redis三种集群模式
一、单机模式
就是安装一个redis,启动起来,业务调用即可
有什么问题?
- 单机故障
- 容量瓶颈
- QPS瓶颈
只适合一些性能不高、可靠性不用太强的业务系统。
二、主从复制模式

可以解决单机模式的单机故障问题外,还有好处:
- 读写分离
- 容灾备份
假设我们要搭建1主2从,分别是6379、6380、6381端口

6379主节点redis.conf配置文件不需要动,只把6380、6381两个从节点redis.conf配置文件增加一行(配置主节点的ip端口)
slaveof 127.0.0.1 6379
或
replicaof 127.0.0.1 6379(redis5.0之后)或是使用执行 SLAVEOF host port 命令,可以动态将当前服务器转变为指定服务器的从属服务器(slave server)。使用SLAVEOF NO ONE命令关闭复制功能
启动顺序:先启动6379主节点,再启动从节点。启动命令:./redis-server ../conf/redis.conf
启动完主节点,当启动从节点时,从日志中可以发现,6380已经连接并同步了6379主节点数据,如图:
再测试一下写入功能


可以发现主节点可以写,从节点不可写。但从节点可以读取到主节点写入的数据。
如果我们主节点挂掉之后,整个redis将会变为不可写。
如何查看redis主从复制模式中哪个是主节点?
执行redis-cli info 如图:

说明120.0.0.1:6381是主节点。其他redis是从节点
三、哨兵模式
主要用来完善主从复制模式下主节点故障之后不可写的问题。(只是在主从节点上增加了几个哨兵节点)
 (图有缺失,应该是哨兵会监控除自己外的所有节点(主、从、其他哨兵节点))
(图有缺失,应该是哨兵会监控除自己外的所有节点(主、从、其他哨兵节点))
在主从复制的基础上,哨兵模式(Redis 2.8之后)实现了自动化的故障恢复。缺点是写操作无法负载均衡,存储能力受到单机的限制。
工作原理:每个Sentinel以 每秒钟 一次的频率,向它所有的 主服务器、从服务器 以及其他Sentinel实例 发送一个PING 命令。
如果某实例没有在规定的时间(down-after-milliseconds)内相应,则会被标记为主观下线。如果有足够数量的哨兵在指定的时间范围内同意判断,则会被标记为客观下线。
哨兵会向客观下线的主节点所有的从节点每秒发送一次INFO命令。哨兵会和其他哨兵投票选出新的主节点,将剩余的从节点指向新的主节点进行数据复制。
缺点:在故障转移期间,redis服务不可用(几秒钟到10几秒)
基于上面的主从复制模式,我们再搭建三个哨兵节点,分别是26379、26380、26381端口
每个哨兵的sentinel.conf配置文件,都加下面代码(注意端口和日志别重复)
port 26379
#表示监控的主节点ip、端口 和判断下线需要2个哨兵都同意
sentinel monitor mymaster 127.0.0.1 6379 2
logfile "/root/redis6379/logs/sentinel.log"启动命令:./redis-sentinel ../conf/sentinel.conf(启动顺序无要求)
三个哨兵都启动后查看26379哨兵日志,发现已经开始监控6379主节点、两个从节点和其他两个哨兵节点了,如图:
这是所有的redis节点,包括1主2从和3个哨兵节点
测试主节点故障
停止6379主节点后,查看26379哨兵日志,新主节点已选举为6381节点,如图:

6381节点已变为可写状态。
当6379原主节点上线之后,会成为从节点。
故障迁移完毕!
四、集群模式
通过集群模式redis解决了写无法负载均衡,及存储能力受到单机限制的问题。(哨兵模式的升级版,解决故障转移期间,整个redis无法使用问题)
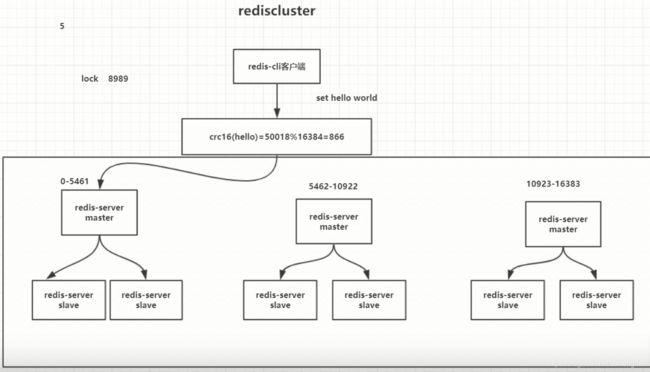
集群原理:通过数据分片的方式来进行数据共享。
数据分片方式:集群的键空间被分为16384个hash槽,通过如下算法将数据分到不同分片上:
HASH_SLOT = CRC16(key) & 16384 CRC16是一种循环校验算法。运用位运算&得到取模结果。
为什么是16384(2^14)个槽点?
CRC16算法产生的hash值有16bit,可以产生2^16=65536个值。为什不用65536要用16384?
- 因为redis集群内部每秒都在发送ping消息,如果槽位太多会导致心跳消息的消息头太大,浪费带宽
- redis主节点数量不建议超过1000个,也会导致心跳消息太大,网络拥堵。
如果有三个主节点,则hash槽被分成三段分别为:0-5461、5462-10922、10923-16383。
如果新增加一个主节点,槽需要重新分配,数据需要重新迁移,但服务不需要下线。重新分片需要使用redis-trib软件
redis-trib.rb使用:https://blog.csdn.net/huwei2003/article/details/50973967
cluster集群:https://www.cnblogs.com/cqming/p/11191079.html