docker网络原理及cgroup
docker网络模式的特性
docker初始状态下有三种默认的网络模式 ,bridg(桥接),host(主机),none(无网络设置)
网络模式 配置 说明
host//主机模式 –network host 容器和宿主机共享网络命名空间
container//容器模式 –network container:容器的id或者名字 容器与指定的容器共享网络命名空间
none//无网络模式 –network none 容器拥有独自的网络命名空间,但是没有任何设置
bridge//桥接模式 –network bridge 容器拥有独自的网络命名空间,且拥有独立的IP,端口,路由等,使用veth pair 连接docker0 网桥,并以docker0网桥为网关
host主机模式
相当于Vmware中的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离 文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、iptable规则等都与其他的Network Namespacel隔离。一个Docker容器一 般会分配一个独立的Network. Namespace。
但如果启动容器的时候使用host模式, 那么这个容器将不会获得一 个独立的Network Namespace,而是和宿主机共用一个Network Namespace。 容器将不会虚拟出自己的网卡、配置自己的IP等,而是使用宿主机的IP和端口。
容器和宿主机共享网络命名空间,但没有独立IP地址,使用宿主机的IP地址,和宿主机共享端口范围,例如宿主机使用了80端口,那么容器不能使用80端口。这种模式比较方便,但不安全。 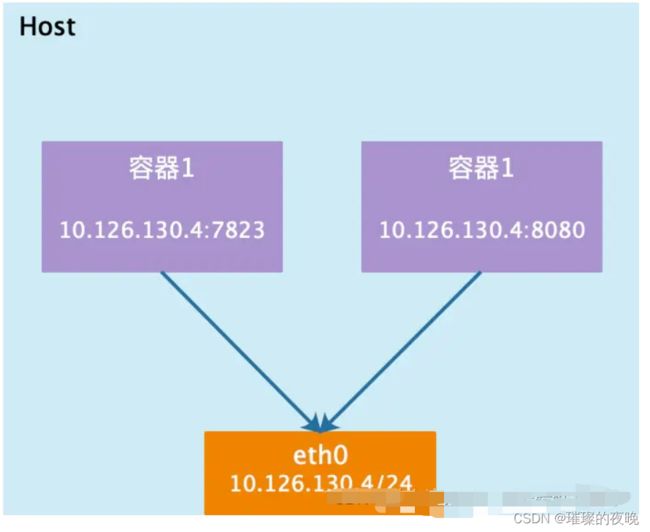
container模式
在理解了host模式后,这个模式也就好理解了。这个模式指定新创建的容器和已经存在的一个容器共享一个Network Namespace,而不是和宿主机共享。 新创建的容器不会创建自己的网卡,配置自己的Ie,而是和一个指定的容器共享re、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过lo网卡设备通信。
none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个locker容器没有网卡、iP、路由等信息。这种网络模式下容器只有lo回环网络,没有其他网卡、这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
bridge 桥接模式
bridge模式是docker的默认网络模式,不用--net参数,就是bridge模式。
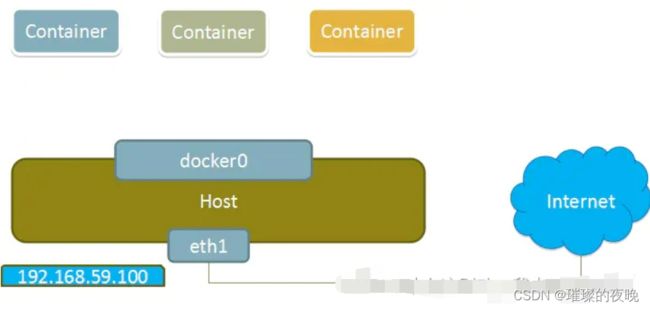
相当于Vmware中的 nat模式,容器使用独立.network Namespace,并连接到docker)虚拟网卡。通过dockerO网桥以及iptables
nat表配置与宿主机通信,此模式会为每一个容器分配hetwork Mamespace、设置等,并将一个主机上的 Docker容器连接到一个虚拟网桥上。
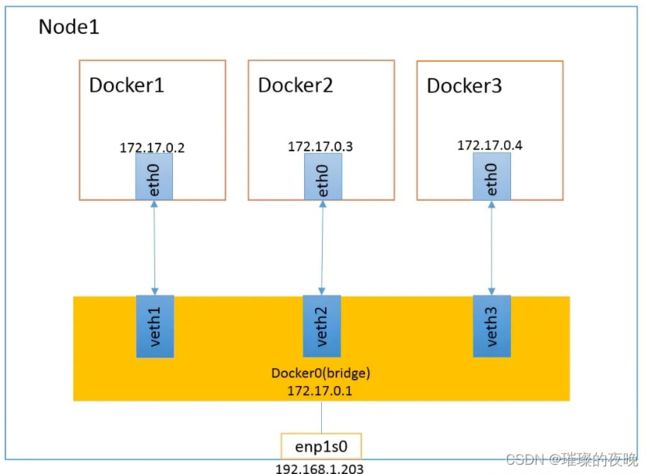
(1)当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Dokcer容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
(2)从docker0子网中分配一个IP给容器使用,并设置dockerO的I地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备。veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来、因此,veth设备常用来连接两个网络设备。
(3 ) Docker将 veth pair 设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以veth*这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过 brctl show命令查看。
(4) 使用docker run -p 时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
Docker容器的资源控制
Docker通过Cgroup 来控制容器使用的资源配额,包括CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。Caroup 是ControlGroups的缩写,是Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如 cpu、内存、磁盘,io等等)的机制,被LXC、docker等很多项目用于实现进程资源控制。Cgroup本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O或内存的分配控制等具体的资源管理是通过该功能来实现的。
cgroups,是一个非常强大的 linux 内核工具,他不仅可以限制被 namespace 隔离起来的资源,还可以为资源设置权重、计算使用量、操控进程启停等等。所以 cgroups(Control groups)实现了对资源的配额和度量。
cgroups 有四大功能
资源限制:可以对任务使用的资源总额进行限制
优先级分配:通过分配的 cpu 时间片数量以及磁盘 IO 带宽大小,实际上相当于控制了任务运行优先级
资源统计:可以统计系统的资源使用量,如 cpu 时长,内存用量等
任务控制:cgroup 可以对任务执行挂起、恢复等操作
cpu的使用率上限
Linux通过CFS (Completely Fair Scheduler,完全公平调度器)来调度各个进程对ceu的使用。CFS默认的调度周期是100ms 。我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少CPU时间。
cgroups实现方式及工作原理
在对cgroups规则和自通有一定了解以后,下面简单介绍操作系统内核级别上cgroups的工作原理,希望能有助于读者理解cgroups如何对Docker容器中的进程产生作用。
cgroups的实现本质上是给任务挂上钩子,当任务运行的过程中涉及某种资源时,就会触发钩子上所附带的子系统进行检测,根据资源列别不同,使用对应的技术进行资源限制和优先级分配。
cgroups如何判断资源超限及超出限额后的措施
对于不同的系统资源,cgroups提供了统一的接口对资源进行控制和统计,但限制的具体方式则不尽相同。比如memorary子系统,会描述内存状态的“mm_struct”结构体中记录它所属的cgroup,当进程需要申请更多内存时,就会触发cgroup用量检测,用量超过cgroup规定的限额,则拒绝用户的内存申请,否则就给予相应内存并在cgroup的统计信息中记录。实际实现要比上述描述复杂的多,不仅需要考虑内存的分配和回收,还需要考虑不同类型的内存如cache和swap等。
进程所需的内存超过它所属的cgroup最大限额以后,如果设置了OOM Control(内存超限控制),那么进程就会收到OOM信号并结束;否则进程就会被挂起,进入睡眠状态,进入睡眠状态,直到cgroup中其他进程释放了足够的内存资源为止。Docker中默认是开启OOM Control的。其他子系统的实现与此类似,cgroups提供了多种资源限制的策略供用户选择。
cgroup与任务之间的关联关系
实现上,cgroup与任务之间是多对多关系,所以它们并不直接关联,而是通过一个中间结构把双向的关联信息记录起来。每个任务结构体tsak_struct中都包含了一个指针,可以查到对应的cgroup的情况,同时也可以查询到各个子系统的状态,这些子系统状态中也包含了找到任务的指针,不同类型的子系统按需定义本身的控制信息结构体,最终在地定义的结构体中吧子系统状态指针包含进去,然后内核通过container_of(这个宏可以通过一个结构体的成员找到结构体自身)等宏定义来获取对应的结构体,关联到任务,从此达到资源限制的目的。同时,为了让cgroups便于用户理解和使用,也为了用精简的内核代买为cgroup提供熟悉的权限和命名空间管理,内核开发者们按照Linux虚拟文件转化器(Virtual Filesystem Switch,VFS)接口实现了一套名为cgroup的文件系统,非常巧的用来表示cgroups的层级概念,把各个子系统的实现都疯撞到文件系统的各项操作中。
Docker在使用cgroup时的注意事项
在实际使用过程中,Docker需要通过挂载cgroup文件系统新建一个层级结构,挂载时指定要绑定的子系统。把cgroup文件系统挂载上以后,就可以像操作文件一样对cgroup的层级进行浏览和操作管理(包括权限管理、子文件管理等)。除了cgroup文件系统以外,内核没有为cgroups的访问和操作添加任何系统调用。
/sys/fs/cgroup/cpu/docker/下文件的作用
前面已经说过,以资源开头的文件都是用来限制这个cgroup下任务的可用配置文件。
一个cgroup创建完成,不管绑定了何种子系统,其目录下都会生成以下几个文件,用来描述cgroup的相应信息。同样,把相应信息写入这些配置文件中就可以生效。
本文由浅入深的讲解了cgroups,从cgroups是什么,到cgroups要怎么用,最后对大量的cgroup子系统进行了讲解。可以看到内核对cgroups的支持已经较多,但是依旧有许多工作要完善。如网络方面目前通过TC(Traffic Controller)来控制,未来需要统一整合;由县级调度方面依旧有很大的改进空间。
CPU资源的控制也有两种策略,
一种是完全公平调度 (CFS:Completely Fair Scheduler)策略,提供了限额和按比例分配两种方式进行资源控制;
另一种是实时调度(Real-Time Scheduler)策略,针对实时进程按周期分配固定的运行时间。配置时间都以微秒(µs)为单位,文件名中用us表示。
CFS调度策略下的配置
设定CPU使用周期使用时间上限
cpu.cfs_period_us:设定周期时间,必须与cfs_quota_us配合使用。
cpu.cfs_quota_us :设定周期内最多可使用的时间。这里的配置指task对单个cpu的使用上限,若cfs_quota_us是cfs_period_us的两倍,就表示在两个核上完全使用。数值范围为1000 - 1000,000(微秒)。
cpu.stat:统计信息,包含nr_periods(表示经历了几个cfs_period_us周期)、nr_throttled(表示task被限制的次数)及throttled_time(表示task被限制的总时长)。
按权重比例设定CPU的分配
cpu.shares:设定一个整数(必须大于等于2)表示相对权重,最后除以权重总和算出相对比例,按比例分配CPU时间。(如cgroup A设置100,cgroup B设置300,那么cgroup A中的task运行25%的CPU时间。对于一个4核CPU的系统来说,cgroup A 中的task可以100%占有某一个CPU,这个比例是相对整体的一个值。)
RT调度策略下的配置 实时调度策略与公平调度策略中的按周期分配时间的方法类似,也是在周期内分配一个固定的运行时间。
cpu.rt_period_us :设定周期时间。
cpu.rt_runtime_us:设定周期中的运行时间。
cpuacct资源报告
这个子系统的配置是cpu子系统的补充,提供CPU资源用量的统计,时间单位都是纳秒。
cpuacct.usage:统计cgroup中所有task的cpu使用时长
cpuacct.stat:统计cgroup中所有task的用户态和内核态分别使用cpu的时长
cpuacct.usage_percpu:统计cgroup中所有task使用每个cpu的时长
cpuset
为task分配独立CPU资源的子系统,参数较多,这里只选讲两个必须配置的参数,同时Docker中目前也只用到这两个。
cpuset.cpus:可使用的CPU编号,如0-2,16代表 0、1、2和16这4个CPU
cpuset.mems:与CPU类似,表示cgroup可使用的memory node,格式同上,NUMA系统使用
device ( 限制task对device的使用)
设备黑/白名单过滤
devices.allow:允许名单,语法type device_types:node_numbers access type ;type有三种类型:b(块设备)、c(字符设备)、a(全部设备);access也有三种方式:r(读)、w(写)、m(创建)
devices.deny:禁止名单,语法格式同上
统计报告
devices.list:报告为这个 cgroup 中的task设定访问控制的设备
freezer - 暂停/恢复cgroup中的task
只有一个属性,表示进程的状态,把task放到freezer所在的cgroup,再把state改为FROZEN,就可以暂停进程。不允许在cgroup处于FROZEN状态时加入进程。freezer.state 包括如下三种状态:
- FROZEN 停止
- FREEZING 正在停止,这个是只读状态,不能写入这个值。
- THAWED 恢复
memory (内存资源管理)
memory.limit_bytes:强制限制最大内存使用量,单位有k、m、g三种,填-1则代表无限制
memory.soft_limit_bytes:软限制,只有比强制限制设置的值小时才有意义
memory.memsw.limit_bytes:设定最大内存与swap区内存之和的用量限制
memory.oom_control: 0表示开启,当cgroup中的进程使用资源超过界限时立即杀死进程。默认包含memory子系统的cgroup都启用。当oom_control不启用时,实际使用内存超过界限时进程会被暂停直到有空闲的内存资源
统计
memory.usage_bytes:报告该 cgroup中进程使用的当前总内存用量(以字节为单位)
memory.max_usage_bytes:报告该 cgroup 中进程使用的最大内存用量
memory.failcnt:报告内存达到在 memory.limit_in_bytes设定的限制值的次数
memory.stat:包含大量的内存统计数据。
cache:页缓存,包括 tmpfs(shmem),单位为字节。
rss:匿名和 swap 缓存,不包括 tmpfs(shmem),单位为字节。
mapped_file:memory-mapped 映射的文件大小,包括 tmpfs(shmem),单位为字节
pgpgin:存入内存中的页数
pgpgout:从内存中读出的页数
swap:swap 用量,单位为字节
active_anon:在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
inactive_anon:不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
active_file:活跃 LRU 列表中的 file-backed 内存,以字节为单位
inactive_file:不活跃 LRU 列表中的 file-backed 内存,以字节为单位
unevictable:无法再生的内存,以字节为单位
hierarchical_memory_limit:包含 memory cgroup 的层级的内存限制,单位为字节
hierarchical_memsw_limit:包含 memory cgroup 的层级的内存加 swap 限制,单位为字节
Docker: 限制容器可用的 CPU
通过 --cpus 选项指定容器可以使用的 CPU 个数,这个还是默认设置了cpu.cfs_period_us(100000)和cpu.cfs_quota_us(200000)
实验:
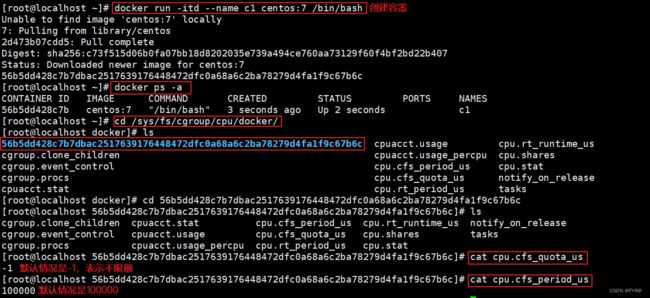
docker run -itd --name c1 centos:7 /bin/bash
docker ps -a
cd /sys/fs/cgroup/cpu/docker/容器的ID号/
cat cpu.cfs_quota_us #默认情况是-1,表示不限额
cat cpu.cfs_period_us #默认情况是100000
docker ps -a
docker exec -it c1 bash
vi /cpu.sh
#!/bin/bash
i=0
while true
do
let i++;
done
chmod +x /cpu.sh ./cpu.sh

————————————————
版权声明:本文为CSDN博主「FYR@」的原创文章
原文链接:https://blog.csdn.net/FYR1018/article/details/125603891
本文为CSDN博主「张忠琳」的原创文章,遵循CC 4.0 BY-SA版权协议,
原文链接:https://blog.csdn.net/zhonglinzhang/article/details/64905759
本文为CSDN博主「站在这别动,我去给你买橘子」的原创文章
原文链接:https://blog.csdn.net/qq_62462797/article/details/127975686