《横向联邦学习中 PCA差分隐私数据发布算法》论文算法原理笔记
论文地址:https://www.arocmag.com/article/01-2022-01-041.html
论文摘要
为了让不同组织在保护本地敏感数据和降维后发布数据隐私的前提下,联合使用 PCA进行降维和数据发布,提出横向联邦 PCA差分隐私数据发布算法。引入随机种子联合协商方案,在各站点之间以较少通信代 价生成相同随机噪声矩阵。提出本地噪声均分方案,将均分噪声加在本地协方差矩阵上。一方面,保护本地数据隐私;另一方面,减少了噪声添加量,并且达到与中心化差分隐私 PCA算法相同的噪声水平。理论分析表明, 该算法满足差分隐私,保证了本地数据和发布数据的隐私性,较同类算法噪声添加量降低。实验从隐私性和可用性角度评估该算法,证明该算法与同类算法相比具有更高的可用性。
本文算法主要涉及到的几个知识点
1、PCA:pca主成分分析,广泛应用于数据降维,是将原来的n维特征映射到k维特征上,而这k维是全新的正交特征,即主成分。如何求得这k个主成分?通过计算数据矩阵的协方差矩阵,得到特征值和特征向量,选择top k的特征值对应的特征向量就是k个主成分,它们的方差最大,而这些特征值对应的特征向量组成的矩阵,便可以将数据矩阵转化到新的空间中,实现数据特征降维。
协方差公式: C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) Cov(X,Y)=E[(X-E(X))(Y-E(Y))]=\frac{1}{n-1}\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y) Cov(X,Y)=E[(X−E(X))(Y−E(Y))]=n−11i=1∑n(xi−xˉ)(yi−yˉ)上式是两维的情况,多维的话就是一个协方差矩阵:
C o v ( X , Y , Z ) = [ C o v ( X , X ) C o v ( X , Y ) C o v ( X , Z ) C o v ( Y , X ) C o v ( Y , Y ) C o v ( Y , Z ) C o v ( Z , X ) C o v ( Z , Y ) C o v ( Z , Z ) ] Cov(X,Y,Z)=\begin{bmatrix} Cov(X,X) & Cov(X,Y) & Cov(X,Z) \\ Cov(Y,X) & Cov(Y,Y) & Cov(Y,Z) \\ Cov(Z,X) & Cov(Z,Y) & Cov(Z,Z) \end{bmatrix} Cov(X,Y,Z)= Cov(X,X)Cov(Y,X)Cov(Z,X)Cov(X,Y)Cov(Y,Y)Cov(Z,Y)Cov(X,Z)Cov(Y,Z)Cov(Z,Z) 还有一个概念叫散度矩阵,是衡量数据的分散程度: S = ( n − 1 ) × C o v ( X , Y ) S=(n-1)\times Cov(X, Y) S=(n−1)×Cov(X,Y)这两者求出的特征向量是一致的。因此,整个PCA的求解过程可以如下:
- 求解整个样本的均值, μ = 1 n ∑ i = 1 n X i \mu=\frac{1}{n}\sum_{i=1}^nX_i μ=n1∑i=1nXi,这里 μ \mu μ也是一个m维(即m个特征)的向量。
- 求协方差cov, c o v = 1 n − 1 ( X − μ ) T ( X − μ ) cov=\frac{1}{n-1}(X-\mu)^T(X-\mu) cov=n−11(X−μ)T(X−μ)
- 根据协方差求特征值 Λ = [ λ 1 , λ 2 , . . . , λ m ] m × 1 \Lambda=[\lambda_1,\lambda_2,...,\lambda_m]_{m\times 1} Λ=[λ1,λ2,...,λm]m×1和特征向量 A = [ α 1 , α 2 , . . . , α m ] m × m \Alpha=[\alpha_1,\alpha_2,...,\alpha_m]_{m\times m} A=[α1,α2,...,αm]m×m.
- 最后利用特征向量进行降维: Y = [ X n × m Λ m × k ] n × k Y=[X_{n\times m}\Lambda_{m\times k}]_{n\times k} Y=[Xn×mΛm×k]n×k,其中 Λ m × k \Lambda_{m\times k} Λm×k是按照特征值倒排的k个特征向量。
2、差分隐私:( ϵ , δ \epsilon,\delta ϵ,δ)-差分隐私的定义,假设数据集 X X X和 X ′ X' X′是“邻居数据集”,给定一个算法 f , O ⊆ r a n g e ( f ) f,O\subseteq range(f) f,O⊆range(f),如果 P r [ f ( x ) ∈ O ] ≤ e ϵ P r [ f ( x ′ ) ∈ O ] + δ Pr[f(x)\in O] \le e^{\epsilon}Pr[f(x') \in O]+\delta Pr[f(x)∈O]≤eϵPr[f(x′)∈O]+δ则算法 f f f满足( ϵ , δ \epsilon,\delta ϵ,δ)-差分隐私,其中 ϵ \epsilon ϵ为隐私预算,是个经验值,且值越小,隐私保护水平越高, δ \delta δ是个差分隐私引入的松弛值。白话总结:差分隐私就是在引入噪声的情况下,实现数据的安全性。
具体的原理理解参考:https://zhuanlan.zhihu.com/p/139114240,
这篇文章中使用了差分隐私实现逻辑回归模型:https://zhuanlan.zhihu.com/p/464987876
差分隐私噪声引入机制:Laplace(拉普拉斯)机制、Exponential(指数)机制、Gaussian(高斯)机制。本文使用的是高斯机制
3、PCA高斯机制:假设算法 f ( X ) = X X T f(X)=XX^T f(X)=XXT,对 f ( X ) f(X) f(X)的输出加上满足 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布 τ = Δ f 2 l n ( 1.25 / δ ) / ϵ τ=\Delta f \sqrt{2ln(1.25/ \delta)}/\epsilon τ=Δf2ln(1.25/δ)/ϵ的随机噪声,则 f ( X ) f(X) f(X)满足 ( ϵ , δ ) (\epsilon, \delta) (ϵ,δ)-差分隐私。其中 X T X X^TX XTX是 X X X的协方差矩阵。 Δ f = max X , X ′ ∣ ∣ f ( X ) − f ( X ′ ) ∣ ∣ 2 \Delta f=\displaystyle\max_{X,X'}||f(X)-f(X′)||_2 Δf=X,X′max∣∣f(X)−f(X′)∣∣2是 f f f的 l 2 l_2 l2敏感度, X X X与 X ′ X′ X′为邻居数据集。
例如:设 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2,...,x_n) X=(x1,x2,...,xn)与 X ′ = ( x 1 , x 2 , . . . , x n ′ ) X'=(x_1,x_2,...,x'_n) X′=(x1,x2,...,xn′)为邻居数据集,且 ∣ ∣ x i ∣ ∣ 2 ≤ 1 ||x_i||_2≤1 ∣∣xi∣∣2≤1, ∀ i ∈ [ n ] \forall i∈[n] ∀i∈[n],有算法 A = 1 n X X T A=\frac{1}{n}XX^T A=n1XXT与 A ′ = 1 n X ′ X ′ T A'=\frac{1}{n} X'X'^{T} A′=n1X′X′T,满足 max X , X ′ ∣ ∣ A − A ′ ∣ ∣ 2 ≤ 1 n \displaystyle\max_{X,X'}||A-A'||_2≤\frac{1}{n} X,X′max∣∣A−A′∣∣2≤n1,则此算法敏感度 Δ f = 1 n \Delta f=\frac{1}{n} Δf=n1,令 τ = 1 n 2 l n ( 1.25 / δ ) / ϵ τ=\frac{1}{n}\sqrt{2ln(1.25/\delta)}/\epsilon τ=n12ln(1.25/δ)/ϵ,对 A A A加上满足 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布的随机噪声,则算法 A A A满足 ( ϵ , δ ) (\epsilon,\delta) (ϵ,δ)-差分隐私。
本地均分扰动联邦PCA算法(ELFedPCA)
算法思想:在本地生成相同的随机噪声矩阵,通过均分随机噪声矩阵的方式,在本地扰动协方差矩阵,使得在服务器相加后的协方差矩阵满足差分隐私定义;设计隐私保护联合中心化方案,保护本地数据均值和总数的隐私。
使用场景如下:sites每个站点有自己的数据,server负责进行汇总pca,publisher负责发布server降维后的数据。

前提:设 X ∈ R n × d X\in \R^{n\times d} X∈Rn×d为所有s个站点的数据集合,横向划分数据集 X 1 , . . . , X s X_1,...,X_s X1,...,Xs,第 i i i个站点的数据 X i = ( x i 1 , . . . , X i N i ) T ∈ R N i × d X_i=(x_{i1},...,X_{iN_i})^T\in\R^{N_i\times d} Xi=(xi1,...,XiNi)T∈RNi×d,其中 d d d为数据集的维度,且各站点的维度相同, N i N_i Ni是站点 i i i的数据量。所有站点的总数据量 n = ∑ i = 1 s N i n=\displaystyle\sum_{i=1}^sN_i n=i=1∑sNi
算法流程:
1、中心化(减去均值):在不泄露各站点的数据信息的情况下,让站点2生成s-1个和为0的小数 a 2 , a 3 , . . . , a s a_2,a_3,...,a_s a2,a3,...,as与和为0的整数 b 2 , b 3 , . . . , b s b_2,b_3,...,b_s b2,b3,...,bs,然后将 a i , b i a_i,b_i ai,bi发给对应的站点 i i i。各个站点计算自己的sum和count,站点1为: s u m ( s 1 ) = ∑ k = 1 N 1 x 1 k , c o u n t ( s 1 ) = N 1 sum(s_1)=\sum_{k=1}^{N_1}x_{1k},count(s_1)=N_1 sum(s1)=k=1∑N1x1k,count(s1)=N1其他站点 i i i为: s u m ( s i ) = ∑ k = 1 N i x i k + a i , c o u n t ( s i ) = N i + b i sum(s_i)=\sum_{k=1}^{N_i}x_{ik}+a_i,count(s_i)=N_i+b_i sum(si)=k=1∑Nixik+ai,count(si)=Ni+bi,最后各站点 i i i将计算的sum和count发给站点1进行汇总: s u m ( s ) = ∑ i = 1 s s u m ( s i ) , c o u n t ( s ) = ∑ i = 1 s c o u n t ( s i ) sum(s)=\sum_{i=1}^ssum(s_i),count(s)=\sum_{i=1}^scount(s_i) sum(s)=i=1∑ssum(si),count(s)=i=1∑scount(si)由于 ∑ i = 2 s a i = 0 , ∑ i = 2 s b i = 0 \sum_{i=2}^sa_i=0,\sum_{i=2}^sb_i=0 ∑i=2sai=0,∑i=2sbi=0,所以sum(s)就算所有站点的真实总和,count(s)就是所有站点的真实数据量。从而所有站点的数据的均值为: μ = s u m ( s ) c o u n t ( s ) \mu=\frac{sum(s)}{count(s)} μ=count(s)sum(s)站点1在将计算得到的均值 μ \mu μ发给其他站点,做中心化操作: x i = x i − μ x_i=x_i-\mu xi=xi−μ
为什么要去中心化,如图,使得计算主成分时不会受到偏离值的影响。同时中心化是求协方差的一部分, 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) \frac{1}{n-1}\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y) n−11∑i=1n(xi−xˉ)(yi−yˉ)。
2、归一化,由于差分隐私PCA高斯机制要求 ∣ ∣ x i ∣ ∣ 2 ≤ 1 ||x_i||_2\le 1 ∣∣xi∣∣2≤1,所以需要对数据进行归一化 x i = x i ∣ ∣ x i ∣ ∣ 2 x_i=\frac{x_i}{||x_i||_2} xi=∣∣xi∣∣2xi
前两步就是对数据进行 ( 0 , 1 ) (0,1) (0,1)的标准化操作。
3、每个站点计算自己的协方差矩阵: A i = 1 N i − 1 X i T X i A_i=\frac{1}{N_i-1}X_i^TX_i Ai=Ni−11XiTXi设所有的站点的数据 X = ( X 1 , X 2 , . . . , X s ) X=(X_1,X_2,...,X_s) X=(X1,X2,...,Xs)的协方差为 1 N − 1 A \frac{1}{N-1}A N−11A
4、站点1生成一个随机种子seed,并设置合适的 ϵ \epsilon ϵ和 δ \delta δ,然后发送 [ s e e d , ϵ , δ ] [seed,\epsilon,\delta] [seed,ϵ,δ]给其他站点,各站点便可以生成相同的服从 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布 τ = 2 l n ( 1.25 / δ ) / n ϵ τ=\sqrt{2ln(1.25/\delta)}/n\epsilon τ=2ln(1.25/δ)/nϵ ( n n n为所有站点数据量总和)的随机噪声矩阵 E ∈ R d × d E\in\R^{d\times d} E∈Rd×d,将噪声矩阵均分 E ′ = E / s E'=E/s E′=E/s ( s s s为所有站点的总和),然后再计算 A i ′ = A i + E ′ A_i'=A_i+E' Ai′=Ai+E′。便可以将加入均分随机噪声的的协方差矩阵发给站点1。
5、站点1累计所有站点发送来的加入均分随机噪声的协方差矩阵: A ′ = A 1 ′ + A 2 ′ + . . . + A s ′ A'=A_1'+A_2'+...+A_s' A′=A1′+A2′+...+As′这个协方差 A ′ A' A′和中心化差分隐私PCA加入噪声后的协方差矩阵相同,证明如下: A ′ = A 1 ′ + A 2 ′ + . . . + A s ′ = ( A 1 + E ′ ) + ( A 2 + E ′ ) + . . . + ( A s + E ′ ) A'=A_1'+A_2'+...+A_s'=(A_1+E')+(A_2+E')+...+(A_s+E') A′=A1′+A2′+...+As′=(A1+E′)+(A2+E′)+...+(As+E′) = ( A 1 + A 2 + . . . + A s ) + s × E ′ = A + E =(A_1+A_2+...+A_s)+s\times E'=A+E\quad\quad\quad\quad\quad\quad\quad\quad =(A1+A2+...+As)+s×E′=A+E
这里有个疑问:就是如果各站点的 E ′ E' E′相同,那个站点1也有,各站点的 A i A_i Ai不就可以通过 A i ′ − E ′ A'_i-E' Ai′−E′得到了吗?这在本地做噪声引入就保护本地协方差的没有意义了。
6、随后站点1对 A ′ A' A′进行SVD分解,取top k个特征值对应的特征向量,得到 V ′ ∈ R d × k V'\in\R^{d\times k} V′∈Rd×k,并将 V ′ V' V′发送给其他站点。
7、其他站点计算降维后的数据 Y i = X i V ′ , Y i ∈ R N i × k Y_i=X_iV',Y_i\in \R^{N_i\times k} Yi=XiV′,Yi∈RNi×k,并将 Y i Y_i Yi发送给站点1进行汇总: Y = ( Y 1 , Y 2 , . . . , Y s ) Y=(Y_1,Y_2,...,Y_s) Y=(Y1,Y2,...,Ys)
实验结果
本文对几个不同的数据集,对比DPdisPCA算法做了CE和SVM分类实验,实验结果如下: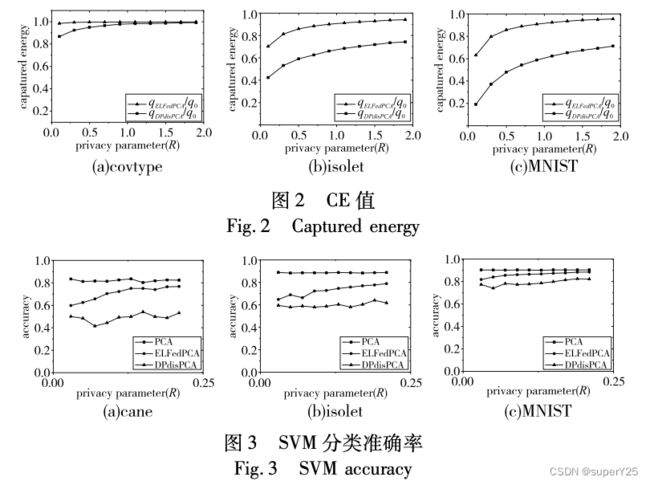
最后本文贡献
1、本文算法ELFedPCA是满足 ( ϵ , δ ) (\epsilon,\delta) (ϵ,δ)-差分隐私的,可以很好的保护各站点的隐私。
2、本文算法ELFedPCA添加的噪声量比现有文献中的噪声添加量小。因为服从高斯分布的随机噪声方差越大, 噪声越大。现有文献DPdisPCA采用的是在站点本地生成服从 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布 τ = 2 l n ( 1.25 / δ ) / N i ϵ τ=\sqrt{2ln(1.25/\delta)}/N_i\epsilon τ=2ln(1.25/δ)/Niϵ的随机噪声,因此本地添加噪声的方差与 1 N i 2 \frac{1}{N_i^2} Ni21成正比。而ELFedPCA添加的噪声相当于中心化添加服从 N ( 0 , τ 2 ) N(0,τ^2) N(0,τ2)分布 τ = 2 l n ( 1.25 / δ ) / n ϵ τ=\sqrt{2ln(1.25/\delta)}/n\epsilon τ=2ln(1.25/δ)/nϵ ( n n n为所有站点数据量总和)的随机噪声,其噪声的方差与 1 n 2 \frac{1}{n^2} n21成正比。因为 N i ≪ n N_i \ll n Ni≪n,所以 1 N i 2 > 1 n 2 \frac{1}{N_i^2} > \frac{1}{n^2} Ni21>n21。则ELFedPCA添加的噪声量更小。