项目中使用sharding-jdbc导致启动慢的解决办法
环境:springboot2.3.9.RELEASE + shardingsphere4.0.1 + Oracle
当连接oracle数据库的当前用户下表少的时候可能感觉不出来,当数据表很多时会导致服务启动超级慢,我项目中有200多张表,启动服务时非常的慢。
- 定位问题
通过debug调试,定位到
TableMetaDataInitializer.java这个类中的如下方法在启动服务时非常的耗时。
private Map loadDefaultTables(final ShardingRule shardingRule) throws SQLException {
Map result = new HashMap<>(shardingRule.getTableRules().size(), 1);
Optional actualDefaultDataSourceName = shardingRule.findActualDefaultDataSourceName();
if (actualDefaultDataSourceName.isPresent()) {
for (String each : getAllTableNames(actualDefaultDataSourceName.get())) {
result.put(each, tableMetaDataLoader.load(each, shardingRule));
}
}
return result;
} 这里的getAllTableNames方法是获取当前用户下的所有的表,然后一个一个地遍历去加载表的元信息。
tableMetaDataLoader.load(each, shardingRule); 这个方法就是用来加载表的元信息的。
- 解决办法
方案1:
不让其加载表的元信息,也就是将如下代码注释了:
/*for (String each : getAllTableNames(actualDefaultDataSourceName.get())) {
result.put(each, tableMetaDataLoader.load(each, shardingRule));
}*/我项目中是将这个代码注释了后,启动恢复了正常,同时使用的分表功能也是正常的;但是这样总感觉是有风险的(具体也没研究注释的那代码用处是什么)。至少在我们项目中将这代码注释了后确实也没有影响到系统分表的功能,一切正常。
方案2:
通过多线程的方式解决问题,在循环加载那,通过多线程来提高加载速度。
private static ThreadPoolExecutor executors = new ThreadPoolExecutor(20, 20, 60, TimeUnit.SECONDS, new ArrayBlockingQueue(10000)) ;
private static Logger logger = LoggerFactory.getLogger(TableMetaDataInitializer.class) ;
private Map loadDefaultTables(final ShardingRule shardingRule) throws Exception {
Map result = new ConcurrentHashMap<>(shardingRule.getTableRules().size(), 1);
Optional actualDefaultDataSourceName = shardingRule.findActualDefaultDataSourceName();
if (actualDefaultDataSourceName.isPresent()) {
Collection tables = getAllTableNames(actualDefaultDataSourceName.get()) ;
CountDownLatch cdl = new CountDownLatch(tables.size()) ;
logger.info("加载 {} 张表", tables.size());
for (String each : tables) {
executors.execute(() -> {
try {
result.put(each, tableMetaDataLoader.load(each, shardingRule));
logger.info("表 {} 元信息加载完成", each) ;
cdl.countDown() ;
} catch (SQLException e) {
cdl.countDown() ;
logger.error("加载 {} 元信息错误:{}", each, e) ;
}
});
}
cdl.await() ;
executors.shutdown() ;
}
return result;
} 这里通过线程池的方式来提高加载速度,同时为了是系统正常运行正常,这里通过CountDownLatch来保证所有的表元信息都加载完了后程序再继续运行。避免出现看着服务是启动完了,实际加载表信息还在执行中问题。
如果你使用的是这个版本shardingsphere4.1.1,那么可就没有这个类了(服务启动正常了),但是启动服务可能报如下错误:
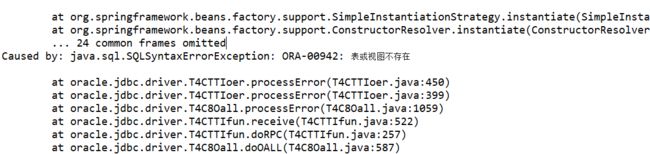
在我项目中出现上面错误时,做如下处理:
修改
org.apache.shardingsphere.sql.parser.binder.metadata.util.JdbcUtil.java这个类:
源代码:
public static String getSchema(final Connection connection, final String databaseType) {
String result = null;
try {
if ("Oracle".equals(databaseType)) {
return null;
}
result = connection.getSchema();
} catch (final SQLException ignore) {
}
return result;
}这里会将当前用户能访问到的所有表进行加载,修改如下只加载当前用户下的,不管其他用户表
public static String getSchema(final Connection connection, final String databaseType) {
String result = null;
try {
result = connection.getSchema();
} catch (final SQLException ignore) {
}
return result;
}如上修改完后,启动服务控制台输出如下:
![]()
非常的快了。
但是在我们项目中最终没有用这个版本,因为在我们的项目中使用这个版本后查询的数据全都是null,条数是对的,数据都是null,不知道为何!!!