R数据分析:工具变量回归与孟德尔随机化,实例解析
原谅我又拖更好久,没办法,欸,就是懒,但是所有的单子都是保质保量完成的哈。,今天给大家写工具变量和孟德尔随机化,文章略微有些长,请大家准备好清醒的头脑,和半个小时的阅读时间哈。
啥是工具变量回归
Instrumental variable procedures are needed when some regressors are endogenous (correlated with the error term). The procedure for correcting this endogeneity problem involves finding instruments that are correlated with the endogenous regressors but uncorrelated with the error term. Then the two stage least squares procedure can be applied.
在你的研究中有内生性问题时(就是你的自变量和残差有关系了,这个时候就有内生性问题了),这个时候就可以用得到工具变量回归,或者说你的混杂很多控制不完,这个时候就可以用工具变量回归。
工具变量回归是在观察性研究中控制混杂的利器!
举例说明工具变量
我现在想探讨两个有相关的变量之间的因果关系,比如X和Y吧,我想知道XY是如何相互影响的,现在聪明的我又去找了一个变量Z,我现在肯定地知道Z和Y是没有直接的关系的,但是Z会影响X,且只会影响X。
然后我做数据分析,如果我的数据告诉我本来不可能影响Y的Z竟然对Y有作用,那么这个作用只能是通过X实现的。
大概思想就是这样的,好简单吧。继续看:
把上面的话放在一个实际的情形下:我现在想研究抑郁depression (X)和 smoking (Y)的关系,此时我手上恰好还有一个变量:工作机会缺乏Lack of job opportunities (Z),正常人都知道工作机会缺乏是绝对不可能对吸烟有影响的,对吧,因为工作机会是别人或者外部环境决定的,吸烟是你自己干的,所以Z对Y是绝对不会有影响的,但是我收集到了好多数据,一分析,发现工作机会越缺乏的人们吸烟情况越严重,这内在的原因有可能就是X(仅在XYZ3个变量的系统中看)。
这个时候Z就可以在研究XY之间关系的时候作为一个工具变量!
什么是工具变量回归
工具变量回归就是把上面的思想用数据实现,具体的方法就是把你的有内生性问题的自变量拆开,一部分和残差有关,一部分无关,无关的部分就是工具变量:
Instrumental Variables regression (IV) basically splits your explanatory variable into two parts: one part that could be correlated with ε and one part that probably isn’t
有点不好理解,继续看:
还记得我们的一般的回归模型不?如下图:

注意模型后面都有一个误差项e,这个e就代表这除了x之外的那些没能测着的可能影响y的因素,而工具变量回归就相当于将我们原来的X分解成了两部分,一部分和误差项相关,一部分不相关,不相关的部分的系数不久是干干净净的系数嘛。所以说一个完美的工具变量就可以将混杂控制的干干净净明明白白的。
如何找工具变量
In real life, instrumental variables can be difficult to find and in fact, may not exist at all
很遗憾,现实世界真正的工具变量有可能根本就不存在,最完美工具变量就要求这个工具变量Z只和X相关,和Y不相关。
就是这个“只”,太难了。
回到我们的第一个例子:你说工作机会缺乏本身是不可能和吸烟有影响的,我同意,但是它只影响抑郁吗?不是。
工作机会缺乏有可能还会影响焦虑吧,还会影响幸福感吧,这些说不定都和吸烟有可能有关吧,所以我们把工作机会缺乏做工具变量回归,得到的抑郁对吸烟的影响肯定也是不准的。
我们找工具变量一定是基于理论的,不是说我做个相关分析就说某某变量满足工作变量的条件,合格工具变量从理论上考虑要满足如下两个条件:
- Exogenous —not affected by other variables in the system (i.e. Cov(z,ε) = 0). This can’t be directly tested; you have to use your knowledge of the system to determine if your system has exogenous variables or not.
- Correlated with X, an endogenous explanatory variable (i.e. Cov(Z,X) ≠ 0). A very significant correlation is called a strong first stage. Weak correlations can lead to misleading estimates for parameters and standard errors.
- 一是外生性Exogenous,就是说你找的这个工具变量是绝对不应该受到你研究的这个系统中的其余变量影响的。
- 二是一定要和X相关Correlated with X,最好是强相关(弱相关会导致X的系数估计不准)
比如,我想看接受咨询对抑郁的效果如何,因为影响抑郁的因素实在太多了,你想一个一个都收集后在模型中控制掉显然是不现实的,但是我发现了一个我研究的这个系统中的一个外生变量:离咨询中心的距离,我们认为离咨询中心的距离和接受咨询是有相关的,有可能还比较强,此时距离就可以在我们的研究中作为一个工具变量。
这个距离变量在理论上是绝对不会影响抑郁的,如果在模型中发现距离有作用,我们就可以认为其是通过影响咨询从而影响的抑郁,它的系数就可以近似认为是咨询的系数。
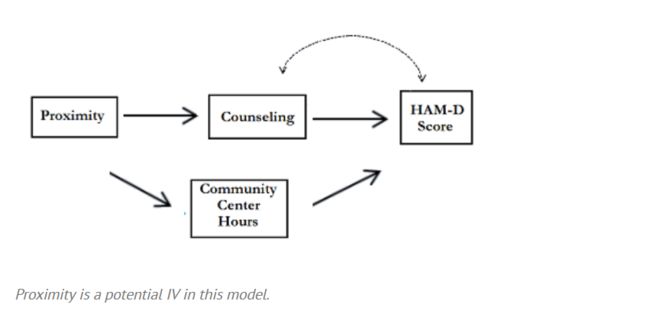
就像上图表达的一样,我们现在理解为距离只有通过影响咨询才能影响抑郁,所以其系数可以认为是咨询的系数,但是这个说法成立的前提就是只,就是距离和咨询之间的相关性是完美的。
但是实际上是不可能的。
比如,有可能咨询中心是在社区服务中心里面的,那么此时距离其实和人们在社区服务中心待的时间有相关性了,就是离咨询中心近就越可能在社区服务中心待的时间久,从而受到同伴或者别的影响就不容易抑郁,但这并不是咨询的作用。
所以从这个角度考虑距离作为工具变量也是不完美的,但是科研哪有完美的事呢,发表的文献中用距离作为工具变量的文章很多的。大家理解这其中的内在逻辑就好。
就是说下图中红色的路径的存在是影响了例子中工具变量的可接受性的。

横断面数据的因果推断理论
要推断因果很多时候是要通过设计良好的随机对照试验进行的,当实验设计行不通的时候,学者就会追求通过横断面数据探讨因果,通常我们会将实验组和对照组的差值直接看作是试验因素导致的果,但是这样的做法缺点是显而易见的:
In most observational studies, inferring effects is problematic, because those choosing different treatments may be different and their responses to the actually received treatments may also be different
于是聪明的学者们进行了很多的努力,比如说通过给实验组匹配一些特征一致的对照组(就是在一堆横断面观察数据中挑选),最终使得两组除了实验因素其余的特征均达到可比,这样就能解释因果了。
但是这么样匹配也是存在问题的:你只能匹配那些你自己知道的变量,有可能好多特征你根本就没有考虑到或者根本就考虑不到,所以又怎么说明两组是可比的呢?
还有一种常用的方法是反事实推断方法,感兴趣的可以阅读下面的文献:
Rosenbaum, P., Rubin, D: The central role of the propensity score in observational studies for causal effects. Biometrika, 70, 41–55 (1983)
这儿只给大家简要介绍,我们已经知道用观察数据的实验组和对照组之间的差异并不能说明是实验因素导致了这种差异,是因为两组的某些特征有可能是不同的,有可能正是实验组具备某些特征所以它更容易成为实验组,咱们不知道。
those who chose a particular treatment may have had good reasons to choose that treatment (perhaps including a particular response to the treatment), and therefore their responses to different treatments cannot be compared
但是有没有可能在对照组中真的找出来一个亚组,这个亚组的总的特征和实验组完全一样,从而它们接受试验的可能性也应是一样的,这样的亚组理论上是可以的!
就是说我们要做的在对照组中找到那些本来应该和实验组一样可能性接受试验因素的个体,那么这些个体就是那种本来凭着它自己的特征应该会被分到实验组但却到了对照组的个体,这些个体除了没有接受实验因素,其它的特征我们认为都和实验组是可比的!
那么怎么样评价这个接受试验的可能性呢?就用倾向分propensity score
大家把上面的中文和下面的英文多读几遍,体会一番这种反事实思想的高明之处:
the effect size may be estimated by comparing those who have and those who have not received the treatment from among those who would have received the treatment with equal probability. This probability is called the propensity score.
本来两个人被分到实验组的可能性都一样,但现实中一部分却分到了对照组,那么这些人之间的效果差不就是实验因素造成的嘛。
以上就是反事实推断因果的思想。很棒的思想!
再给大家介绍另外一种因果推断的思想:工具变量,感兴趣的同学可以阅读下面的文献:Spirtes, P., Glymour, C, Scheines, R.: Causation, Prediction and Search. Springer, New York (1993)
这儿依然是给大家简要说明,因为开篇就讲过:
想象一下我们有XYZ3个变量,我们想看看这3个变量之间的关系和关系的方向,首先我们考虑XY之间是独立的,此时存在两种情况,一是XY没有任何联系,二是虽然XY在表面上有联系,但是实际上其实没联系(表面上的联系也是因为同时受到Z的影响造成的)。
为了更好地说明3个变量间关系的各种情况,我们借助有向无环图DAGs看看:
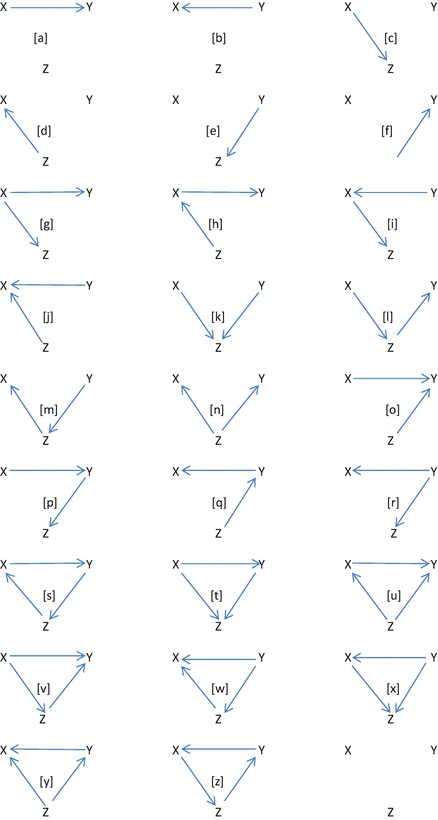
上面的这个图显示了XYZ之间关系的所有可能性,看到这个图我们再来回味一下两个变量独立的情况,如果XY是独立的,那么上图中的[a], [b], [g], [h], [i], [j], [o], [p], [q], [r], [t], [u], [v], [x], [y], and [z]都会没有啦,因为这些子图中都有都有XY之间的指向箭头。我们看[I]这个图就表达了完全中介效应,就是XY是没有直接因果的,之所以有表面的因果也是因为Z存在,如果Z不在了,XY依然独立。同理图[m]也是一个意思。
上面介绍了两个变量独立,还有一个概念叫做条件独立,条件独立也会牵涉到第三个变量Z,就是说在Z的特定水平下XY是独立的,只要Z不变,XY就一直独立,此时所有XY的虚假关系都是Z导致的:
Conditional independence is linked to the causal structures depicted in these graph by saying that if some intervention kept Z constant, X and Y would be independent, just like as if conditioned on a particular category of Z
上面的子图[n]就表示一种条件独立关系,其实[l],[m]也可以看作是XY条件独立。
应用条件独立的思想就引申出了工具变量instrumental variable这个概念,如果我们要回答:“对于存在相关关系的XZ,到底是X对Z有作用还是Z对X有作用这一科学问题”,我们找到工具变量Y,这个Y只会对Z产生影响,但是不会影响X且不会被X影响,这样就保证了在有向无环图中XY之间是绝不会有箭头存在的(图[K]),但是Y一定有箭头指向Z,此时就形成了XY的条件独立性,这个条件就是Z。
看到这儿估计好多人已经晕了,没办法呀,写作水平有限,得给大家放个图。
读到这的同学先回头把图[k]和图[m]好好地瞅两眼,继续往下看,把图k和图m印在你的脑海里,如果此时XY是真实是独立的,那我们的可以得出来X是因Z是果(图[k]);如果此时XY是条件独立的,我们就可以得出来Z是因X是果(图[m])。
以上就是用工具变量推断因果方向的思想。
孟德尔随机化
上面写了很多的横断面观察数据推断因果的思想,目的之一就是要给大家引出来孟德尔随机化Mendelian Randomization(写个文章真的是煞费苦心啊,赶紧先点个赞再继续往下看)。孟德尔随机化其实就是找到了一个近乎完美的工具变量,建议大家阅读下面这篇文献:
Mendelian Randomization: Genetic Variants as Instruments for Strengthening Causal Inference in Observational Studies
这篇文献就讲了,通过孟德尔随机化来实现在观察数据实现因果推断,这儿依然是粗浅地给大家进行介绍。
The basic principle utilized in Mendelian randomization is that genetic variants that either alter the level of, or mirror the biological effects of, a modifiable environmental exposure that itself alters disease risk should be related to disease risk to the extent predicted by their influence on exposure to the environmental risk factor.Common genetic polymorphisms that have a well-characterized biological function (or are markers for such variants) can therefore be utilized to study the effect of a suspected environmental exposure on disease risk.
孟德尔随机化的基本原理就是基因变量和疾病的关系程度是可以被基因所造成环境因子的暴露所预测的。基因的变化可以用来研究环境暴露对疾病的影响。
这里面重要需要理解的就是使用基因的变异替代环境的变异。
有人问,为啥我不直接测暴露呢?是因为基因受到的社会心理行为因素更少,或者说没有。
举个例子,我在研究维生素C和冠心病的因果关系的时候,如果我除了直接来收集了维C使用和冠心病发病率的数据,我还得收集各种心理,社会,行为因素作为协变量吧,此时我问你,你能保证都收集的面面俱到嘛?
不能,绝对做不到,因为有很多可能至今未被人们理解的变量会影响冠心病。
但是如果我用基因来作为可修饰环境因素的替代,是不是这个关系就清晰多了,因为基因是不会那么容易被外界因素影响的,另外因为减数分裂过程是随机的,所以基因之间也没有联系--------孟德尔第二定律------孟德尔随机化的由来。
举个例子,下表可以看得到很多心理行为因素都和CRP水平有关系:
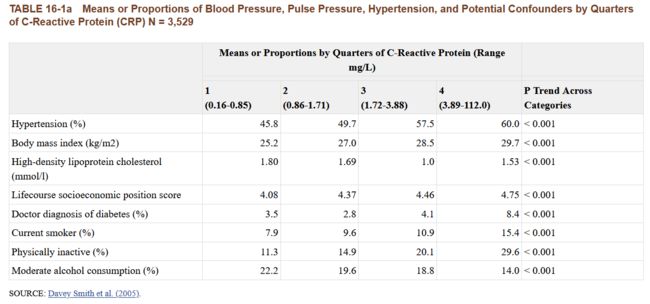
但是,你却可以发现同样的这些心理行为因素都和1050G/C基因型是没关系的(除了CRP)。这个基因就可以作为CRP的marker,就是一个很好的工具变量。

在观察性研究中还有一个顾虑是反向因果,但是使用基因型作为工具变量也很好地排除了反向因果;还可以避免测量误差和选择偏倚,具体解释请查阅原文献哈。
孟德尔随机化和随机对照试验思想对比
孟德尔随机化和随机对照实验是有逻辑上的一致性的。如下图:
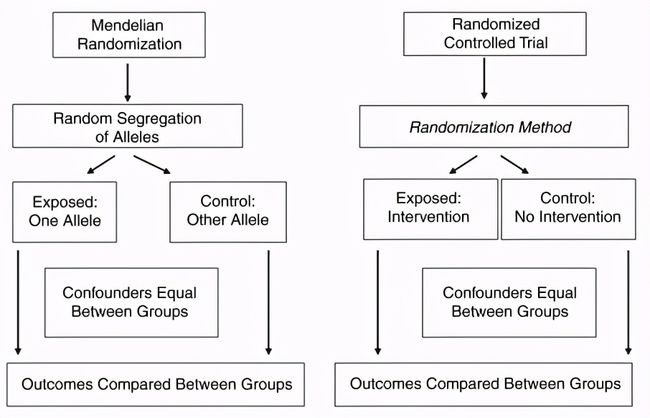
在随机对照实验中我们有专门的随机分配过程来保证组间的可比性,在孟德尔随机化中我们有一个样本的挑选过程,这个挑选是通过等位基因实现的,把等位基因作为了暴露的代替,从而也可以实现组间可比性:
我们考虑一个研究降压药效果的随机对照试验,影响血压的变量是很多的,通过试验分配的随机化,我们朴素地认为所有的可能或不可能影响血压的因素都在两组中可比了。【有文章会在随机化后比较基线特征,这个操作是完全没有必要的】
在孟德尔随机化中我们认为等位基因的分配就是一个天然的随机过程,所以如果我们找到了影响暴露的等位基因,此时我们选择不同基因型的个体进行比较就可以直接得到暴露所造成的效果。
举例子:我要研究酒精消耗和心血管疾病的关系,有可能不饮酒的人其实是自身身体本来就差,所以他不饮酒所以有可能你发现不饮酒的人心血管病发病情况更加高,还有情况是因为他心血管疾病了所以他不饮酒了,这个是反向因果,诸如此类,你做个横断面调查是说不清楚的。
但是我找到了一个影响饮酒的基因ALDH2 genotype,这个基因是随机的呀,是不会受到其余因素影响的,也不会有反向因果的。
你只要这个基因阳性,我就朴素地认为你就是饮酒的,即使你没有饮酒也是因为你反向因果了,或者是被环境影响了;只要你这个基因阴性,你就是不饮酒,即使你饮酒也是因为被环境影响了。有人估计要骂我在乱说,其实是的,这个孟德尔随机化一定要是大样本才行的,一定注意。反正思想就是这样。
The analogy with randomized controlled trials is also useful in understanding why an objection to Mendelian randomization—that the environmentally modifiable exposure proxied for by the genetic variants (such as alcohol intake or circulating CRP levels) are influenced by many other factors in addition to the genetic variants (Jousilahti and Salomaa, 2004)—while true, is of no consequence.
所以说你只要找一批ALDH2 genotype阳性的人和ALDH2 genotype阴性的人,直接调查它们的心血管病发病,你就可以得到饮酒对心血管病的影响了,注意一定是大样本情形哈。
有些同学还是不信,在写个例子:很多研究都说CRP和hypertension, insulin resistance, and coronary heart disease有关系,所以很多学者都说CRP造成了这些病,有一天,有人做了孟德尔随机化研究了这个问题,他就发现虽然CRP和这些病相关,但是CRP基因和这些病都没关,这就矛盾了吧,其中一个解释就是混杂太多了,还有一个解释就是反向因果,就是说横断面数据不准的,你得信孟德尔随机化。文献给大家贴上,有兴趣自己去看:
Davey Smith G, Lawlor D, Harbord R, Timpson N, Rumley A, Lowe G, Day I, Ebrahim S. Association of C-reactive protein with blood pressure and hypertension: Lifecourse confounding and Mendelian randomization tests of causality. Arteriosclerosis, Thrombosis, and Vascular Biology. 2005;25:1051–1056.
这一部分是对比随机对照试验嘛,就再给大家写个例子:比如我研究降压药的效果,我会设计一个随机对照试验,把所有影响血压的因素都通过随机分配到两组中,一组给药,一组不给,挺好的设计,精髓就在于混杂随机分配的过程。转到孟德尔随机化,相关基因的显性和隐性也是随机分的,天然随机的,而这个随机就保证了你暴露还是不暴露,所以在逻辑上孟德尔随机和随机对照试验是一样一样的:
Thus the fact that many other factors are related to the modifiable exposure does not vitiate the power of randomized controlled trials; neither does it vitiate the strength of Mendelian randomization designs.
所以如果你信随机对照试验,你就应该理解并相信孟德尔随机化。以上从类比随机对照研究的角度给大家写了孟德尔随机化,希望给大家以启发。
孟德尔随机化和工具变量思想
本文开篇就讲了,一个完美的工具变量必须有外生性和与X强相关,基因型是有天然的外生性的,所以第一个条件完美满足,因为我们找的基因本来就是对我们的研究的暴露有影响的基因(比如引起维生素D缺乏的基因)所以第二个条件也几乎完美满足。还有这个工具变量也是肯定和其它可能影响结局的混杂无关的。
反正就是:用适合的基因作为工具变量太完美啦,记住下图!
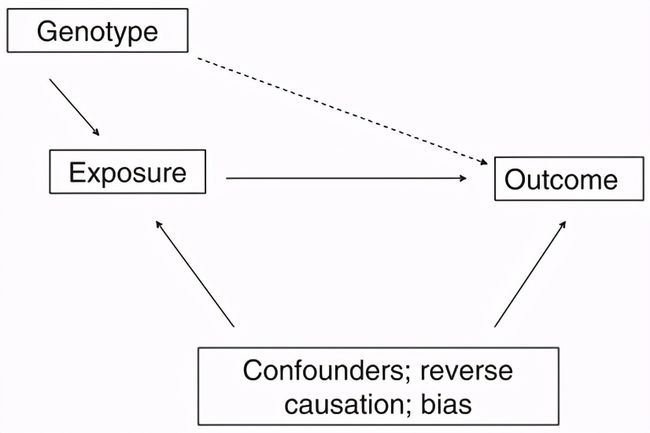
这个基因不会影响结局,因为它是仅引起暴露的基因,这个基因和你能想象到的任何混杂(各种心理行为社会因素)都不可能有关系,所以如果在数据分析中我们发现这个基因的表达和结局竟然出现了关系,那么一定是通过影响暴露X从而影响了结局Y,而且这个因果一定是从X到Y而不会反过来,这一切的推断都是从横断面观察性研究中得出的,多么精妙啊。
以上给大家写了从工具变量角度理解孟德尔随机化。希望能给大家以启发。
实例操练
希望看了上面的比较详细的解释,大家应该理解了孟德尔随机化的原理,接下来再带着大家用实际例子进行实操
这篇文章太长了实在放不下了,先点关注,看下篇吧。略略略.....。
小结
今天给大家写了孟德尔随机化的原理,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另有任何问题都可以私信我哈。
往期精彩
R数据分析:如何给数据框的列改名
R数据分析:相关性分析
R数据分析:有调节的中介
R数据分析:如何用R做数据模拟
R数据分析:用R语言做meta分析
R数据分析:用R语言做潜类别分析LCA
R数据分析:多分类逻辑回归
R数据分析:如何做聚类分析,实操解析
R数据分析:主成分分析及可视化
R数据分析:一些数据可视化的基本原则
R数据分析:生存分析的做法和结果解释
R数据分析:潜在剖面分析LPA的做法与解释
R数据分析:鸢尾花数据集的聚类分析实操
R数据分析:潜变量与降维方法(主成分分析与因子分析)
R数据分析:逐步回归的做法和原理,案例剖析
R数据分析:如何在R中使用mutate
R数据分析:著名的“三门问题”的R语言模拟
R数据分析:贝叶斯定理的R语言模拟
R数据分析:层次聚类实操和解析,一看就会哦
R数据分析:R Markdown:数据分析过程报告利器,你必须得学呀
R数据分析:倾向性评分匹配实例操作
R数据分析:ROC曲线与模型评价实例
R数据分析:双分类变量的交互作用作图
R数据分析:如何用R语言做meta分析,写给小白
R数据分析:非专业解说潜变量增长模型
R数据分析:竞争风险模型的做法和解释
R数据分析:竞争风险模型的做法和解释二
R数据分析:资料缺失值的常见处理方法
R数据分析:多水平模型详细说明
R数据分析:逻辑斯蒂回归与泊松回归
R数据分析:结构方程模型(SEM)介绍
R数据分析:一般线性回归的做法和解释
R数据分析:双因素方差分析与交互作用检验
R数据分析:再写潜在类别分析LCA的做法与解释
R数据分析:如何绘制回归分析结果的森林图
R数据分析:嵌套数据分析为什么要用加随机效应?终于解释清楚了
R数据分析:自我报告的身高数据的离群值探索
R数据分析:倾向性评分匹配完整实例(R实现)
R数据分析:如何用lavaan包做结构方程模型,实例解析
R数据分析:再写stargazer包,如何输出漂亮的表格
R数据分析:如何用R做多重插补,实例操练
R数据分析:如何用mice做多重插补,实例解析
R数据分析:广义估计方程式GEE的做法和解释
R数据分析:交互作用的简单斜率图做法及解释
R数据分析:何为Tidy data,它又有什么好处
R数据分析:如何理解模型中的“控制”,图例展示
R数据分析:如何计算问卷的聚合效度,实例操练