Yolov5使用Goole Colab训练VOC2007数据集
本实验在Goole Colab上实现,pytorch在Colab上已经提前配置完毕,无需安装pytorch
Colab官网:https://colab.research.google.com/
本文使用的模型是yolov5-5.0
自己第一次写博客,有错误欢迎大家指正
1、下载VOC数据集
镜像网站Pascal VOC Dataset Mirror推荐使用迅雷下载

下载图中的两个数据集,压缩以后将两个文件夹合并在一起
在JPEGImages中存放原图
在Annotations中存放xml格式的标签文件,每个xml文件对应JPEGImages的一张图片
在ImageSets的Main文件夹下存放train.txt、val.txt 、trainval.txt、test.txt。分别存放的是训练集、验证集、训练集加验证集、测试集的图片名称,只包含名称不包含后缀和路径。这四个文件需要使用脚本class.py生成。注:运行转换脚本先不在本地运行,我们等上传Colab之后再运行

2、下载Yolo模型
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
在本文中采用的下载到本地模型然后再有本地上传到Colab上面,并创建covert.py和class.py
class.py
由于VOC数据集标注文件是xml格式,我们需要转换成YOLO格式(.txt),在本地运行class.py,并将生成的lables文件复制到VOC2007中的JPEGImages文件夹中
covert.py
同时也需要划分train.txt、val.txt、test.txt、trainval.txt
在Colab中运行covert.py否则会出现路径错误,因为本地路径和云端路径还是有差距的。
class.py
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
sets = ['train', 'val', 'test'] # 如果你的Main文件夹没有test.txt,就删掉'test'
# classes = ["a", "b"] # 改成自己的类别,VOC数据集有以下20类别
classes = ["aeroplane", 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(abs_path + '/VOCdevkit/VOC2007/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(abs_path + '/VOCdevkit/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists(abs_path + '/VOCdevkit/VOC2007/labels/'):
os.makedirs(abs_path + '/VOCdevkit/VOC2007/labels/')
image_ids = open(abs_path + '/VOCdevkit/VOC2007/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open(abs_path + '/VOCdevkit/VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/VOCdevkit/VOC2007/JPEGImages/%s.jpg\n' % (image_id)) # 要么自己补全路径,只写一半可能会报错
convert_annotation(image_id)
list_file.close()
covert.py
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='VOCdevkit/VOC2007/Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='VOCdevkit/VOC2007/ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.8 # 训练+验证集一共所占的比例为0.8(注意看清楚),剩下的0.2就是测试集
train_percent = 0.8 # 训练集在训练集和验证集总集合中占的比例(注意看清楚是谁占谁的比例),可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
3、将数据集和模型上传到Google Drive

4、打开Colab
(1)环境配置
点击修改→笔记本设置,选择GPU加速

(2)连接Google Drive
使用指令
from google.colab import drive
drive.mount('/content/gdrive')
或者点击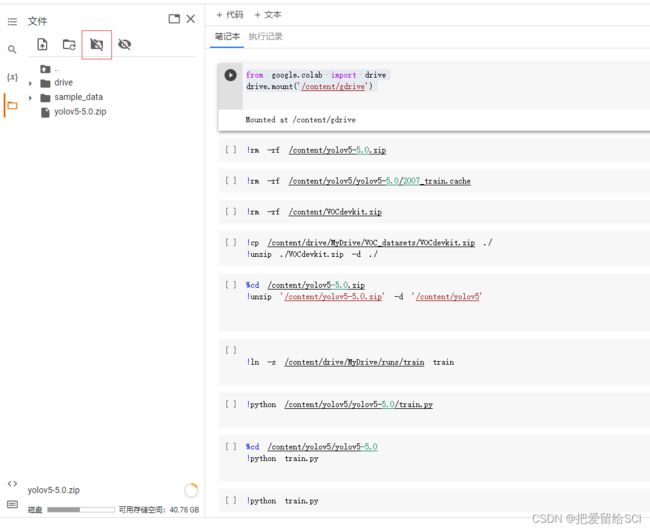
(3)解压上传的yolov5模型
!cp /content/drive/MyDrive/yolov5-5.0.zip ./
!unzip ./yolov5-5.0.zip -d ./(4)解压上传的模型
%cd /content/yolov5-5.0.zip
!unzip '/content/yolov5-5.0.zip' -d '/content/yolov5
(5)将数据集下载到模型中并解压
!cp /content/drive/MyDrive/VOC_datasets/VOCdevkit.zip ./
!unzip ./VOCdevkit.zip -d ./删除多余的压缩包
!rm /content/yolov5-5.0.zip /content/VOCdevkit.zip(6)运行covert.py脚本
生成train.txt、val.txt、test.txt、trainval.txt
如果在本地运行的话在训练的时候会出现路径错误的问题,因为此时的路径是这样的

运行的话会出现如下错误

因此我们需要在Colab上运行covert.py文件
生成于Colab相对应的路径

(7)修改VOC.yaml文件
主要是修改nc的种类以及train和val的位置
修改后的文件如图
(8) 修改yolov5s.yaml文件

5、开始训练
%cd /content/yolov5-5.0
!python train.py此时会出现的错误
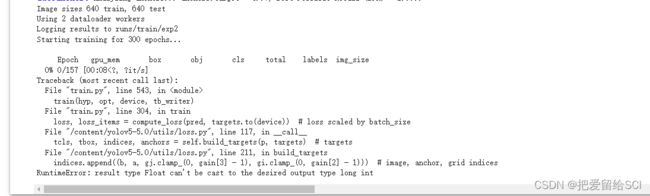 解决方法详:
解决方法详:
修改【utils】中的【loss.py】里面的两处内容
1.打开你的【utils】文件下的【loss.py】
2.按【Ctrl】+【F】打开搜索功能,输入【for i in range(self.nl)】找到下面的一行内容并替换为: 
anchors, shape = self.anchors[i], p[i].shape 3.按【Ctrl】+【F】打开搜索功能,输入【indices.append】找到下面的一行内容并替换为:

indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid然后在运行train.py

欢迎大家指正
2022.8.31