Pytorch学习三——使用不同的模型实现分类并查看效果
1.简单的全连接神经网络
from torch import nn
class simpleNet(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(simpleNet,self).__init__()
self.layer1 = nn.Linear(in_dim,n_hidden_1)
self.layer2 = nn.Linear(n_hidden_1,n_hidden_2)
self.layer3 = nn.Linear(n_hidden_2,out_dim)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
2.添加激活函数的卷积神经网络
# 添加激活函数的卷积神经网络
# nn.Sequentila() 这个函数可以将网络的层组合到一起
class Activatoin_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Activatoin_Net,self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim,n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2,out_dim)
)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x3.添加批标准化的全连接网络
class Batch_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Batch_Net,self).__init__()
self.layer1 = nn.Sequential(
nn.Linear(in_dim,n_hidden_1),
nn.BatchNorm1d(n_hidden_1),
nn.ReLU(True)
)
self.layer2 = nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),
nn.BatchNorm1d(n_hidden_2),
nn.ReLU(True)
)
self.layer3 = nn.Sequential(
nn.Linear(n_hidden_2,out_dim)
)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
4.四层简单的神经网络
from torch import nn
net = nn.Sequential(
nn.Linear(784, 400),
nn.ReLU(),
nn.Linear(400, 200),
nn.ReLU(),
nn.Linear(200, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
5.卷积神经网络
import torch
from torch import nn
class CNN_net(nn.Module):
def __init__(self):
super(CNN_net,self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1,16,kernel_size=3), # b,16,26,26
nn.BatchNorm2d(16),
nn.ReLU(inplace = True)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16,32,kernel_size=3), # 32,24,24
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2) # 32 12,12
)
self.layer3 = nn.Sequential(
nn.Conv2d(32,64,kernel_size=3), # 64,10,10
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3), #128,8,8
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2) # 128,4,4
)
self.fc = nn.Sequential(
nn.Linear(128*4*4,1024),
nn.ReLU(inplace=True),
nn.Linear(1024,128),
nn.ReLU(inplace=True),
nn.Linear(128,10)
)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0),-1)
x = self.fc(x)
return x
### 该网络使用4层卷积,2层最大池化,卷积之后使用批标准加快收敛速度,使用ReLU激活函数增加非线性,最后使用全连接层输出分类得分
6.加载数据
import torch
from torch import nn,optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
batch_size = 64
learning_rate = 1e-1
num_epoches=20
data_tf = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])
])
train_dataset = datasets.MNIST(
root = './data',train=True,transform = data_tf,download=True
)
test_dataset = datasets.MNIST(
root = './data',train=False,transform=data_tf
)
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size = batch_size,shuffle=False)
7.使用不同的模型,并传入参数
model1 = net
model2 = simpleNet(28*28,300,100,10)
model3 = Activatoin_Net(28*28,300,100,10)
model4 = Batch_Net(28*28,300,100,10)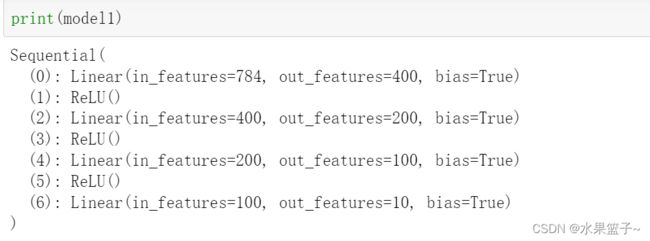

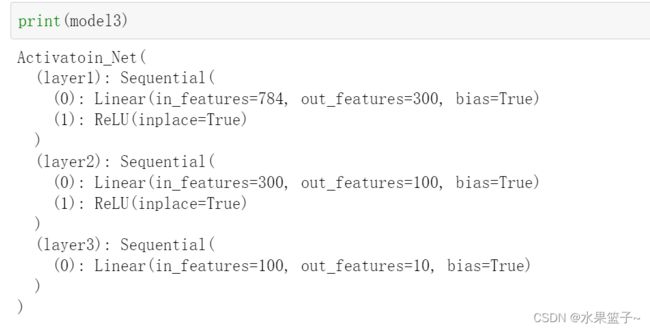

8.定义一个训练函数进行训练
def train_model(model):
if torch.cuda.is_available():
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr = learning_rate)
epoch = 20
losses = []
acces = []
eval_losses=[]
eval_acces=[]
for i in range(epoch):
train_loss = 0
train_acc = 0
model.train()
for data in train_loader:
img,label = data
img = img.view(img.size(0),-1)
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out,label)
#反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.data*label.size(0)
_,pred = torch.max(out,1)
num_correct = (pred == label).sum()
train_acc += num_correct.data
losses.append(train_loss/len(train_dataset))
acces.append(train_acc.float()/len(train_dataset))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img,label = data
img = img.view(img.size(0),-1)
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out,label)
eval_loss += loss.data*label.size(0)
_,pred = torch.max(out,1)
num_correct = (pred == label).sum()
eval_acc += num_correct.data
eval_losses.append(eval_loss / len(test_dataset))
eval_acces.append(eval_acc.float()/len(test_dataset))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(i, train_loss/len(train_dataset), train_acc.float() / len(train_dataset),
eval_loss/len(test_dataset), eval_acc.float() / len(test_dataset)))
# print('Train loss:{:.6f},Acc:{:.6f}'.format(train_loss/(len(train_dataset)),
# train_acc.float() / (len(train_dataset))))
# print('Test loss:{:.6f},Acc:{:.6f}'.format(eval_loss/(len(test_dataset)),
# eval_acc.float() / (len(test_dataset))))
return losses,acces,eval_losses,eval_acces9.记录下每一次迭代在训练集上的的损失函数、精确度和在测试集上的损失函数和精确度
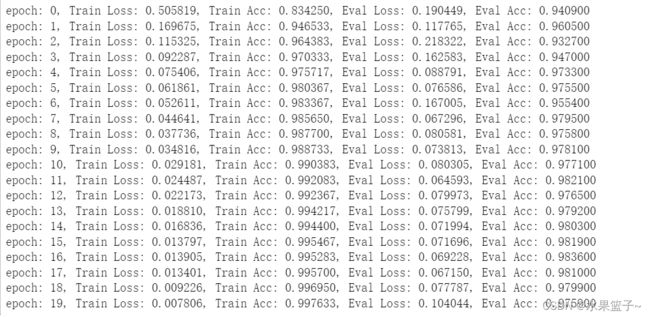
losses1,acces1,eval_losses1,eval_acces1 = train_model(model1)第一个模型迭代20次的效果如下
10.绘制损失函数和精确度的变化曲线
import numpy as np
def plot_loss(losses):
import matplotlib.pyplot as plt
%matplotlib inline
plt.title('loss')
plt.plot(np.arange(len(losses)), losses)
def plot_acc(acces):
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(np.arange(len(acces)), acces)
plt.title('acc')plot_loss(losses1)在训练集上的loss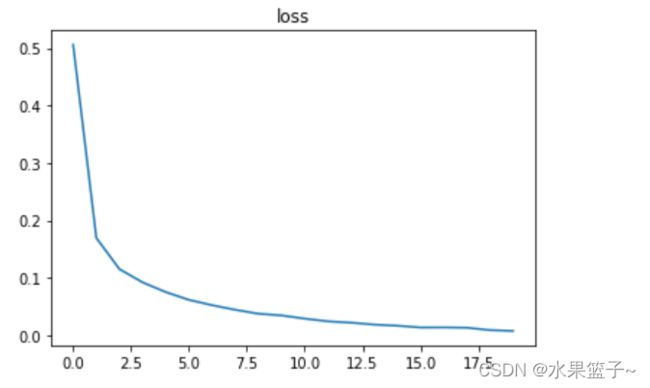
在验证集上的loss
plot_loss(eval_losses1)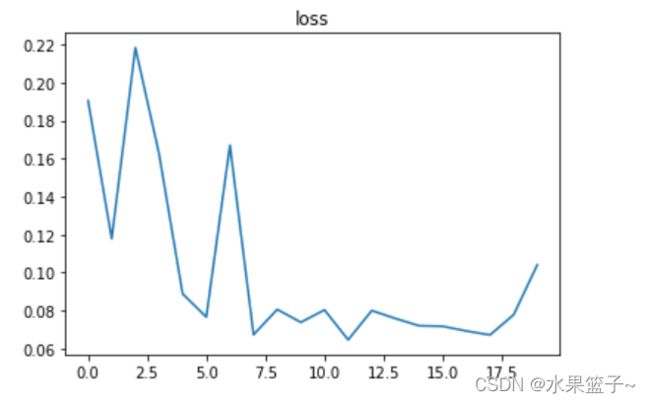
plot_acc(acces1)
在训练集上的精确度

plot_acc(eval_acces1)在测试集上的精确度

其他三个模型的绘制同理,接下来是卷积神经网络的训练模型
def train_model5(model):
if torch.cuda.is_available():
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr = learning_rate)
epoch = 20
losses = []
acces = []
eval_losses=[]
eval_acces=[]
for i in range(epoch):
train_loss = 0
train_acc = 0
model.train()
for data in train_loader:
img,label = data# 64 1,28,28
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out,label)
#反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.data*label.size(0)
_,pred = torch.max(out,1)
num_correct = (pred == label).sum()
train_acc += num_correct.data
losses.append(train_loss/len(train_dataset))
acces.append(train_acc.float()/len(train_dataset))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img,label = data
if torch.cuda.is_available():
img = Variable(img).cuda()
label = Variable(label).cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out,label)
eval_loss += loss.data*label.size(0)
_,pred = torch.max(out,1)
num_correct = (pred == label).sum()
eval_acc += num_correct.data
eval_losses.append(eval_loss / len(test_dataset))
eval_acces.append(eval_acc.float()/len(test_dataset))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(i, train_loss/len(train_dataset), train_acc.float() / len(train_dataset),
eval_loss/len(test_dataset), eval_acc.float() / len(test_dataset)))
# print('Train loss:{:.6f},Acc:{:.6f}'.format(train_loss/(len(train_dataset)),
# train_acc.float() / (len(train_dataset))))
# print('Test loss:{:.6f},Acc:{:.6f}'.format(eval_loss/(len(test_dataset)),
# eval_acc.float() / (len(test_dataset))))
return losses,acces,eval_losses,eval_acces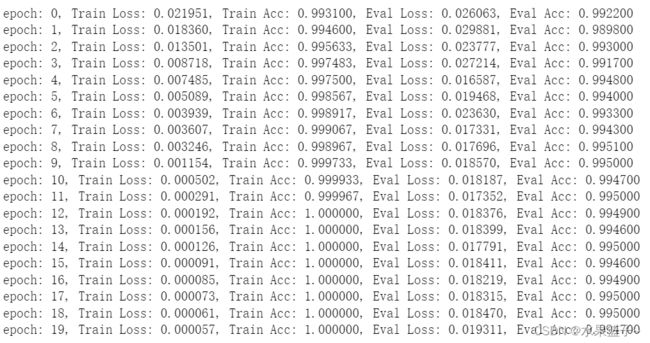
可以看出卷积神经网络能比较好的学习到其特征