过Hadoop自带脚本启动Hadoop服务时要将环境变量导入到相应的脚本中:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64/
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64/" >> etc/hadoop/hadoop-env.sh初始化文件系统:
bin/hdfs namenode -format启动Namenode和Datanode服务:
sbin/start-dfs.sh在HDFS中创建文件目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/2.配置YARN
经过上面的配置,以及能够在本地运行MapReduce任务了,为了完整的验证功能,我们还需要配置YARN。
首先,对下面的这些文件进行配置:
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
启动ResourceManager和NodeManager守护进程:
sbin/start-yarn.sh至此,整个安装配置就完成了,可以从 http://localhost:9870/ 和 http://localhost:8088/ 查看HDFS和YARN的管理界面。
3.测试
接下来我们进行一些简单的测试,验证一下Hadoop在ARM架构上的基本功能是否能够正常使用:
1)Wordcount
wordcount是大数据领域的Hello World,运行一个统计文件中单词出现次数的程序,可以用来验证Hadoop集群的基本功能。
首先,在HDFS中创建input命令:
bin/hadoop fs -mkdir /input可以通过 bin/hadoop fs -ls / 检查上面命令的结果:

统计单词出现的频率需要一个文档作为输入,本目录下的LICENSE.txt就是一个很适合作为输入的文本文件,我们将它上传到HDFS系统中:
bin/hadoop fs -put LICENSE.txt /input可以通过 bin/hadoop fs -ls /input 检查上面命令的结果:

接下来使用Hadoop自带的wordcount示例程序来计算其中单词的出现频率:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output具体结果如下:
 ...
...
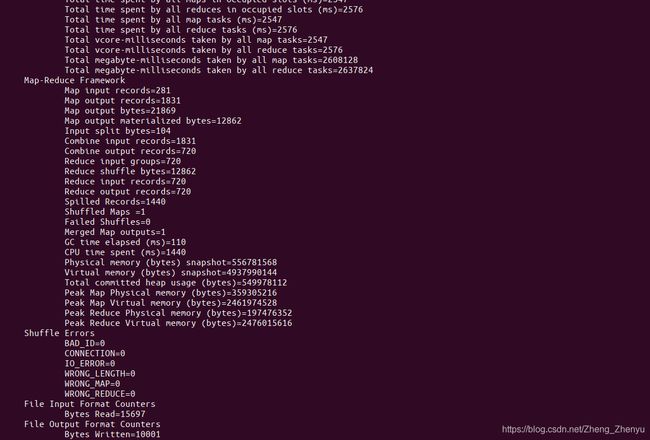
通过 bin/hadoop fs -ls / 命令可以看到,HDFS系统中多了 /output 和 /tmp 目录

打开/output命令可以看到有两个文件

打开part-r-00000查看结果:

可以看到,wordcount成功运行了。
2)TeraSort
TeraSort是Hadoop中的的一个排序作业,经常被用来进行性能比拼等测试。TeraSort源码包含很多个java文件,其中可以分为三个部分:TeraGen, TeraSort和TeraValidate。 TeraGen负责生成排序所需的随机数据,TeraSort负责进行排序作业,TeraValidate用来验证排序结果。下面我们就在我们的集群上进行TeraSort测试。
首先,我们用TeraGen生成5GB的测试数据作为输入,由于TeraSort内部以行为单位进行数据生成,每一行的大小为100B,因此需要提前计算好所需要的行数,然后使用Hadoop自带的TeraGen生成相应的测试数据:
rows=$((5*1024*1024*1024/100))
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar teragen -Dmapred.map.tasks=100 ${rows} terasort/tera1-input通过 bin/hadoop fs -ls /user/kevin/terasort 命令查看结果
![]()
接下来对测试数据进行排序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar terasort -Dmapred.reduce.tasks=50 terasort/tera1-input terasort/tera1-output通过 bin/hadoop fs -ls /user/kevin/terasort/tera1-output 命令查看结果
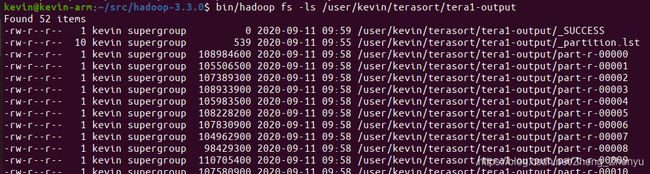
最后,通过TeraValidate来来检验排序输出结果是否是有序的:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar teravalidate terasort/tera1-output terasort/tera1-validate4.总结
Hadoop 3.3.0版本提供了ARM版本的软件包,用户从项目官网上下载后只需要经过简单的配置,就可以完成部署,运行Wordcount,TeraSort等实例程序没有出现问题。后续会继续进行更复杂的业务测试以及性能测试。