A股上市公司年报链接获取(详细分析过程+成品)
1.引言
笔者之前已经写过一篇相关的文章,但代码尚不完善,这段时间也一直有读者咨询一些问题,因此专门再发一篇更加详细的帖子,欢迎大家互相交流学习。
《1.爬取A股上市公司年报链接并存入Excel》
本文更新了爬虫程序的调用接口对现有问题进行修正,主要更新如下:
- 更加全面的年报数据,突破了旧接口的2000页限制
- 内存占用更小,运行速度更快
- 封装函数,提供方便的参数修改
- 更详细的功能说明,便于二次开发
- ⭐️更完整的免费成品资源,含2022年最新年报(2003-2022年报Excel表格)
代码目前存在的问题:
- 进度显示功能存在溢出
- 若公司发布修正后的年报,代码无法去重,需手动处理
- 若干不影响主功能的小缺陷…
2.具体步骤
2.1 网页分析
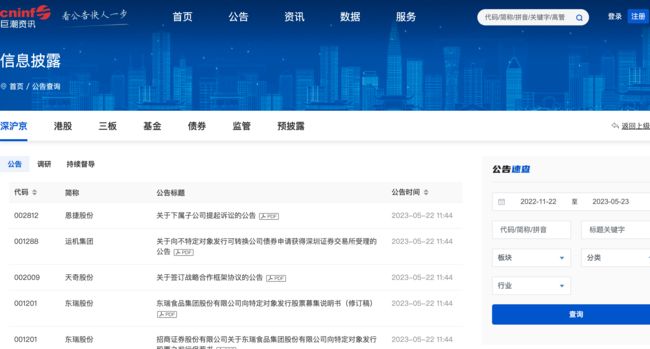 图为巨潮资讯网公告发布页面,在右侧可以选择要查询的相关参数。
图为巨潮资讯网公告发布页面,在右侧可以选择要查询的相关参数。
包括板块分类、公告类型分类、行业分类、时间范围等。
我们选择沪深两市,公告选择年报进行查询,并按公司代码进行排列,如下图所示。
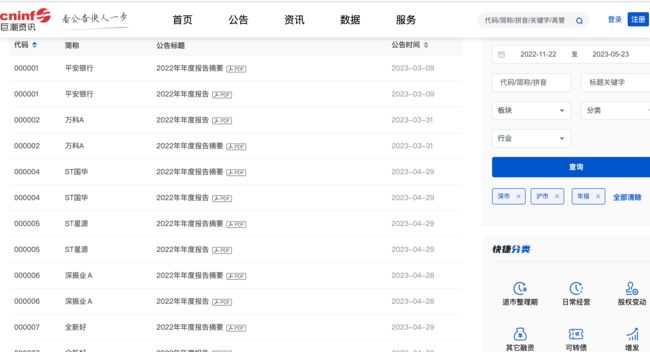
不难发现,基本已经得到了我们需要的内容,但是网站中多出了一行我们并不需要的年报摘要内容,我们在之后可以用正则表达式去除。
2.2 网络抓包
对网站内容分析完成后,就可以开始抓包。按F12打开开发者工具,切换到网络选项卡。
我们切换一下页面,发现多出了一个query请求,这就是我们需要的访问接口。
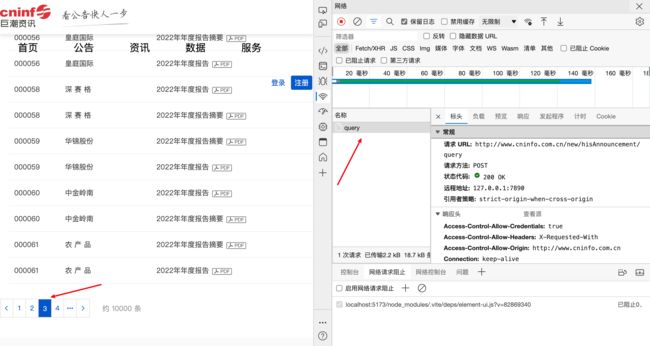
根据信息显示,这是一个POST请求,负载的参数为查询时的相关参数,我们解析一下,结果如下图所示。
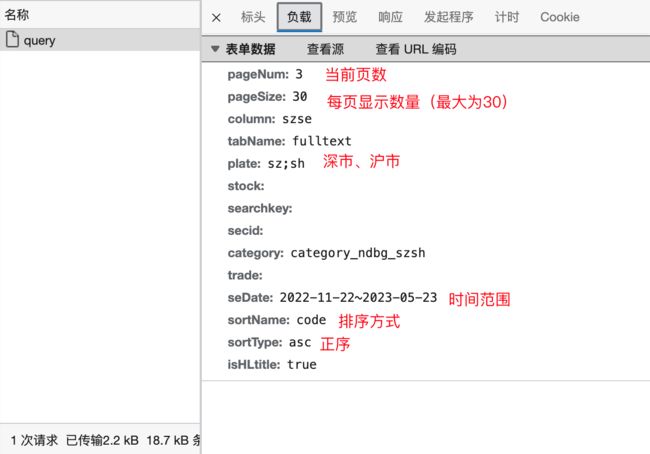
这个请求最后返回了一个json文件,包含30条公司数据,当然也包括我们需要的年报链接。
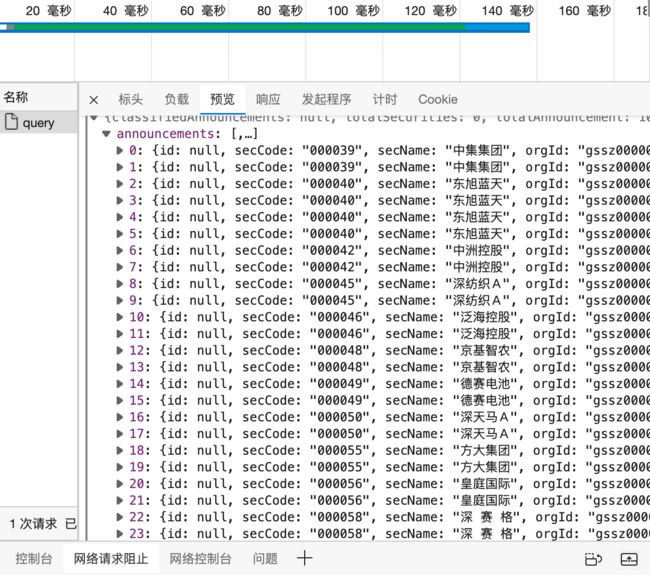
到这里基本的抓包和分析就已经完成,我们可以直接开始这部分代码的编写。
'''
@Project :PycharmProjects
@File :巨潮资讯年报2.0.py
@IDE :PyCharm
@Author :lingxiaotian
@Date :2023/5/20 12:38
'''
#首先引入第三方库
import requests
import re
import openpyxl
import time
#定义一个访问接口的函数
def get_report(page_num,date):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Content-Length": "195",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Host": "www.cninfo.com.cn",
"Origin": "http://www.cninfo.com.cn",
"Proxy-Connection": "keep-alive",
"Referer": "http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&checkedCategory=category_ndbg_szsh",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42",
"X-Requested-With": "XMLHttpRequest"
}
'''
参数信息
plate: sz;sh, 表示沪深两市
seDate:查询时间
'''
data = {
"pageNum": page_num,
"pageSize": 30,
"column": "szse",
"tabName": "fulltext",
"plate": "sz;sh",
"searchkey": "",
"secid": "",
"category": "category_ndbg_szsh",
"trade": "",
"seDate": date,
"sortName": "code",
"sortType": "asc",
"isHLtitle": "false"
}
response = requests.post(url, data=data, headers=headers)
return response
这个函数包含两个参数page_num和date,我们可以控制当前页码来遍历整个json文件,并用date来控制需要查询的时间范围。
2.3 数据获取
这部分主要就是为了实现本文的主要目的:获取指定年份的上市公司报告链接
首先我们需要循环遍历整个所有页面,那么如何确定遍历次数呢?
仔细研究返回的json文件我们发现文件最后会包含一个totalpapges的参数,即总页数。

那么,有了这个数字,我们便可以先请求一次获取总页数,从而设定好循环次数进行获取。
⚠️然而,笔者最后生成的excel表格中存在数千条重复项,对于这个问题,笔者在研究后发现该接口每次获取的页数上限最多为100页!超过这个页数后返回的内容完全一致。
从网页上看结果也是如此,最大显示范围为100页,之后便无法获取。
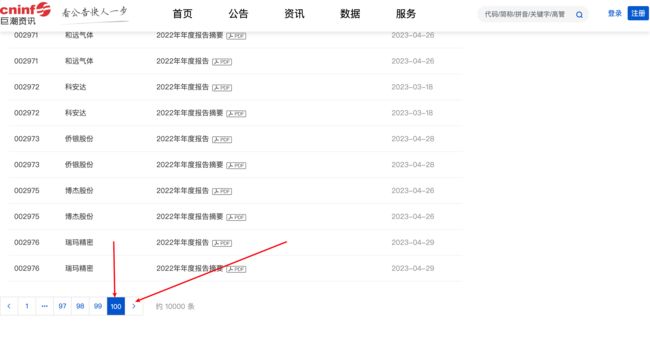
针对这一问题,笔者通过划分时间范围进行处理,稍后进行介绍,此处先给出循环访问获取数据函数的完整代码,代码中的重试机制此前已经介绍,本文不再赘述。
def downlaod_report(date):
global counter
all_results = []
page_num = 1
response_test = get_report(page_num,date)
data_test = response_test.json()
total_pages = data_test["totalpages"]
max_retries = 3 #最大重试次数
retry_count = 0 #当前重试次数
while page_num <= total_pages:
response = None
# 重试机制
while retry_count <= max_retries:
# 发送请求
try:
# response = requests.post(url, data=data,headers=headers)
response = get_report(page_num,date)
response.raise_for_status()
break
except requests.exceptions.RequestException as e:
print(f"出现错误!: {e}")
print(f"5秒后重试...")
time.sleep(5)
retry_count += 1
if retry_count > max_retries:
print(f"{max_retries} 次重试后均失败. 跳过第 {page_num}页.")
page_num += 1
retry_count = 0
continue
else:
# 解析数据
try:
data = response.json()
# print(f"正在下载第 {page_num}/{total_pages} 页")
print(f"\r正在下载第 {counter}/{sum} 页",end='')
# 尝试解析公告数据,如果解析失败则重试
retry_count = 0
while True:
try:
if data["announcements"] is None:
raise Exception("公告数据为空")
else:
all_results.extend(data["announcements"])
break
except (TypeError, KeyError) as e:
print(f"解析公告数据失败: {e}")
print(f"5秒后重试...")
time.sleep(5)
retry_count += 1
if retry_count > max_retries:
raise Exception("达到最大重试次数,跳过此页")
continue
page_num += 1
counter +=1
except (ValueError, KeyError) as e:
print(f"解析响应数据失败: {e}")
print(f"5秒后重试...")
time.sleep(5)
retry_count += 1
if retry_count > max_retries:
raise Exception("达到最大重试次数,跳过此页")
continue
return all_results
2.4 数据保存
上文我们提到,json文件的最大获取范围为100页,因此我们根据年报发布的分布特点,将每年的1月1日-4月30日作为时间范围。
然后将其细化,1-4月为一组,4月内部分为5组,保证每组获取到的总页数均小于100,并将本列表作为函数参数进行遍历,将获取到的数据汇总。
time_segments = [
f"{year}-01-01~{year}-04-01",
f"{year}-04-02~{year}-04-15",
f"{year}-04-16~{year}-04-22",
f"{year}-04-23~{year}-04-26",
f"{year}-04-27~{year}-04-28",
f"{year}-04-29~{year}-04-30"
]
既然已经获取到了所有数据,我们不可能将所有数据直接保存为不易阅读的json那么接下来就是将得到的数据进行解析。
我们首先分析了json文件中的具体参数,选择解析如图所示的几个变量,包括股票代码,公司名称,报告名称,年报链接等内容,并将年报链接拼串补充完整。
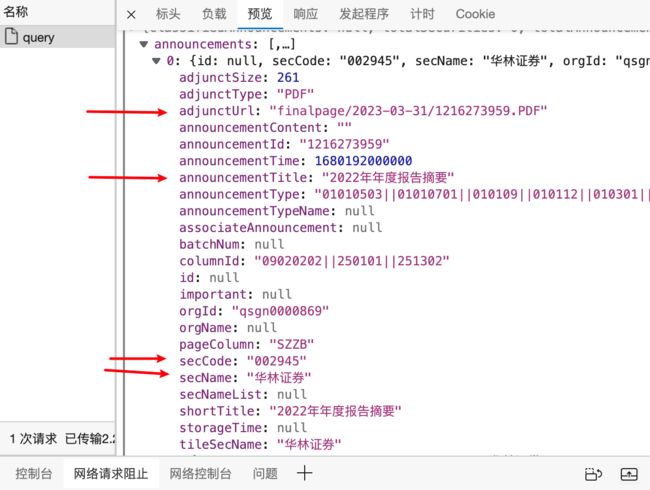
接着创建一个excel表格,按这些变量的顺序创建表格,并存入表格,注意在存入表格时,需要对内容进行筛选,如“英文版,摘要”这类年报并不是我们所需要的。
以下是主函数的完整代码。
def main(year):
# 计数器
global sum
date_count = f"{year}-01-01~{year}-04-30"
response = get_report(1,date_count)
data = response.json()
sum = data["totalpages"]
year = year+1
all_results = []
time_segments = [
f"{year}-01-01~{year}-04-01",
f"{year}-04-02~{year}-04-15",
f"{year}-04-16~{year}-04-22",
f"{year}-04-23~{year}-04-26",
f"{year}-04-27~{year}-04-28",
f"{year}-04-29~{year}-04-30"
]
for i in time_segments:
results = downlaod_report(i)
all_results.extend(results)
# 创建Excel文件并添加表头
workbook = openpyxl.Workbook()
worksheet = workbook.active
worksheet.title = "公众号 凌小添"
worksheet.append(["公司代码", "公司简称", "标题", "年份", "年报链接"])
# 解析搜索结果并添加到Excel表格中
for item in all_results:
company_code = item["secCode"]
company_name = item["secName"]
title = item["announcementTitle"].strip()
# 剔除不需要的样式和特殊符号,并重新组合标题
title = re.sub(r"<.*?>", "", title)
title = title.replace(":", "")
title = f"《{title}》"
adjunct_url = item["adjunctUrl"]
year = re.search(r"\d{4}", title)
if year:
year = year.group()
else:
year = setYear
time = f"{year}"
announcement_url = f"http://static.cninfo.com.cn/{adjunct_url}"
# 检查标题是否包含排除关键词
exclude_flag = False
for keyword in exclude_keywords:
if keyword in title:
exclude_flag = True
break
# 如果标题不包含排除关键词,则将搜索结果添加到Excel表格中
if not exclude_flag:
worksheet.append([company_code, company_name, title, time, announcement_url])
workbook.save(f"年报链接_{setYear}【公众号:凌小添】.xlsx")
2.5 开始运行
到这一步基本就大功告成了!只需要设置相关参数,就可以选择下载特定年份的年报,或者用循环遍历下载指定范围的年报。
if __name__ == '__main__':
# 全局变量
# 排除列表可以加入'更正后','修订版'来规避数据重复或公司发布之前年份的年报修订版等问题,
exclude_keywords = ['英文', '摘要','已取消','公告']
global counter
global sum
counter = 1 # 计数器
setYear = 2016 #设置下载年份
# for setYear in range(2004,2022):
main(setYear)
# print(f"{setYear}年年报下载完成")
3.小结
经过测试,基本上可以获取绝大部分年报,你可以通过调整请求参数来控制具体的公司行业,或者所属板块,但代码仍然有部分小问题,如进度显示会溢出、获取到的数据需要手动去除重复项等。

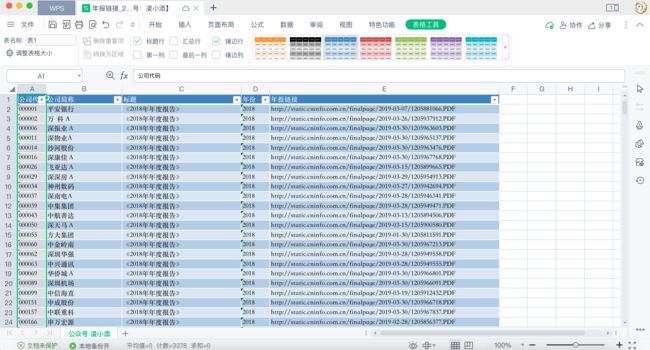
⭐️笔者已将2003-2022年年报链接打包,以及2010-2021年txt年报,关注公众号“凌小添”回复年报即可免费获取。
另外,笔者目前在整理2022年的年报数据以及参考吴非教授所做的2010-2022年上市企业的数字化转型词频,感兴趣可以先关注哦~
整理好后第一时间更新。
如果您喜欢自己动手,定制自己需要的词频,可以参考往期文章,欢迎大家交流学习~