python csv库使用教程
python csv库使用教程
- 前言
- csv库概览
- 读取数据
-
- csv.reader
- csv.DictReader
- 写入数据
-
- csv.writer
- csv.DictWriter
- 其他内容
-
- 使用Dialect自定义csv格式
- 其他函数和变量
前言
CSV,Comma-Separated Values,中文名为逗号分隔值,其文件以纯文本形式存储表格数据(数字和文本)。CSV是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。csv文件可以用excel或者记事本打开。
Python内置了专用于处理csv文件的库,名为:csv。这个库不用pip install,直接import就好。关于csv库使用最好的教程其实就是官网csv教程,不过官网的教程过于晦涩难懂,对新手及其不友好。英文版的文档虽然详细准确但是大多数小伙伴的英语可能并不好,中文版的文档由于翻译的原因又不太“原汁原味”,歧义较多。本教程是我在阅读完官方文档后,并参考其他文章,最后整理出的教程,希望能给想学csv库使用的小伙伴一个参考。
csv库概览
csv 库常用的对象:
csv.reader:从csv文件读取数据,返回listcsv.writer:往csv文件写入数据,需要传入listcsv.DictReader:从csv文件读取数据,返回dictcsv.DictWriter:往csv文件写入数据,需要传入dictcsv.Dialect:指定csv文件的解析格式,可以利用它自定义csv格式
读取数据
csv.reader
reader(csvfile, dialect='excel', **fmtparams)
下面是我用vscode写代码时,悬浮窗给的提示,感觉比官网的详细。

参数说明:
csvfile,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象,如果是文件对象,打开时需要指定newline=''(但是实际上不指定似乎也没影响,只有写入时才需要指定,不过官方文档建议,为了安全,还是指定比较好)。dialect,编码风格,默认为excel的风格,也就是用逗号,分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册,下文会提到。delimiter:str = ",",内容分隔符,默认是英文逗号。quotechar:指定引用使用到的字符,这个参数似乎跟quoting一起使用。escapechar:转义字符,对于writer,在 quoting 设置为 QUOTE_NONE 的情况下转义delimiter(定界符),在 doublequote 设置为 False 的情况下转义 quotechar。对于reader,去除其后所跟字符的任何特殊含义。quoting:指定引用方式。该属性可以等于任何 QUOTE_* 常量,
从csv文件读取的每一行数据都会以list的形式返回,这个list的元素都是string。csv库不会自动识别数字,除非指定quoting= QUOTE_NONNUMERIC。
从csv文件读取的每一行数据都会以list的形式返回,这个list的元素都是string。csv库不会自动识别数字,除非指定quoting= QUOTE_NONNUMERIC。
示例:
csv原文件:
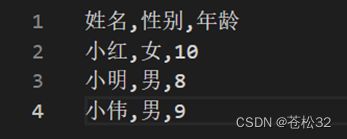
with open(filename,"r",encoding="utf-8") as file1:
reader=csv.reader(file1)
header=next(reader)
# 获取标题
title1=header[0]
title2=header[1]
title3=header[2]
for row in reader:
# row是一个列表,csv文件中以逗号分割的数据就是列表的每个元素
print("{}:{},{}:{},{}:{}".format(title1,row[0],
title2,row[1],title3,row[2]))
输出:

注意,使用withopen打开文件的时候,编码方式会默认采用系统默认的编码(很多情况下是gbk),所以为了不出错还是指定utf-8比较好。
看另一个例子:

with open('test.csv','r',encoding='utf-8',newline='') as f:
reader=csv.reader(f,quotechar="|",quoting=csv.QUOTE_NONNUMERIC)
for row in reader:
print(row)
输出:
['a', 1.0]
['b', 2.0]
['c', 3.0]
['d', 4.0]
可见指定quotechar和quoting后,没有被引用的数组数据都被转化成了float,而被引用的数据都去除了quotechar,quotechar夹着的内容也是string。
补充:官网定义的一些常量:
csv 模块定义了以下常量:
csv.QUOTE_ALL
指示 writer 对象给所有字段加上引号。csv.QUOTE_MINIMAL
指示 writer 对象仅为包含特殊字符(例如 定界符、引号字符 或 行结束符 中的任何字符)的字段加上引号。csv.QUOTE_NONNUMERIC
指示 writer 对象为所有非数字字段加上引号。
指示 reader 将所有未用引号引出的字段转换为 float 类型。csv.QUOTE_NONE
指示 writer 对象不使用引号引出字段。当 定界符 出现在输出数据中时,其前面应该有 转义符。如果未设置 转义符,则遇到任何需要转义的字符时,writer 都会抛出 Error 异常。
指示 reader 不对引号字符进行特殊处理。
csv.DictReader
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)
参数详解:
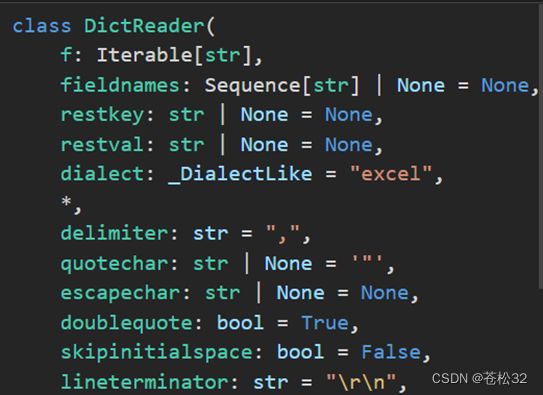

和csv.reader一样读取数据,但是会把每行映射到一个dict,dict的键由fieldnames指定。
fieldnames:字典的键,其实就是表格的header,必须是一个Sequence,如果忽略,文件的第一行会被当做header。restkey:如果header的个数小于data的列数,每行剩余列的data会被放入一个list中,键会被指定为restkey(defaultNone)restval: 若header的个数大于数据列数,则缺失值都会被填充为restval(defaultNone)。
不管是csv.reader还是csv.DictReader,都有一个__next__()方法,将下一行内容用Dialect解析后,以list或者dict的形式返回。
示例:
csv原文件:
with open(filename,"r",encoding="utf-8") as file1:
reader=csv.DictReader(file1)
for row in reader:
# row是一个字典
print(row)
结果:

默认把第一行作为标题了。
另一个示例:

with open('named csv.csv','r',encoding='utf-8',newline='') as file3:
dictreader=csv.DictReader(file3)
for row in dictreader:
print(row)
输出:
{'身高': '170', '体重': '60', '年龄': '20', None: ['1', '1']}
{'身高': '175', '体重': '65', '年龄': '25', None: ['2', '2']}
{'身高': '180', '体重': '70', '年龄': '30', None: ['3', '3']}
写入数据
csv.writer
writer(csvfile, dialect=‘excel’, **fmtparams)
参数详解:

csvfile可以是任意一个定义了write方法的对象。
delimiter:指定分隔符,默认是英文逗号。
值得注意的是,在写入时一定要指定newline='',否则写入时每两行之间都会多出一个空行。
其他参数跟reader一样。
示例:
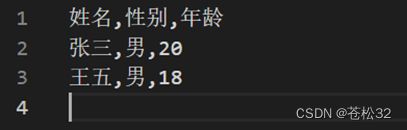
with open(filename,"w",encoding="utf-8",newline="") as file1:
# 以写方式打开文件。注意添加 newline="",否则会在两行数据之间都插入一行空白。
writer=csv.writer(file1)
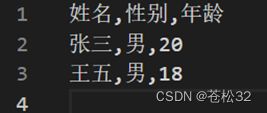
headers=["姓名","性别","年龄"]
data=[["张三","男","20"],["王五","男","18"]]
writer.writerow(headers)
# 方式一
writer.writerows(data)
# 方式二
# for row in data:
# writer.writerow(row)
结果:
csv.DictWriter
class csv.DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, **kwds)
参数详解:
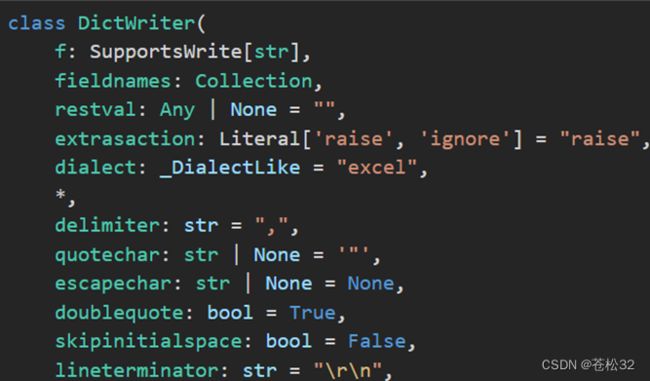

fieldnames就是需要传入的列名,这些列名需要作为DictWriter的writerow方法传入的字典的键。restval如果传入的字典缺失了某些键,则缺失值会用restval填充。extrasaction如果传入的字典多了一些键不在fieldnames里面,extrasaction就派上用场了。默认为'raise',即raise ValueError。若为'ignore',则直接忽略多余的键值对。
注意,DictReader的fieldnames是可选的,如果不传入,就默认以第一行作为fieldnames,但是DictWriter的fieldnames参数是必须的。
示例:
with open(filename,"w",encoding="utf-8",newline="") as file1:
# 以写方式打开文件。注意添加 newline="",否则会在两行数据之间都插入一行空白。
headers=["姓名","性别","年龄"]
# 即使打乱键的顺序,写入也不会出错
data=[{"年龄":"20","性别":"男","姓名":"张三"},{"姓名":"王五","性别":"男","年龄":"18"}]
# 将header作为参数传入
writer=csv.DictWriter(file1,headers)
writer.writeheader()
# # 方式一
# writer.writerows(data)
# 方式二
for row in data:
writer.writerow(row)
结果:
总结writer的方法:
csvwriter.writerow(row)
将 row 形参(被dialect格式化后)写入到 writer 的文件对象中,一次写入一行。csvwriter.writerows(rows)
rows是一个以上述row作为元素的迭代器。一次写入多行。
其他内容
使用Dialect自定义csv格式
class csv.Dialect
Dialect 类是一个容器类,其属性包含有如何处理双引号、空白符、分隔符等的信息。 由于缺少严格的 CSV 规格描述,不同的应用程序会产生略有差别的 CSV 数据。 Dialect 实例定义了 reader 和 writer 实例将具有怎样的行为。
借助Dialect类,我们可以自定义csv文件格式,即我们的文件可以不是标准的csv格式,但是使用csv库也可以读取、写入文件内容。关于所有定义好的dialect,他们的名字可以使用csv.list_dialects()函数获取。
Dialect 类支持以下属性:
-
Dialect.delimiter
一个用于分隔字段的单字符,默认为','。 -
Dialect.doublequote
控制出现在字段中的 引号字符 本身应如何被引出。当该属性为 True 时,双写引号字符。如果该属性为 False,则在 引号字符 的前面放置 转义符。默认值为 True。
在输出时,如果 doublequote 是 False,且 转义符 未指定,且在字段中发现 引号字符 时,会抛出 Error 异常。 -
Dialect.escapechar
一个用于 writer 的单字符,用来在 quoting 设置为 QUOTE_NONE 的情况下转义 定界符,在 doublequote 设置为 False 的情况下转义 引号字符。在读取时,escapechar 去除了其后所跟字符的任何特殊含义。该属性默认为 None,表示禁用转义。 -
Dialect.lineterminator
放在 writer 产生的行的结尾,默认为'\r\n'。
备注 reader 经过硬编码,会识别 ‘\r’ 或 ‘\n’ 作为行尾,并忽略lineterminator。 -
Dialect.quotechar
一个单字符,用于包住含有特殊字符的字段,特殊字符如 定界符 或 引号字符 或换行符。默认为 ‘"’。 -
Dialect.quoting
控制 writer 何时生成引号,以及 reader 何时识别引号。该属性可以等于任何QUOTE_*常量,默认为QUOTE_MINIMAL。 -
Dialect.skipinitialspace
如果为True,则delimiter后的空格会被忽略。默认为False。 -
Dialect.strict
如果为 True,则在输入错误的 CSV 时抛出 Error 异常。默认值为 False。
实例:
# 自定义Dialect
class myDialect(csv.Dialect):
delimiter = '#' # 自定义分隔符为#
quotechar = '"' # 用双引号引用
escapechar = None # 无转移字符
doublequote = True # 前后都要加双引号
skipinitialspace = True # 跳过delimiter后的空格
lineterminator = '\r\n' # 不知道具体原理,照着csv库源代码的excel格式写的
quoting = csv.QUOTE_NONNUMERIC # 非数字类型的数据加上引号
csv.register_dialect('my_dialect',myDialect) # 将名字加入到注册表中
with open('my customized csv.csv','w',encoding='utf-8',newline='') as f:
headers=['姓名','语文','数学','英语']
mywriter=csv.DictWriter(f,fieldnames=headers,dialect='my_dialect')
data=[{'姓名':'小红','语文':100,'数学':99,'英语':80},
{'姓名':'小明','语文':90,'数学':100,'英语':95},
{'姓名':'小刚','语文':95,'数学':95,'英语':90}]
mywriter.writeheader()
mywriter.writerows(data)
写入文件内容:
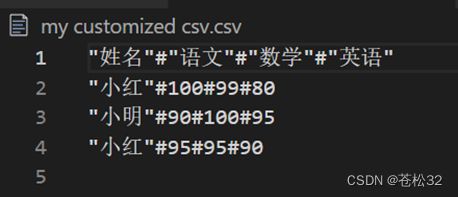
可以看出,确实按照我自定义的格式写入了。所以大家以后在按照某种特定格式写入文件时,可以尝试一下自定义dialect!但是更复杂的格式,估计只能靠万能的字符串格式化了。
其他函数和变量
csv.list_dialects()-> list[str]
返回目前已经定义好的dialect的名字。
print(csv.list_dialects()) # ['excel', 'excel-tab', 'unix']
csv.register_dialect(name[, dialect[, **fmtparams]])
将dialect起名为name,添加到注册表中。
csv.unregister_dialect(name)
从注册表删除名字为name的dialect。
csv.get_dialect(name)
获取名字为name的dialect。
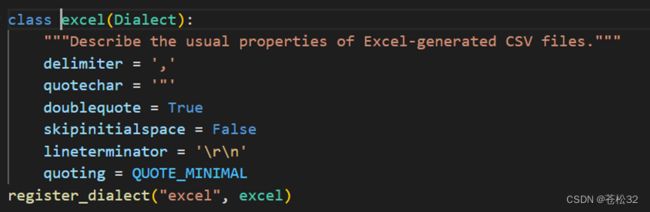
class csv.excel
excel 类定义了 Excel 生成的 CSV 文件的常规属性。它在注册表中的名称是 'excel'。
csv库源代码内容:
class csv.excel_tab
excel_tab 类定义了 Excel 生成的、制表符分隔的 CSV 文件的常规属性。它在注册表中的名称是 'excel-tab'。
class csv.unix_dialect
unix_dialect 类定义了在 UNIX 系统上生成的 CSV 文件的常规属性,即使用'\n'作为换行符,且所有字段都有引号包围。它在注册表中的名称是 'unix'

class csv.Sniffer
Sniffer 类用于推断 CSV 文件的格式。
Sniffer 类提供了两个方法:
sniff(sample, delimiters=None)
分析给定的 sample 并返回一个 Dialect 子类,该子类中包含了分析出的格式参数。如果给出可选的 delimiters 参数,则该参数会被解释为字符串,该字符串包含了可能的有效定界符。
has_header(sample)
分析 sample 文本(假定为 CSV 格式),如果发现其首行为一组列标题则返回 True。 在检查每一列时,将考虑是否满足两个关键标准之一来估计 sample 是否包含标题:
第二至第 n 行包含数字值
第二至第 n 行包含字符串值,其中至少有一个值的长度与该列预期标题的长度不同。
会对第一行之后的二十行进行采样;如果有超过一半的列 + 行符合标准,则返回 True。