使用python 通过接口爬取图书网站数据
一、前言
爬取数据的方式有两种,一种是通过模拟浏览器操作(前两篇已经介绍过使用playwright爬数据),另一种是通过接口,今天我们将如何通过接口爬取图书网站书籍基本信息。
今天以图书网站:https://spa5.scrape.center/为例,讲一讲。
OK,let's go
上代码
import json
import pandas as pd
import requests
# 取多少条数据
booklimit = 18
# 从第几页取
bookpage = 1
# 请求地址
url = 'https://spa5.scrape.center/api/book/?limit='+str(booklimit)+'&offset='+ str(bookpage*18)
# 请求头
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
# 通过地址,请求头发送get请求
r = requests.get(url,headers=headers)
text = r.text
data = json.loads(text)
print(data)
items = data['results']
# print(items)
# print(list(items))
# 将字典类型转换为DataFrame类型
pf =pd.DataFrame(list(items))
print(pf)
# 指定字段顺序
order = ['id','name','authors','cover','score']
pf = pf[order]
# print(pf)
# 将列名替换为中文
columns_map = {
'id':'id',
'name':'姓名',
'authors':'作者',
'cover':'链接',
'score':'评分'
}
pf.rename(columns = columns_map,inplace=True)
# 指定生成的Excel表格名称
file_path = pd.ExcelWriter('name.xlsx')
#输出
pf.to_excel(file_path, encoding='utf-8', index=False)
#保存表格
file_path.save()
二、代码分析
1.既然是通过接口爬取数据,当然是要找到接口啦
①找到需要爬取数据的网页,以chromium浏览器为例,F12进去开发者模式中,寻找network(网络)这一栏可查看请求地址,URL,响应状态码(Status),响应数据类型(Type)等,没有内容的话可以刷新页面试试,在Type中寻找xhr(一般的动态数据是放在这里的)
第一页数据
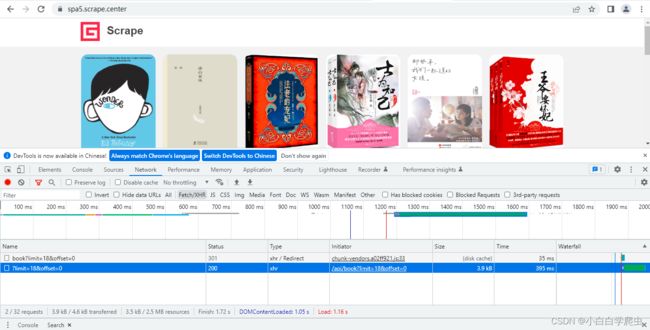
加载页面时,页面的所有信息都会显示在netword中,但我们只关注xhr信息,可以在F12导航栏中点击Fetch/XHR更直观查找,单击Type为xhr的文件即可显示当前页的请求信息,双击即可查看当前页以json保存的所有数据
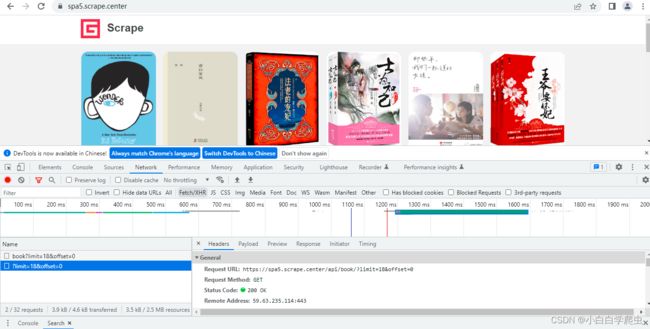 单机效果
单机效果
第一页数据如下所示
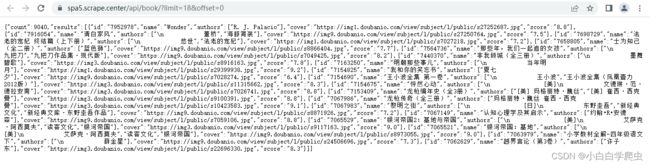 双击效果
双击效果
count只是显示当前网站总数据量,具体每页的数据都放在result中
单机效果图中左边General中找到Request URL也就是接口,再往下翻Request Head中寻找‘User-Agent',后面用得到
https://spa5.scrape.center/api/book/?limit=18&offset=0 https://spa5.scrape.center/api/book/?limit=18&offset=0
https://spa5.scrape.center/api/book/?limit=18&offset=0
接着点击下一页,查看第二页数据
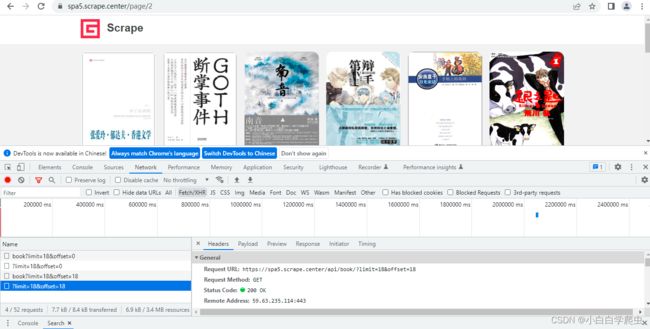
第二页只需要看接口就好,https://spa5.scrape.center/api/book/?limit=18&offset=18https://spa5.scrape.center/api/book/?limit=18&offset=18 观察这两个请求路径,其余信息都是一样,只有limit=x&offset=y不同,
路径中?的意思是先进入?前的网址,在对?后的内容进行查询
2、找到接口后,对接口进行分析
分析一下,在请求路径中,limit=18意思是当前页只加载18个数据,假设一共有n页,每页有18个数据,offset意思是,显示第18*(n-1)页的数据,有点绕
举个例子,第一页的offset为18*(1-1)=0,第二页的offset为18*(2-1)=18,第三页的offset为36,以此类推。。。
接口分析结束,回到代码查看如何实现
导入的包后面用到说,
①通过get请求路径(接口)和请求头中的信息,来定位要获取的具体位置。
请求头中User-Agent的信息记录的是自己主机的一些基本信息,简称UA。这里使用的是requests库,text就是双击效果图中的内容,json.loads(text),是将json字符串转换为字典类型,可以打印出来自己看看
import json
import pandas as pd
import requests
# 取多少条数据
booklimit = 18
# 从第几页取
bookpage = 1
# 请求地址
url = 'https://spa5.scrape.center/api/book/?limit='+str(booklimit)+'&offset='+ str(bookpage*18)
# 请求头
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
# 通过地址,请求头发送get请求
r = requests.get(url,headers=headers)
text = r.text
data = json.loads(text)
print(data)②获取字典中的数据
将当前页的所有数据转为字典后,字典以KV键值对存储,查看data时发现数据都保存在result键中,data['result']即可,可以自己打印出来看看qi
③将数据自动生成列表
将获取到的数据转换为list类型,pd.DataFrame()将获取到的数据自动生成一个表格,pd是pandas的缩写,为数据分析器
items = data['results']
# print(items)
# print(list(items))
# 将字典类型转换为DataFrame类型
pf =pd.DataFrame(list(items))
print(pf)
# 指定字段顺序
# order = ['id','name','authors','cover','score']
# pf = pf[order]
# print(pf)
④修改表头
如果items中的数据是以KV存储的,则可以不设置表头,DataFrame()会默认将K作为表头,因为我是想把表头设置为中文,所以这里我还是自己将表头放在列表中,其实不用也可以。我已经注释掉了
注意,字典中的键是上面,这个就是上面,不要写错,按顺序来(不写也行,我发现不屑也可以修改默认的表头)
# 将列名替换为中文
columns_map = {
'id':'id',
'name':'姓名',
'authors':'作者',
'cover':'链接',
'score':'评分'
}
pf.rename(columns = columns_map,inplace=True)⑤将数据保存至excel表中,并保存
# 指定生成的Excel表格名称
file_path = pd.ExcelWriter('name.xlsx')
#将数据写入excel中
pf.to_excel(file_path, encoding='utf-8', index=False)
#保存表格
file_path.save()三、总结
本案例较为简单,可以简单了解如何利用接口,如何分析接口,为以后学习更深层次知识打下基础。后续会继续更新,敬请期待。