python——selenium库定位方法
前言
1、selenium WebDeiver 是selenium2.0版本以后提供的一套用于实现功能自动化测试的框架
2、seleium Webdriver没有图形化界面,无法录制生成代码,但是功能很强大,借助于浏览器厂商预留的API来操作浏览器,还可以使用python或java等高级语言的语言来实现复杂逻辑的测试用例代码,使用单元测试框架来管理和批量运行,所有selenium Webdriver比selenium IDE更常用
3、seleium webdiver原理:浏览器厂商预留的API被各个浏览器的驱动程序调用,来实现浏览器里的操作,因为各个浏览器厂商预留的API不同,所以对应有各自的驱动程序,随着浏览器版本的升级,API可能会变化,所以启动程序文件可能也需要升级
安装webdriver驱动程序
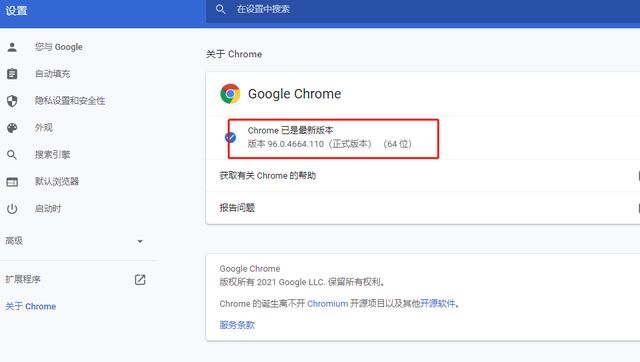
1、检查自己使用的浏览器对应的版本,我这里常用的是谷歌浏览器:96.0.4664.110(正式版本)
2、下载对应浏览器版本的谷歌WebDriver,没有版本对应的选择最相近的版本也可以
3、将下载好的驱动解压并放在python目录下
安装selenium
1、在线安装:cmd里面输入pip install selenium
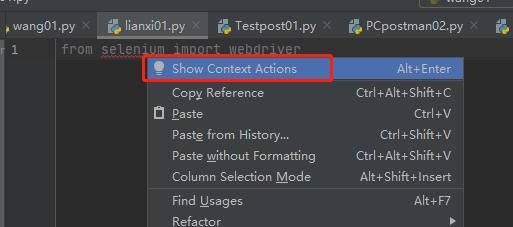
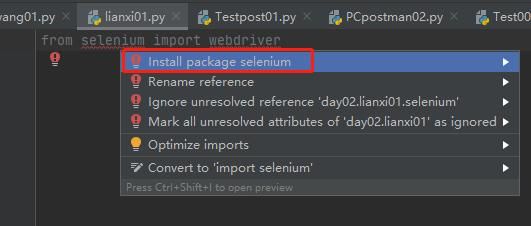
2、pycharm里面新建一个包,书写 from selenium import webdriver没有报错代表安装成功,如果报错点击右键选择“Shou Context Actions”-->“install package selenium”也可以进行安装
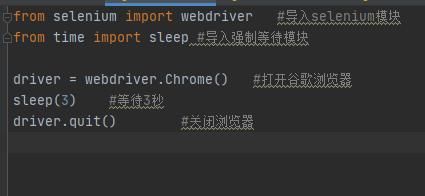
检查测试环境:
导入:from selenium import webdriver
启动浏览器:driver = webdriver.Chrome()
HTML基本语法
1、测试人员做自动化测试的两件事:定位元素、操作元素,为了调查元素如何定位,我们需要学习HTML基本语法,通过查看网页的HTML格式源代码来调查元素的定位条件
2、HTML:是超文本标记语言,一般以<>来表示元素,html网页文档以开始,以结束,包括头部分和体部分
(1)html头部分:以
开始,以结束,文档头部分包括(2)html体部分:以
开始,以计算,包括网页里的各个元素的信息3、标记:以<>来表示,也叫作标签,分为:
(1)单标记:<标记名称> --没有子节点
(2)双标记:<标记名称>xxxx --可能有子节点
4、标记的属性:在标记名称后,以xxx=yyy的形式出现的内容,等号左侧是属性名称,等号右侧是属性值。
<标记名称 属性名1=”属性值1” 属性名2=”属性值2”>属性名3=”属性值3” 属性名4>
定位元素的基本方法
1、 基本定位:id 、name、link text、partial link text、class name、tag name
2、 高级定位方法:xpath、css selector
3、 id定位:使用元素的id属性值来定位,最建议使用!
(1)语法格式:driver.find_element_by_id("id属性值"),
(2)语法格式:导入By后,driver.find_element(By.ID,'id属性值'),注意大写
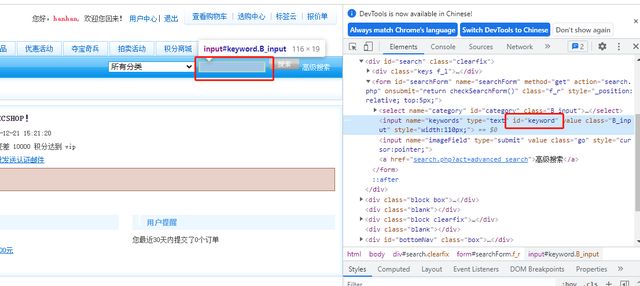
示例:(这里我使用ECshop电商平台演示)
定位关键字文本框,输入123,点击搜索操作
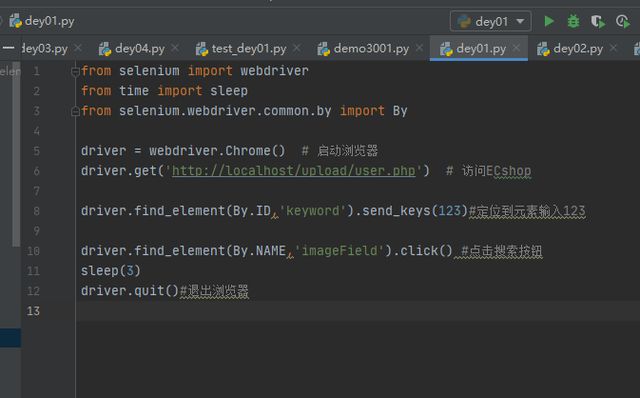
4、name定位:使用元素的name属性值来定位,也比较建议使用!
(1)语法格式:driver.find_element_by_name("name属性值"),
(2)语法格式:导入By后,driver.find_element(By.NAME,name属性值'),注意大写
实例:点击搜索按钮
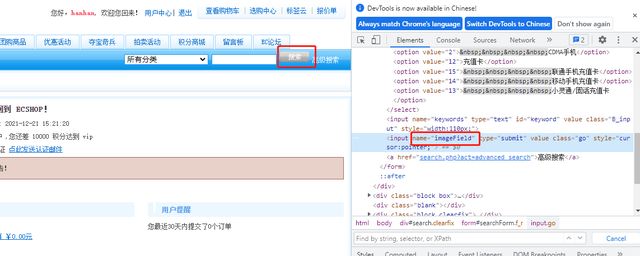
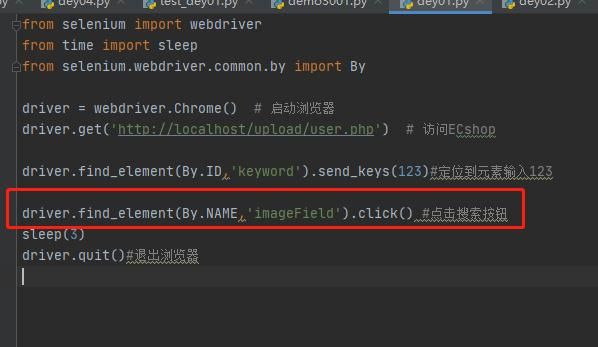
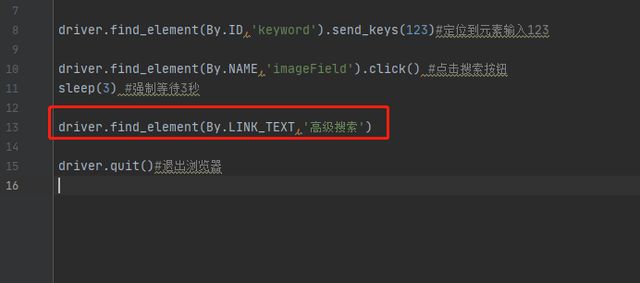
5、link text定位:用连接的全部文本定位超级链接类型的元素,说明:超级链接就是指HTML中标记名称是a的元素,此种定位方法只能定位有文本的超级链接(和之间必须有文本字符串),不能定位其它类型的元素
(1)语法格式:driver.find_element_by_link_text(“链接文本”)
(2)语法格式:导入By后,driver.find_element(By.LINK_TEXT,”链接文本”)
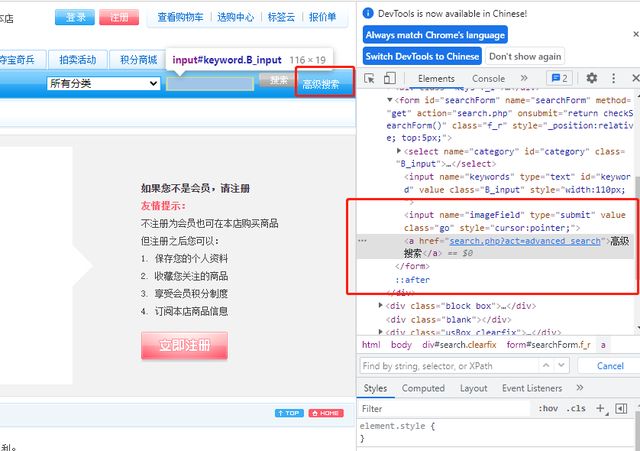
示例:点击高级搜索
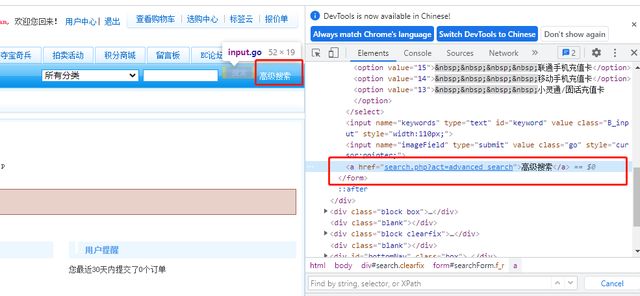
定位元素的高级方法之XPATH定位
1、xpath是在(xml路径语言)是在xml文档中使用路径表达查找节点或节点集合的一种技术,因为html可以被看成一个特殊的xml文档,所以我们可以使用xpath这种技术在网页里面查找页面元素,谷歌也可以自动生成xpath表达式
2、xpath定位的语法格式:
(1)语法格式:driver.find_element_by_xpath("xpath表达式")
(2)语法格式:导入By后,driver.find_element(By.XPATH,"xpath表达式")
注意:如果xpath表达式内部使用了单引号的话,那么该表达式外语为双引号,如果xpath表达书内部使用了双引号的话(“”),那么该表达式外语为单引号(‘’)
3、xpath表达式分类:
(1)绝对路径xpath:从根节点开始描述路径,不建议使用!
(2)相对路径xpath:从中间某层节点开始描述路径,以维护和管理,建议使用!
4、书写相对路径xpath:一般以 // 或 ./ 开头
(1)//后直接写目标节点的标记名称
示例:留言板里的第4个单选按钮(售后单选按钮)
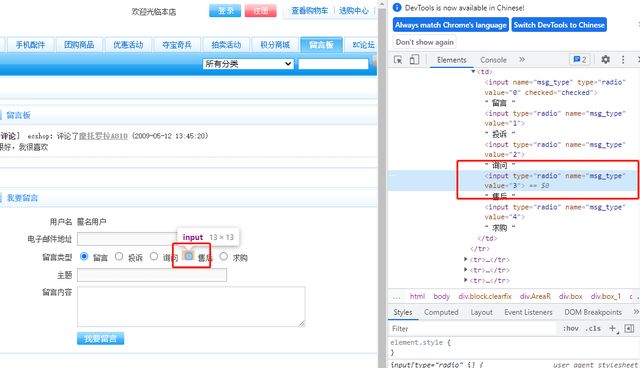
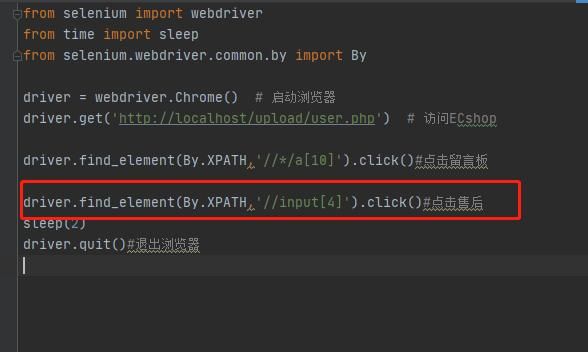
(2)如果直接找到目标节点,不唯一,可以从父节点开始写书写,如果加了父节点还是不唯一,那么可以继续加爷爷节点或更向前的节点,每层父子关系的节点之间都使用/分隔开
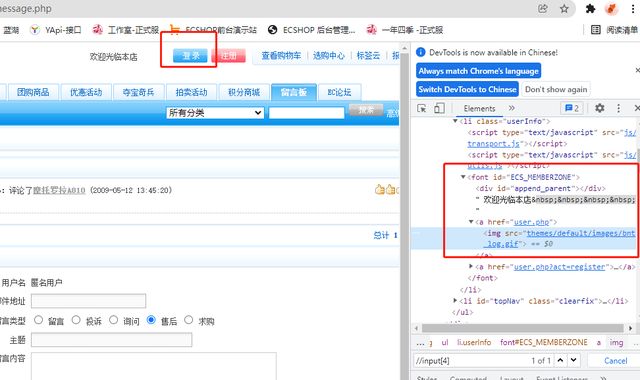
示例:点击登录图片
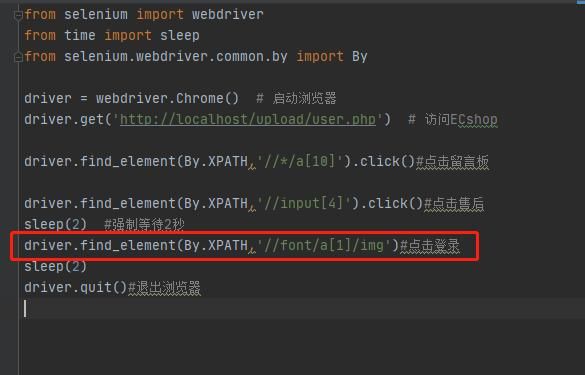
(3)在各层节点的标记名称后,都可以加筛选条件,xpath里把这样筛选条件成为“谓词”,使用[]来表示,其功能等价于SQL语句里的where子句。
示例:登录输入输入账号和密码
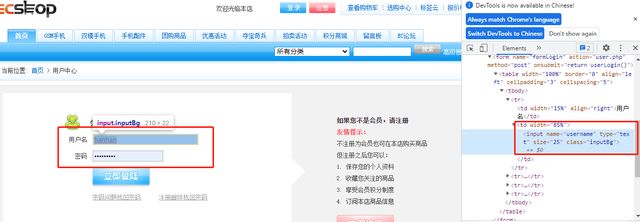
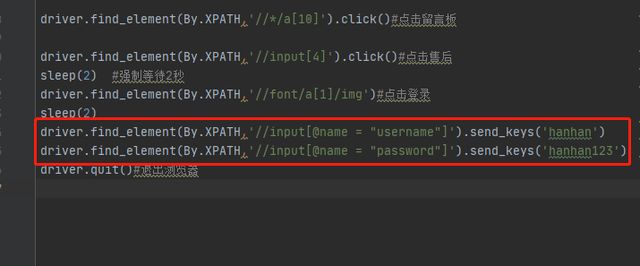
(4)通配符(*):好处是xpath更简短,缺点是可能不准确
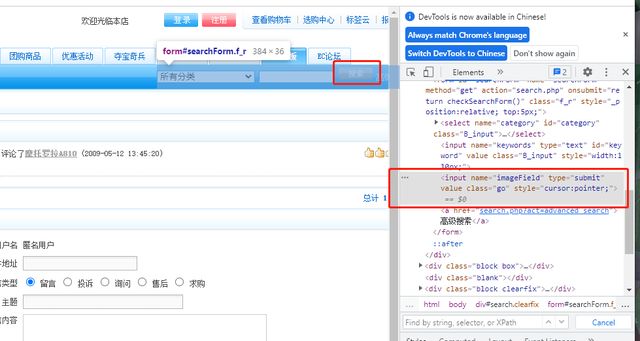
*写在/ 或 // 后,代表任意的标记名称
示例:搜索按钮
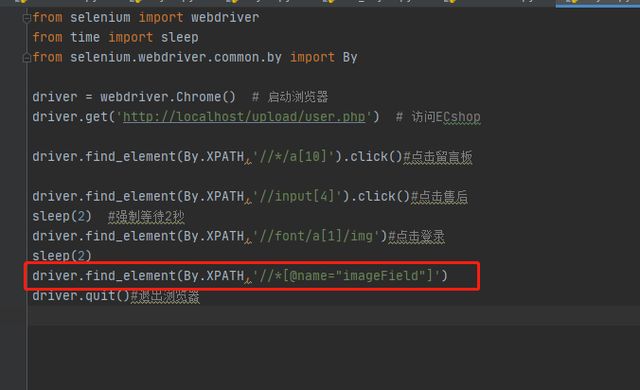
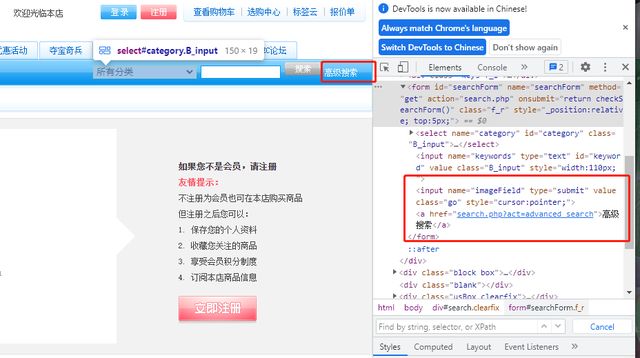
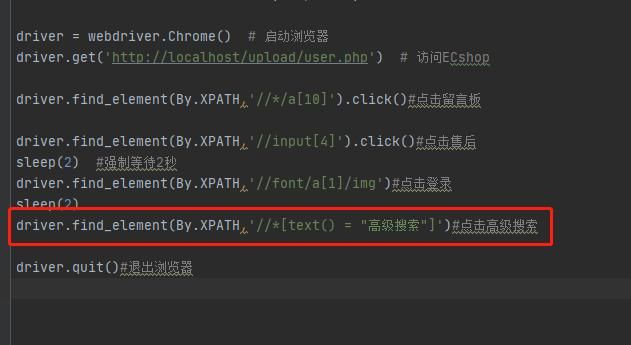
(5)text函数:无参,获得某元素的开始和结束标记之间的文本,返回值是一个字符串
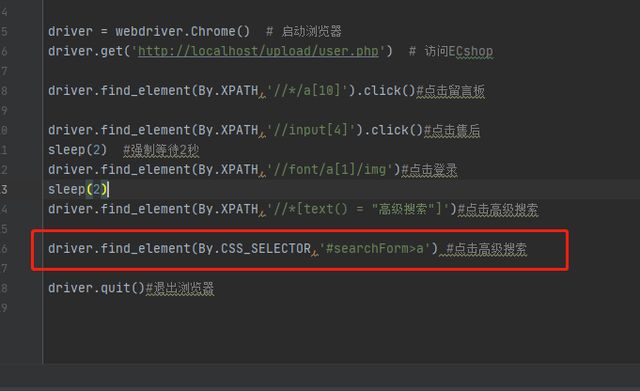
示例:点击高级搜索
定位元素的高级方法之css表达式
1、css是层叠式样式表,在 该技术中有一种Selecyor(选择器)技术,其中包含一些css表达式可以用于定位元素,其功能与xpath功能有重叠,所以建议了解此技术即可
2、使用css selector定位的语法格式
(1)语法格式:driver.find_element_by_css_selector(“css表达式”)
(2)语法格式:导入By后,driver.find_element(By.CSS_SELECTOR,”css表达式”
示例:点击高级搜索