情感分析实战(中文)-数据获取
情感分析实战(中文)-数据获取
背景:该专栏的目的是将自己做了N个情感分析的毕业设计的一个总结版,不仅自己可以在这次总结中,把自己过往的一些经验进行归纳,梳理,巩固自己的知识从而进一步提升,而帮助各大广大学子们,在碰到情感分析的毕业设计时,提供一个好的处理思路,让广大学子们能顺利毕业
情感分析实战:
a) 数据获取篇
b) 数据预处理篇-情感分类篇(中文版)
c) 数据预处理篇-情感分类篇(英文版)
d) 无监督学习机器学习聚类篇
e) LDA主题分析篇
f) 共现语义网络
目标网站 :马蜂窝(在这里声明一下该爬取数据仅用于学术研究,不对该网站造成任何攻击,各大网友在爬取的过程中,注意素质)
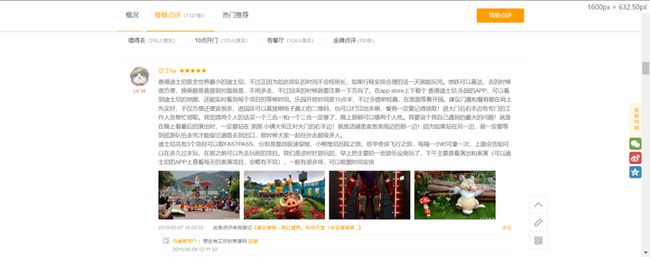
这里选择评论最多的迪士尼
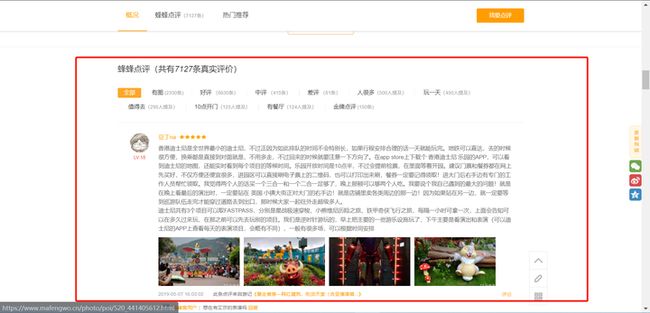
这里里面的评价便是我们所要获取的内容
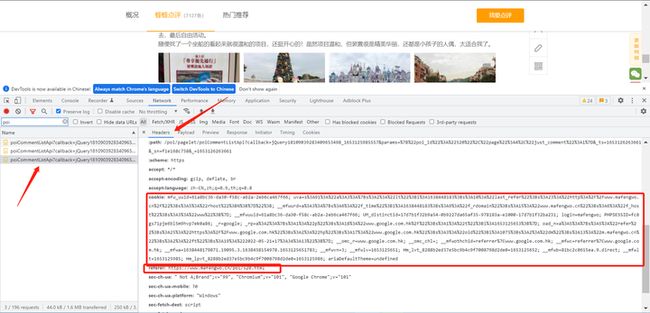
鼠标右键点击检查或者F12
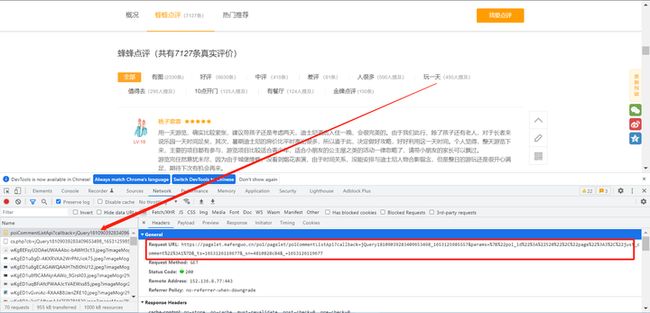
找到含有评论的API
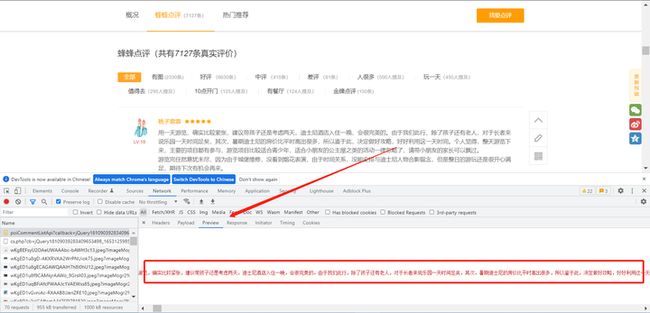
然后我们来寻找规律
https://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109039283409653498_1653125985557¶ms=%7B%22poi_id%22%3A%22520%22%2C%22page%22%3A3%2C%22just_comment%22%3A1%7D&_ts=1653126119677&_sn=4810828c84&_=1653126119677
https://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109039283409653498_1653125985557¶ms=%7B%22poi_id%22%3A%22520%22%2C%22page%22%3A4%2C%22just_comment%22%3A1%7D&_ts=1653126263661&_sn=f1e168c758&_=1653126263661
由这些我们可以看出,其实它们前面的构造都一样,只是在这几个地方不一样
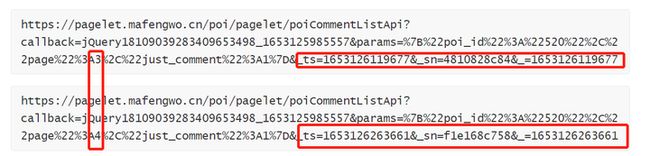
而其中A3和A4,这个就是代表的是评论的页数,3就是评论的第三页,4就是评论中的第四页
把这个链接的尾部砍掉
https://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109039283409653498_1653125985557¶ms=%7B%22poi_id%22%3A%22520%22%2C%22page%22%3A4%2C%22just_comment%22%3A1%7D&
然后把里面的试试看看能不能获取到内容,能的话说明尾部的这些并不重要
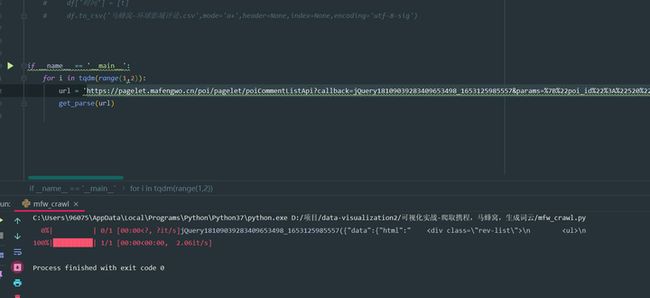
数据是可以成功获取到了,只是这些数据有些乱接下来我们就要开始整理我们的数据内容了,让这些数据转换,方便我们后续的获取
这里我们首先把一些无效数据给替换掉,方便后续我们对数据进行格式化
这里采用的是正则公式
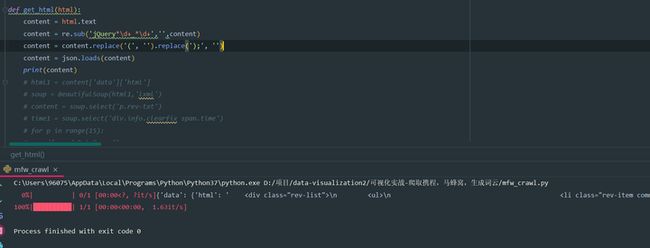
把刚刚前面的那一串jquery…的东西全部给替换掉了,把原来的json格式打印成python的格式,这里保持格式的一致化之后就能获取到中文内容了
然后再用bs4去内容进行定位,获取到时间和正文内容,这里打印一下看看
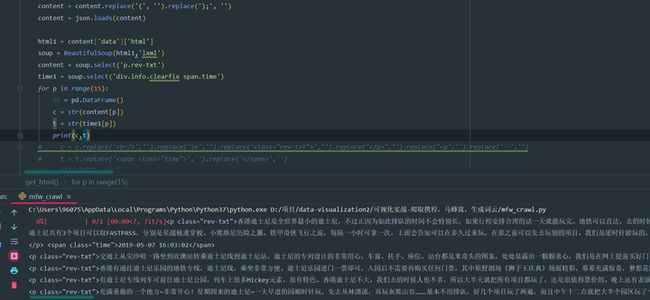
接着我们再对数据进行清洗,删掉文中HTML代码的部分,再用pandas把数据保存为CSV格式
c = c.replace('
','').replace('\n','').replace('class="rev-txt">','').replace('','').replace(','').replace('~','')
t = t.replace('','').replace('','')
最后看看效果
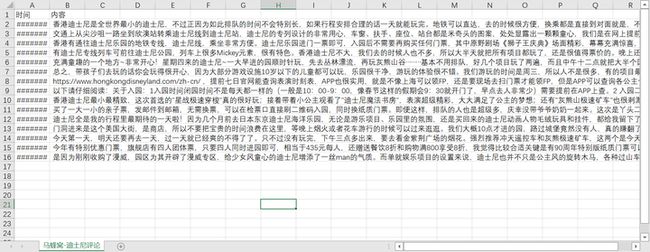
内容就这样获取好了,然后其他字段的话,根据自己的需要去添加对应的bs4定位法则即可,这里就不做过多的介绍了
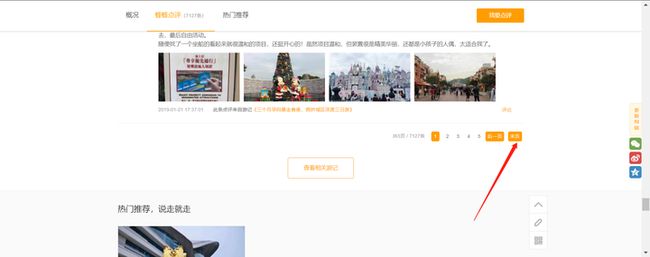
如果是获取多页的内容的话,那么写一个for循环即可,然后把上面提到数字的那个地方进行修改就好了,这样就获取多页内容,具体的尾页的话,需要大家自己去该网站点击末尾然后查看信息即可,再把相应的数字进行修改
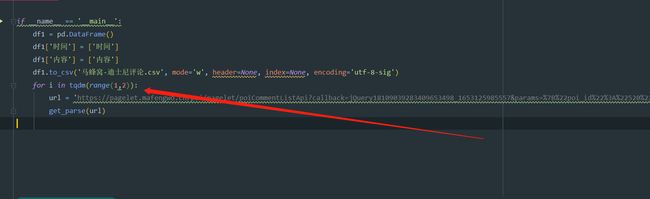
这里是源代码,具体需要的修改的是headers这个部分这里,记得替换成自己的cookie
import requests
import time
import json
import pandas as pd
from tqdm import tqdm
from bs4 import BeautifulSoup
import re
headers = {
#这里根据不同评论的内容,修改不同的URL
'referer': 'https://www.mafengwo.cn/poi/520.html',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36',
#这里换成你自己的
'cookie': 'xxx',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
}
def get_parse(url):
html = requests.get(url,headers=headers)
if html.status_code == 200:
get_html(html)
else:
print(html.status_code)
def get_html(html):
content = html.text
content = re.sub('jQuery*\d+_*\d+','',content)
content = content.replace('(', '').replace(');', '')
content = json.loads(content)
html1 = content['data']['html']
soup = BeautifulSoup(html1,'lxml')
content = soup.select('p.rev-txt')
time1 = soup.select('div.info.clearfix span.time')
for p in range(15):
df = pd.DataFrame()
c = str(content[p])
t = str(time1[p])
c = c.replace('
','').replace('\n','').replace('class="rev-txt">','').replace('','').replace('','').replace('','')
df['时间'] = [t]
df['内容'] = [c]
df.to_csv('马蜂窝-迪士尼评论.csv',mode='a+',header=None,index=None,encoding='utf-8-sig')
if __name__ == '__main__':
df1 = pd.DataFrame()
df1['时间'] = ['时间']
df1['内容'] = ['内容']
df1.to_csv('马蜂窝-迪士尼评论.csv', mode='w', header=None, index=None, encoding='utf-8-sig')
for i in tqdm(range(1,2)):
#这个URL记得改成自己想要爬取的网站的URL
url = 'https://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18109039283409653498_1653125985557¶ms=%7B%22poi_id%22%3A%22520%22%2C%22page%22%3A{}%2C%22just_comment%22%3A1%7D&'.format(i)
get_parse(url)
以上便是爬取马蜂窝的全部教程,这里再次申明一下,获取该网站的数据仅用于学术研究,不造成任何的商业行为,这里望各位注意素质,切勿对该网站的服务器造成攻击或者商业用途