数据仓库为什么要分层 ? 怎么分层?
1 序
说到数据仓库 , 大家应该都有一定的了解 , 越来越多的企业在做数字化转型 , 业务数据化 , 数据业务化 , 数据仓库是其中必不可少的一环 . 在数仓中有一个很基础、重要 , 但又很容易被忽略的内容 , 那就是数据仓库中的数据分层. 数据要分几层 ? 每一层放什么 ? 为什么要这样分 ? 下面我们就一起探讨一下 .
2 为什么要分层
在探讨数据仓库应该如何分层前 , 需要先思考另一个问题 : 数据仓库为什么要分层 ?
数据分层的根本原因 , 用互联网黑话说 , 其底层逻辑 , 就两个字 : 解耦 . 数据解耦的逻辑就是数据分层的逻辑 . 在解耦的底层逻辑上 , 可以大致归纳为以下3点原因 :
1. 把复杂的问题简单化
数据建设的根本原因是解决业务问题 , 而数据分层则是把复杂问题的解决步骤拆分 , 每层解决一部分
2. 结构更清晰
分层的好处也表现为数据的结构层次更为清晰 , 每一层做什么事情一目了然 , 数据管理也很方便
3. 数据重复使用
数据分层使得数据模块化 , 复用性高 , 极大的减少重复计算 . 而数据的重复使用恰恰是数仓中最重要的能力体现 .
3 怎么分层
3.1 较为通用的分层方法
数据的分层不是一成不变的 , 到底需要分几层需要就实际的场景讨论 , 那有没有一种在不知道分几层的情况下 , 可以直接使用的分层方法呢 ? 下面给大家分享一个稍微通用的分层方法 :
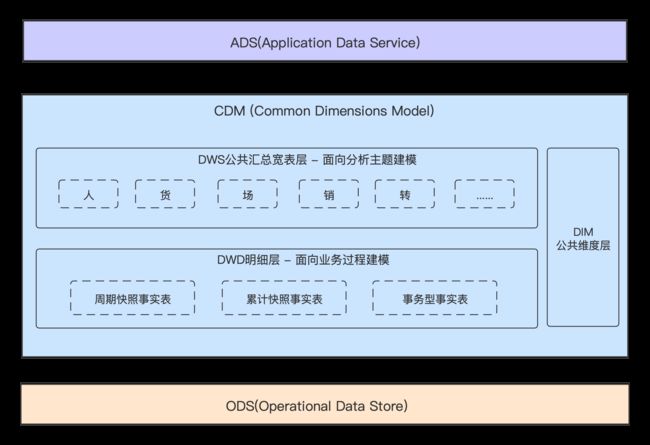
这种分层的方法把数据仓库逻辑上分为3层 , 贴源层ODS , 公共层CDM以及应用层ADS . 在公共层又细分为维度层、明细层和汇总层 . 其每一层的含义如下 :
1. ODS贴源层 [Operational Data Store]
该层是通过数据集成工具把操作系统数据落入数仓的第一层 , 在结构上其与源系统的增量或者全量数据应基本保持一致
2. CDM公共层[Common Data Model]
公共维度模型层 , 又细分为DWD、DWS和DIM . 它的主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标
采用维度建模作为理论基础 , 更多地采用一些维度退化手法 , 将维度退化至事实表中 , 减少事实表和维度表的关联 , 提高明细数据表的易用性; 同时在汇总数据层 , 加强指标的维度退化 , 采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性
- DIM维度层 [Dimension]
公共维度层:基于维度建模理念思想,建立整个企业的一致性维度,降低数据计算口径、算法不统一的风险
- DWD明细层 [Data Warehouse Detail]
明细粒度事实层:以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。明细事实表一般根据ODS层数据加工生成,此时应保证一个DWD明细事实表只对应一个业务过程
- DWS聚合层 [Data Warehouse Summary]
公共汇总粒度事实层:以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,基于OneData体系,构建公共粒度的汇总指标事实表,以宽表化手段来物理化模型
3. ADS应用层(Application Data Service)
本层级根据需求按需开发 , 存放数据产品个性化的统计指标数据 , 根据CDM层数据加工得到
3.2 分层的演进
一般来说 , 新数仓的搭建 , 分为这几层基本不会有问题 , 但随着公司和业务的不断发展 , 数仓的分层也会相应的产生变化 , 变化最多的就是DWD和DWS两层
3.2.1 DWD的变化
下面为美团酒旅的数仓分层示意图 , 随着美团上海团队的融入 , 同时自身酒旅系统重构频繁 , 美团选择在ODS和多维明细层之间加入了数据整合层 , 利用Bill Inmon的提出的方法论 , 按照三范式原则建造 .
在业务系统繁多、变化快的情况下 , 使用数据整合层的三范式建造 , 将数据源的变更在这一层拉通抹平 , 充分降低了对上层模型的影响 , 增加数仓整体的稳定性 .
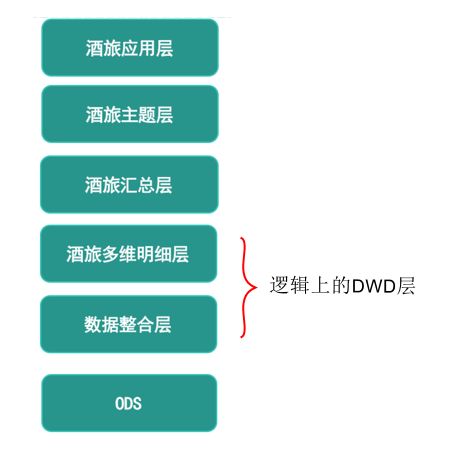
同样的 , 在车好多 , 新车、严选、全国购等业务情况繁多 , 每一种业务形态都会有电销、金融、组织架构等数据 . 每个业务线单独建设这些数据会导致最终的指标不一致 , 为了解决这个问题 , 在DWD层中又单独划分出一个逻辑层 , DWD的commen层 , 这一层对于公共数据统一建设 , 其他DWD模型在使用到这些公共数据时必须从此层拿数据 , 避免了上层指标的数据不一致产生 .

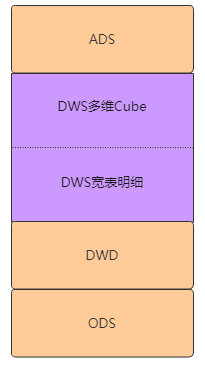
3.2.2 DWS的变化
随着业务的需求越来越多 , 指标也越积累越多 , 指标的多维分析场景使用非常普遍 , 今天要看到城市粒度 , 明天要看区粒度的需要就提了过来 , 同一个指标只是粒度不同 , 可能会建好几张模型来支持 . 为了避免核心指标模型的不稳定性 , 于是就有了以下这种DWS的分层逻辑 , 将明细宽表和多维cube分开来 , 对于核心指标 , 建设好cube , 向上支撑数据的使用 . 可以有效的避免核心模型的不稳定性 .
4 总结
以上的分层只是万千种分层方法中的几种个例 , 分层没有对错 , 只有合适与不合适 . 数仓的建设不是一层不变的 , 需要针对实际的问题 , 来制定合适的分层逻辑 , 但是总体来说 , 分层的思想不变 , 那就是解耦和复用 .